
Orchestration Economics: Six Tremors, One Fault Line (Chapter 2)
A cascade of shocks, each amplifying the others, formed a discontinuity and ushered us in a new paradigm by causing the marginal cost of cognition to collapse.


This is the latest excerpt from AGNT: The Orchestration Economics Manifesto - An Investment Framework for the Agentic Era. Each Thursday, I explore a major theme of the Manifesto and unpack the frameworks, adding extra context with more recent developments. Note: The figures and sequential references are taken directly from the larger Manifesto.
The theory of “punctuated equilibrium”, popularized by evolutionary biologist Stephen Jay Gould, posits that long periods of stability are occasionally interrupted by rapid change. Significant evolutionary leaps happen quickly rather than steadily accumulating over time. Species appear stable for millennia, then shift in geological instants. Gould’s deeper insight was that individual punctuations do not matter in isolation. What matters is when multiple punctuations occur within the same geological window and reinforce each other.
Between September 2024 and February 2026, six rapid phase shifts arrived across different layers of the AI stack:
Intelligence arrives: OpenAI’s o1 crossed the PhD reasoning threshold. The capability existed for the first time.
Intelligence becomes accessible: DeepSeek and open-source models have proved that frontier capabilities no longer require frontier budgets.
Silicon independence: Gemini 3 Pro demonstrated frontier performance on non-NVIDIA chips.
Protocol standardization: Model Context Protocol (“MCP”) became the universal coordination layer, surpassing 97 million monthly downloads.
Inference swarm: Moltbook’s agent swarm generated millions in daily compute spending from autonomous agents operating without human attention.
Long-context frontier: The one-million-token context window crossed from research capability to production infrastructure, enabling agents to reason across entire codebases and filing suites.
