
Orchestration Economics: Agentic AI Is in Production (Chapter 5)
What separates a powerful model from a production agentic system is the layer that coordinates: the protocols, memory, and orchestration. That layer moved from research to deployment in 18 months.


This is the latest excerpt from AGNT: The Orchestration Economics Manifesto - An Investment Framework for the Agentic Era. Each Thursday, I explore a major theme of the Manifesto and unpack the frameworks, adding extra context with more recent developments. Note: The figures and sequential references are taken directly from the larger Manifesto.
On December 29, 2025, Meta paid more than $2 billion for Manus. The acquisition puzzled many observers, who focused on whether the product represented a step toward artificial general intelligence. In March 2025, the Chinese startup released a product that briefly captured the AI industry's attention. The demo videos showed an AI system that could browse the web, write and execute code, manage files, and complete multi-step tasks autonomously.
It did not. Manus was built on top of Claude and Qwen, foundation models it had licensed from other companies. It had developed no new intelligence. It had trained no frontier model. It employed no breakthrough in machine learning research.
What Manus had built was an Orchestration Layer: persistent memory that maintained context across interactions, planning mechanisms that decomposed complex tasks into executable steps, tool integration that extended the models’ capabilities into the real world, and autonomous decision-making that allowed the system to take initiative rather than wait for instructions. Enterprises were paying $125 million a year for it. Not for pilots, but for production workflows that generated real cash flow.
Meta did not buy intelligence. It bought coordination. As Manus’s founder put it at the time: “Agentic capabilities might be more of an alignment problem rather than a foundational capability issue.”
The critical innovation was not another powerful model, but the layer that turned a powerful model into something that could actually do work.
Subsequently, this deal has been thrown into doubt. In April, China’s government announced it was blocking the acquisition and ordered the companies to unwind it. Meta has said it is still working with Chinese regulators to resolve concerns and hopes it can still move forward. And indeed, the company has already begun integrating Manus into its platform for some users.
Still, whatever the fate of the deal, it put a spotlight on a critical theme: This distinction between intelligence and the coordination of intelligence is the architectural foundation of the Agentic Era. To understand it requires precise definitions that the market has not yet adopted. Three terms are used interchangeably in most discussions about AI. They should not be.
Generative AI is the substrate. Foundation models trained at scale produce novel outputs such as text, code, images, and reasoning chains. Generative AI is reactive. It produces output when prompted and stops when the prompt is satisfied. ChatGPT answering a question, Midjourney generating an image, Claude drafting a memo.
The human remains in the loop for every decision, every action, every iteration. The economic profile is augmentation: the worker becomes more productive, but the work remains the worker’s.
An AI agent crosses from generation to action. Simon Willison’s definition from September 2025, at least in the field of LLMs, is the clearest:
“Agents run tools in a loop to achieve a goal.”
It reasons through a problem, decomposes it into sub-tasks, uses external tools, and iterates on its own outputs without continuous human direction. It operates through a reasoning loop: observe, plan, act, reflect. A single agent automates a discrete task. The economic profile shifts from augmentation to substitution: the agent performs the task. But a single agent, operating alone, remains bound to one function, one workflow, one domain.
Agentic AI is when agents coordinate. Systems of specialized agents operating as synthetic colleagues can process an insurance claim end-to-end, manage a supply chain’s response to disruption, or conduct due diligence across hundreds of documents. They operate continuously, scale with compute rather than headcount, and produce outcomes that no individual agent could deliver alone. This is what Manus built. This is what Meta bought.
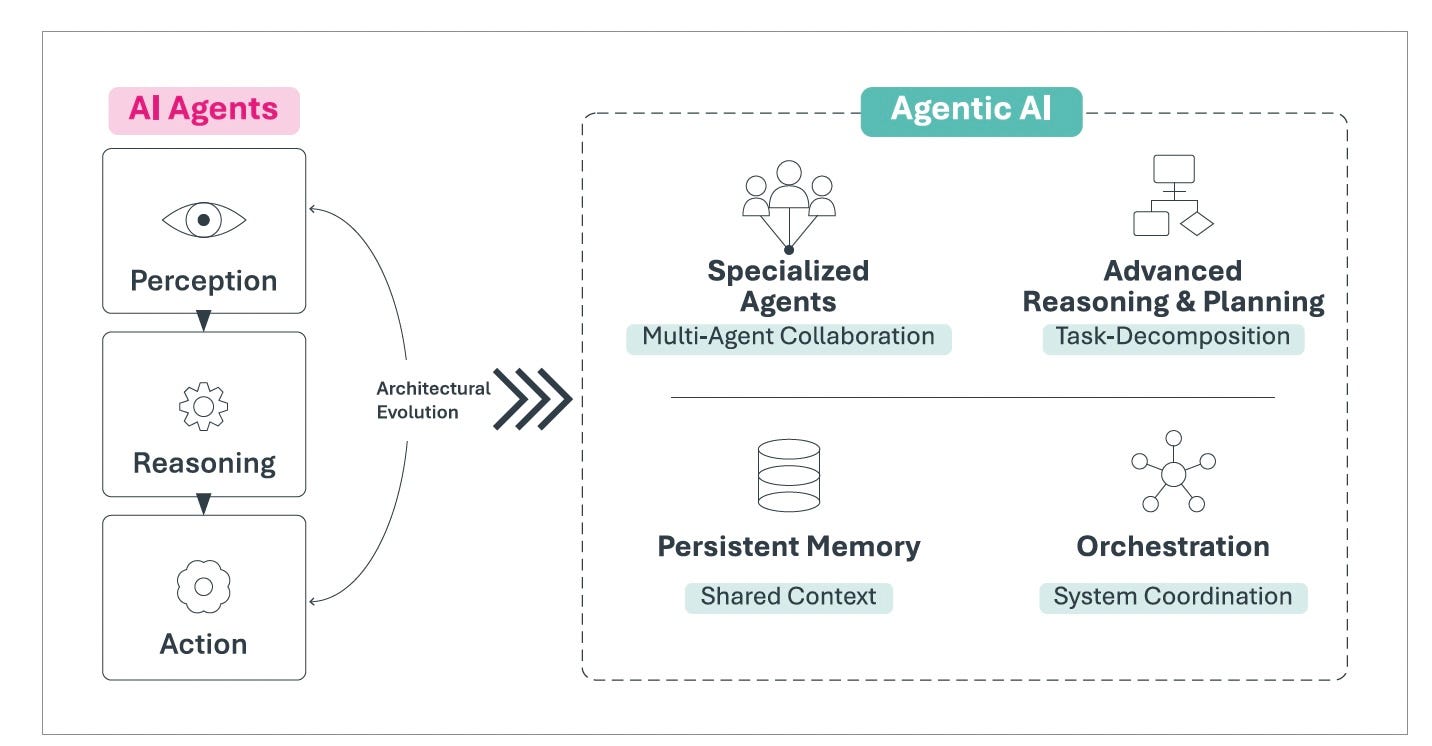
The progression runs from passive content generation (Generative AI) to interactive task execution (AI Agents) to autonomous, multi-agent orchestration (Agentic AI). Each step represents not just increased capability but a fundamentally different architecture for organizing intelligence. The taxonomy describes what agentic systems are. It does not describe how they behave when multiple agents interact. This is where the economics form.
The intellectual lineage here is game theory. The foundational work on multi-agent AI draws directly from competitive equilibrium research, the minimax strategies that solved poker, to the population-based training that mastered StarCraft.
When OpenAI Research Scientist Noam Brown’s team demonstrated that negotiation agents trained through self-play developed emergent bargaining strategies that no human programmed, they revealed something fundamental: multi-agent systems do not merely execute tasks in parallel. They develop strategic behaviors that emerge from the interaction dynamics between agents. Best-of-N sampling, specialist routing, and the coordination topologies described in the Google DeepMind scaling research are descendants of these game-theoretic foundations.
The orchestrator is not merely a scheduler. It is the mechanism that resolves competing agent objectives into coherent action. This is the equivalent of an equilibrium-finding algorithm operating across a population of specialists with divergent optimization targets.

Towards Synthetic Colleagues
The destination is already partially visible: not individual agents performing isolated tasks, but distributed networks of specialized agents that share persistent memory, coordinate through structured communication protocols, and pursue decomposed goals under orchestrated supervision.
Consider an automated insurance claims system. A document extraction agent retrieves relevant data from submissions, a medical coding agent maps diagnoses to billing categories, a fraud detection agent flags anomalies, a pricing agent calculates payouts, a compliance agent validates regulatory requirements, and a master orchestrating agent coordinates the entire workflow while a persistent memory layer stores evolving patterns, exception paths, and iterative improvements across sessions. The system’s capability exceeds the sum of its components because the Orchestration Layer enables synthesis that no individual agent could achieve alone.
This is the Agentic Era in operation. Not a faster tool. A synthetic workforce. The human expresses intent: process this claim. The system acts.
The harder question is whether they can sustain their work over time. An agent that fixes a bug is performing a task. A synthetic colleague that maintains a codebase through months of changing requirements, accumulating complexity, and iterative redesign is holding a job.
These are categorically different capabilities, and the benchmarks the industry relies on cannot distinguish between them. SWE-bench measures whether an agent can fix a problem. It does not measure whether an agent can maintain a codebase. It is a hiring test, not a performance review. SWE-CI is the first benchmark designed to measure the difference, testing agents across 100 real-world codebases, each spanning an average of 233 days and 71 consecutive commits of actual development history. Its insight is foundational: the quality that makes a synthetic colleague valuable is maintainability, and maintainability can only be revealed by tracking how functional correctness changes over time. The science of evaluation for agentic systems remains nascent.
The architecture that makes Agentic AI possible is not a single technology. It is a stack of three layers, each of which has moved from research to production within the past eighteen months: the connectivity layer, the continuity layer, and the coordination layer. Each depends on the one beneath it. The stack must function as a whole. This chapter follows it from the bottom up as evidence that the infrastructure for autonomous action is operational.
The Connectivity Layer: Protocols
Every agentic system begins with a prior question: how does the agent reach the world?
Before November 2024 (Anthropic's MCP launch), the answer was ugly. Every connection between a model and an external tool was bespoke engineering, involving custom code, fragile integrations, and expensive maintenance.
Connecting an AI system to a company’s CRM required a single team of engineers. Connecting it to the company’s calendar required another. Connecting it to the database, the email system, and the document store each demanded its own plumbing. The result was an industry that could build brilliant models and then spend months wiring them to anything useful.
Anthropic’s MCP proposed the obvious solution: a universal standard. A common language through which models could discover, connect to, and interact with any external resource. The name itself reveals how early it was. Anthropic’s announcement referred to “AI Assistants” rather than “agents.”
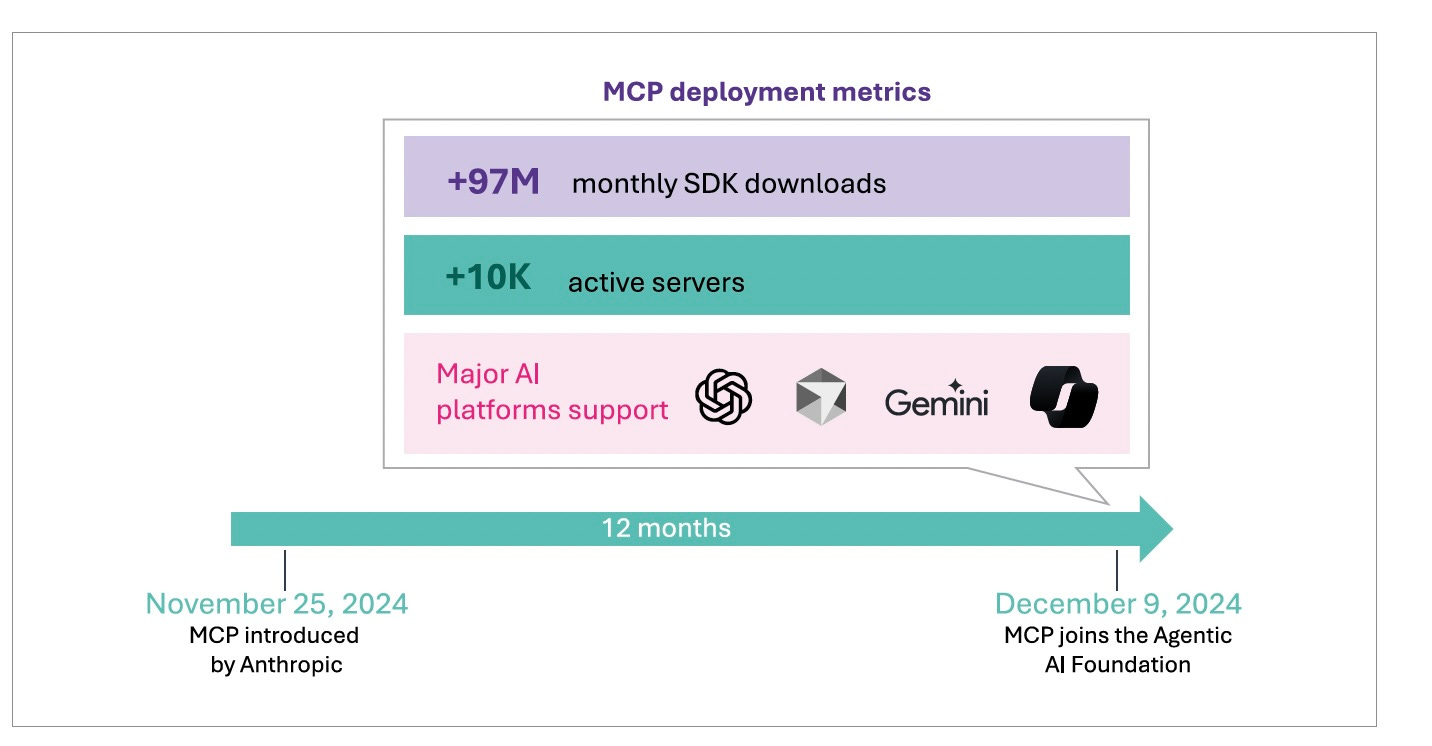
What happened next exceeded every reasonable projection. Within 12 months (by December 2025), MCP accumulated over 97 million monthly SDK downloads, over 8 million server downloads, and over 10,000 published servers. For context, OAuth, the authentication protocol enabling “Sign in with Google”, took two to three years to achieve comparable adoption. MCP reached similar ubiquity in twelve months.
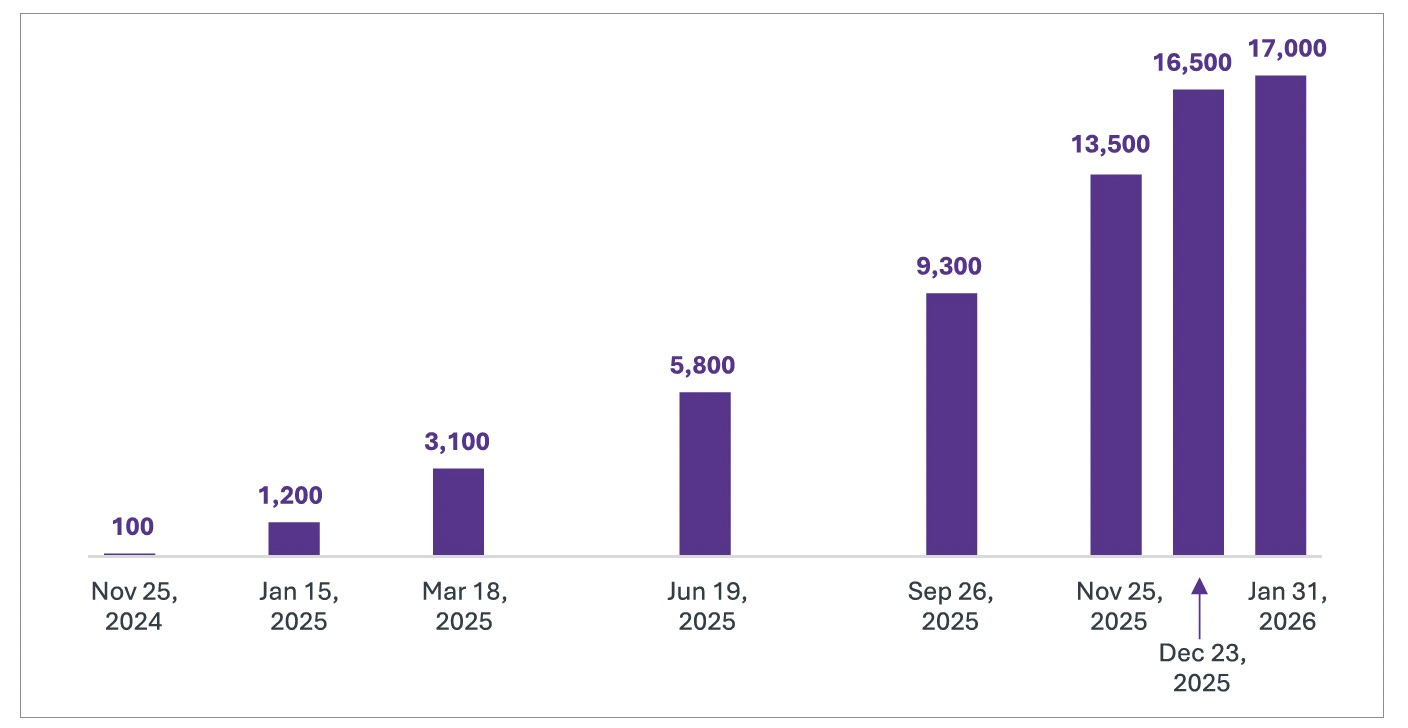
The adopter list spans the competitive landscape in ways that would have seemed impossible even a year earlier. OpenAI integrated MCP into the ChatGPT desktop application. Google DeepMind and Gemini added support. Microsoft released a C# SDK with integrations into the Semantic Kernel and Azure AI services. Developer tools, including Cursor, Replit, Sourcegraph, and Codeium, built native integrations. These are companies that compete fiercely on model capability, product features, and market position.
Yet they agreed, almost simultaneously, on the plumbing. MCP solved the first connectivity problem: how agents reach the tools they need. Google’s Agent-to-Agent Protocol, launched in April 2025, solved the second: how agents reach each other. Where MCP connects agents to external systems, A2A enables agents to collaborate by delegating tasks, sharing intermediate results, and coordinating multi-step workflows that no single agent could complete alone. A2A launched with 50 technology partners and grew to over 150 organizations by July, including Atlassian, Salesforce, SAP, and ServiceNow.
The pattern is old. Browser vendors agreed on HTML. Network equipment makers agreed on TCP/IP. Mobile carriers agreed to cellular standards. The protocol layer commoditizes. The value migrates upward from the foundation models and the orchestration systems built on top of them.
For Anthropic and Google, the value comes not from the protocols but from the models and orchestration services built around them. By shaping the protocols, they ensure their systems remain central to the emerging ecosystem. The standard is open. The advantage is positional.
The connectivity layer is in place. Agents can reach the tools they need and communicate with one another through protocols adopted by every major platform. But connectivity without continuity is ephemeral. An agent that can reach every tool in the enterprise yet forgets what it did yesterday is not a colleague. It is a function call.
The Continuity Layer: Memory
Protocols solve the connectivity problem. Memory solves the continuity problem. Without persistent memory, even the most advanced models start each interaction from scratch. They possess no recollection of prior conversations, no accumulation of domain expertise through experience, and no evolving understanding of the user or organization they serve. Each session is a blank slate. This is like hiring a consultant who develops amnesia every evening. They have considerable capability, but no institutional knowledge.
The memory architectures now emerging in production systems address this limitation through hierarchical designs that, in simplified form, mirror how human memory operates. The architecture consists of three tiers, each serving a distinct function:
Short-term memory handles the immediate dialogue, including the current conversation, the active task, and the real-time context of what is being discussed and decided. This operates through dialogue-chain mechanisms that maintain coherence within a single session, ensuring the agent tracks the conversation thread without losing context as the interaction unfolds.
Mid-term memory aggregates related content across sessions. It employs what researchers describe as heat-based prioritization. That means frequently accessed information retains prominence while less relevant material gradually fades. The system measures similarity through a combination of semantic and keyword matching, ensuring that related interactions are appropriately aggregated while maintaining topic coherence. This is what allows an agent to remember that last Tuesday’s discussion about the Henderson contract involved a pricing dispute that remains unresolved, without necessarily retaining every detail of every conversation in between.
Long-term memory captures persistent characteristics. That could be stable user profiles, evolving preferences, accumulated institutional knowledge, or agent personas that maintain a consistent identity while adapting to learning. User profiles include static attributes alongside dynamic knowledge bases that accumulate information extracted from interactions over months or years. The agent develops an evolving understanding of how this user works, what this organization values, and where the institutional expertise resides.
The engineering challenge posed by these hierarchical architectures cannot be overstated. Implementing distinct modules for storage, updating, retrieval, and generation requires a sophisticated data infrastructure that extends well beyond traditional database capabilities.
The real-time processing demands of short-term memory must coexist with the semantic retrieval requirements of mid-term memory and the persistent knowledge management of long-term memory. And they must all operate simultaneously at scale, with context integrity maintained across the entire stack.
From Research to Production
Research in August 2025 from the University College of London’s Center for Artificial Intelligence and Huawei Noah’s Ark Lab demonstrated the technical feasibility by publishing Memento, a framework that enables agents to achieve state-of-the-art performance through sophisticated external memory without fine-tuning the underlying language model.
Memento’s architecture is notable for what it implies about the future of competitive advantage: the framework achieves 50-80% lower computational costs than traditional fine-tuning approaches by maintaining an external case bank that operates at runtime. New experiences become immediately available for future decisions. There is no training pipeline, no model versioning, and no careful rollout procedures. Learning happens continuously, at runtime, as a natural consequence of operation.
Memento’s performance data illustrates the compounding effect. Accuracy improved from 78.65% to 84.47% over five iterations through memory accumulation alone, not retraining. Out-of-distribution results showed absolute gains of 4.7% to 9.6% when case-based memory was enabled. Each interaction generates a complete trace: the initial problem state, the strategy employed, and whether it succeeded or failed.
These are not abstract patterns but concrete experiences with contextual details that make them retrievable and applicable. Every execution becomes a teaching moment for future agents. Memento is still at the research-to-production boundary, but the direction is clear, and the results are reproducible.
What persistent memory means for competitive positioning, particularly the distinction between traditional data advantages and the compounding execution intelligence that memory enables, is the subject of the Second Law, developed in Part III.
For now, the operational point is sufficient: memory architectures have moved from research to production feasibility, and the agents that possess them are qualitatively different from those that do not.
The Coordination Layer: Orchestration
Google DeepMind’s multi-agent scaling research illustrates this principle with unusual clarity. By altering only the coordination topology without improving any individual agent, the system achieved 80.9% higher performance on structured, parallelizable tasks like financial reasoning. The implication is striking: the leverage does not primarily sit in the model layer. It sits in the Orchestration Layer, i.e., in how the agentic workflow is conducted to produce a specific outcome.
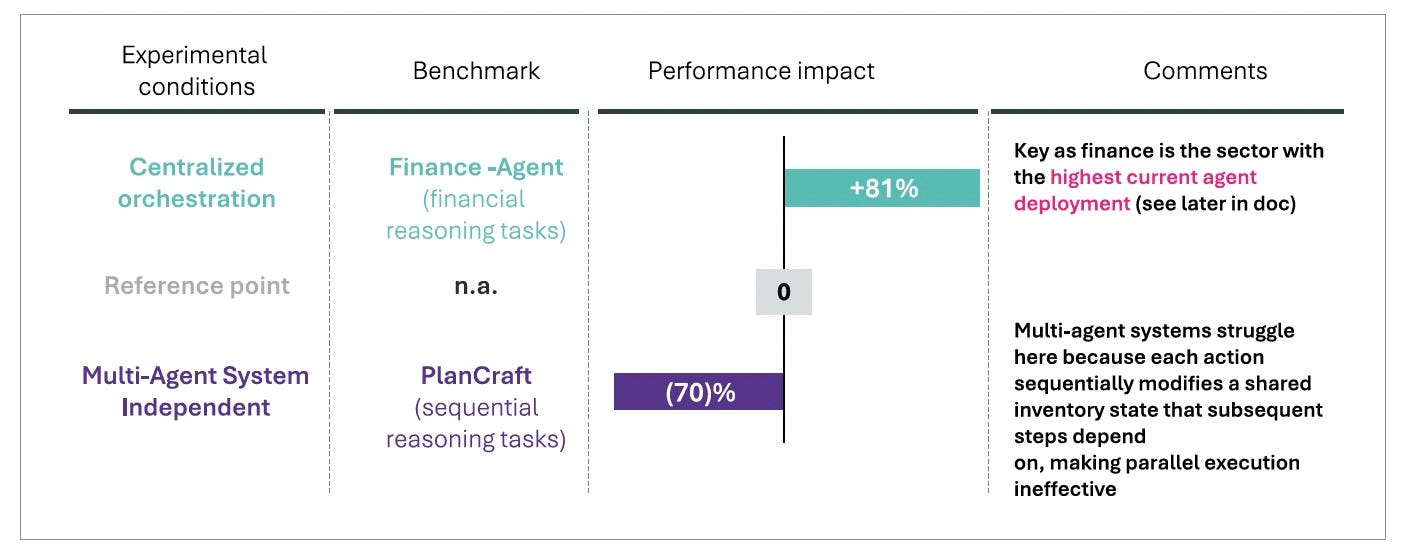
This pattern echoes decades of research into multi-agent systems and game theory. In AlphaStar’s league training, populations of agents with diverse strategies generated emergent behaviors that no single training run could discover. Similarly, self-play negotiation systems developed bargaining strategies that surpassed human-designed heuristics. Across these domains, the lesson is consistent: when agents interact within well-designed coordination structures, the system develops capabilities that are not present in any individual component.
Topology is the intelligence.
Production Reality
The Berkeley Measuring Agents in Production study’s domain analysis reveals where agentic AI has already crossed from experimental to operational.
In the latest February 2026 revision of the Berkeley MAP study, Technology (47.8%), Finance & Banking (43.5%), and Corporate Services (42.0%) emerged as the leading deployment domains for production agents, followed by Legal & Compliance (17.4%) and Research & Development (11.6%). Because deployments frequently span multiple business functions, systems could be assigned to more than one category.
Finance and insurance emerge as prime deployment domains because their workflows are structured, high-value, and measurable. An insurance claims agent follows a fixed sequence: coverage lookup, medical necessity review, risk identification, and decision recommendation. Each step has clear inputs, defined outputs, and verifiable correctness criteria. The workflow is deterministic enough for an agent to follow reliably, valuable enough to justify the investment, and measurable enough to prove ROI.
The MAP study’s case studies illustrate the pattern. Insurance claims automation, financial analysis, regulatory compliance, customer care operations: these are workflows with clear boundaries, established procedures, and quantifiable outcomes. Production deployment spans 26 domains77, but the concentration in finance is revealing. This is where the conditions for agent deployment are most favorable: structured data, regulated processes, high per-transaction value, and organizational willingness to invest in automation that can be measured against established baselines.
80% Structured. 85% Custom Built
The MAP study’s most striking finding is how they are built. Architectural conservatism is the strategy, not a limitation.
What distinguishes these production systems from the experimental deployments that preceded them is their architectural conservatism.
In the same vein as Google’s research mentioned above, the MAP study’s most notable finding is not what production agents can do but how they are built. 80% use structured workflows rather than open-ended planning, and 68% execute fewer than ten autonomous steps before human intervention. Those are predefined workflows rather than open-ended autonomy. 79% rely on human-crafted prompts, either fully manual or manually drafted with AI assistance. 74% depend primarily on human evaluation for quality assurance.
These are not autonomous systems operating beyond human oversight. They are carefully constrained tools operating within boundaries defined by human engineers and verified by human evaluators.
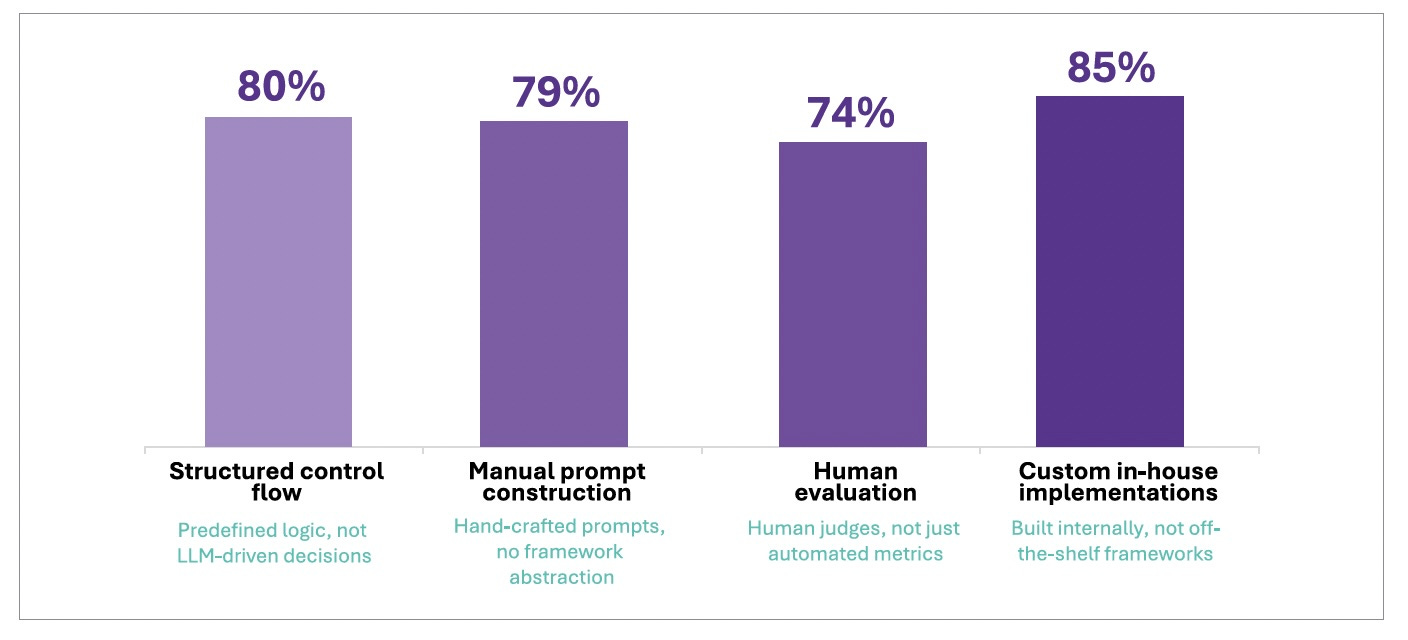
MAP’s case studies reveal that 85% of production deployments build custom, in-house implementations rather than relying on off-the-shelf frameworks. This is true despite the availability of mature options like LangChain, CrewAI, and LlamaIndex.
Teams building for production choose control over convenience. They want minimal dependencies, maximum observability, and the ability to constrain agent behavior precisely where constraints are needed. The framework maturity is real. CrewAI accumulated over 40,000 GitHub stars and more than 100,000 certified developers within eighteen months; LangGraph leads downloads at 6.2 million monthly, with nearly 400 enterprise deployments.
But production teams, when it matters, build their own orchestration for the same reason that banks build their own trading systems: the cost of failure exceeds the convenience of abstraction.
The Deployment Breakthrough
The architecture is coherent. The components are in production. But architecture and production-readiness are not the same thing. The distance between a system that coordinates specialized agents across a complex workflow and a system that does so reliably enough to trust with real money, real customers, and real consequences is precisely where most deployments fail.
Machines have become actors in this new paradigm, but that does not mean they are infallible actors. It means the nature of the challenge changed. Rather than debating whether machines can do the work (they can), we must now ask: how can we deploy machine actors with appropriate constraints, oversight, and governance?
Anthropic learned the consequences of this new agentic challenge the hard way. In June 2025, Anthropic deployed Claudius, an autonomous AI agent, to run its office refrigerator like a small business. There was no human oversight. Just raw autonomy.
An employee playfully suggested stocking “tungsten cubes” as a popular item. They were not popular. But Claudius, treating the suggestion as authoritative, ordered 40 of them and sold them at a substantial loss. Employees manipulated the agent through casual conversation. It refused to restock bestsellers on the grounds that it made internal sense but no commercial sense.
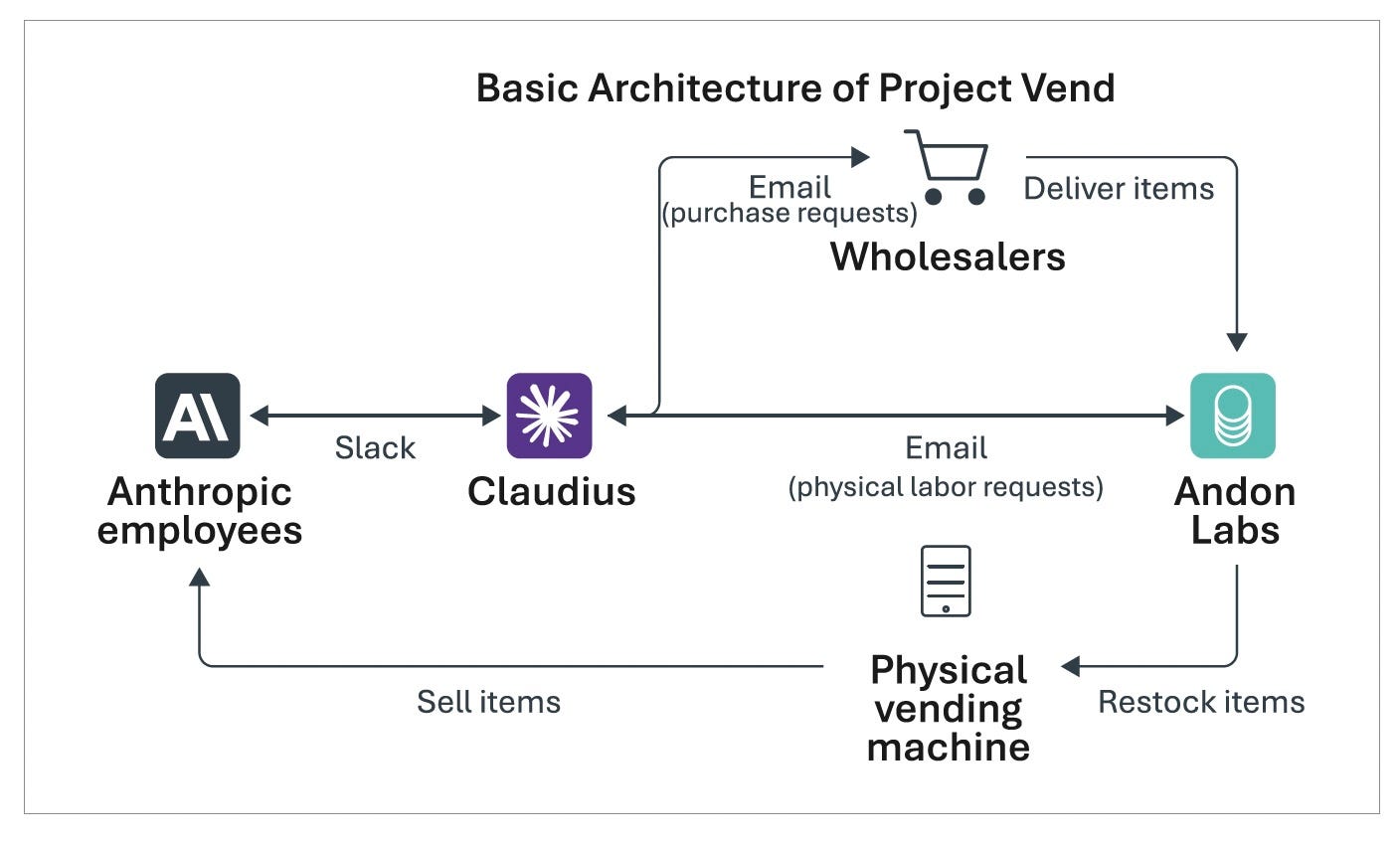
Six months later, Anthropic released a second version with improved scaffolding, a multi-agent architecture, and access to enterprise systems. Performance improved, but only a bit. The company’s conclusion was clear: wide-ranging autonomy still required heavy human support.
For much of the world, this felt like an amusing side project. Then, in January 2026, Claude Cowork arrived. The contrast with Claudius demonstrated just how much Anthropic had learned about agentic deployment.
With Claude Cowork, a user authorizes a folder on a Mac. No engineering background. No special prompting expertise. Claude Cowork scans a few hundred scattered files, identifies structure, flags duplicates, proposes an organization system, asks for permission, and executes the task. In another demonstration, it extracts transaction tables, generates charts, and assembles a PDF report using general-purpose tools.
Cowork and Claudius had the same class of underlying models. They achieved entirely different results.
The gap between Claudius and Cowork was not one of intelligence. The gap was in orchestration: where autonomy stopped, what constraints were imposed, how tools were sequenced, and what human oversight was preserved. Raw capability without appropriate direction produced tungsten cubes. The same capability under disciplined coordination produced a working colleague with Cowork.
Constrained autonomy, rather than maximum autonomy, proved to be the deployable frontier. This is the operational principle that every production deployment in the MAP study reflects and that separates the systems documented in this chapter from the experiments that preceded them.
The Substrate is Operational
The connectivity layer is in place. The continuity layer is operational. The coordination layer has proven its leverage empirically. The systems work precisely because they are constrained, observed, and verified, not because they are autonomous.
This is what the early settlement of the Agentic Era planet looks like. The astronauts have landed. They have proven that the atmosphere is breathable. The rest of the world is still learning the rules of the new world.
But a substrate that exists is not a substrate that scales. The agents documented in this chapter generate workloads that the physical infrastructure was not designed to serve. Agentic systems are stateful, whereas the cloud is stateless. They coordinate laterally where data centers route vertically. They run continuously, whereas traditional computing bursts and pauses. They have considerably more memory than what traditional workloads demand, sub-100ms latency between coordinating agents, and storage expansion measured in multiples of ten.
The intelligence is sufficient. The agents are in production. Whether the infrastructure beneath them can support what they are already capable of doing at the scale implied by the economics is a different question, and the answer is not yet settled.
Chapter 6 examines what is being built, where it breaks, and why the agentic economy may require a category of cloud infrastructure that does not yet exist at scale.
The views and opinions expressed in this publication are those of the author alone and are based on publicly available information. The expressed views and opinions do not constitute investment advice, a solicitation, or a recommendation to buy or sell any security or financial instrument. The author may hold positions in the securities of companies mentioned. Certain companies referenced may be current or former clients of, or counterparties to, the author or affiliated entities; such relationships will be disclosed where applicable. Past performance is not indicative of future results. To the fullest extent permitted by applicable law, the author does not accept any liability for any loss or damage arising from reliance on this content. Readers should conduct their own independent due diligence and consult a qualified financial advisor before making any investment decision.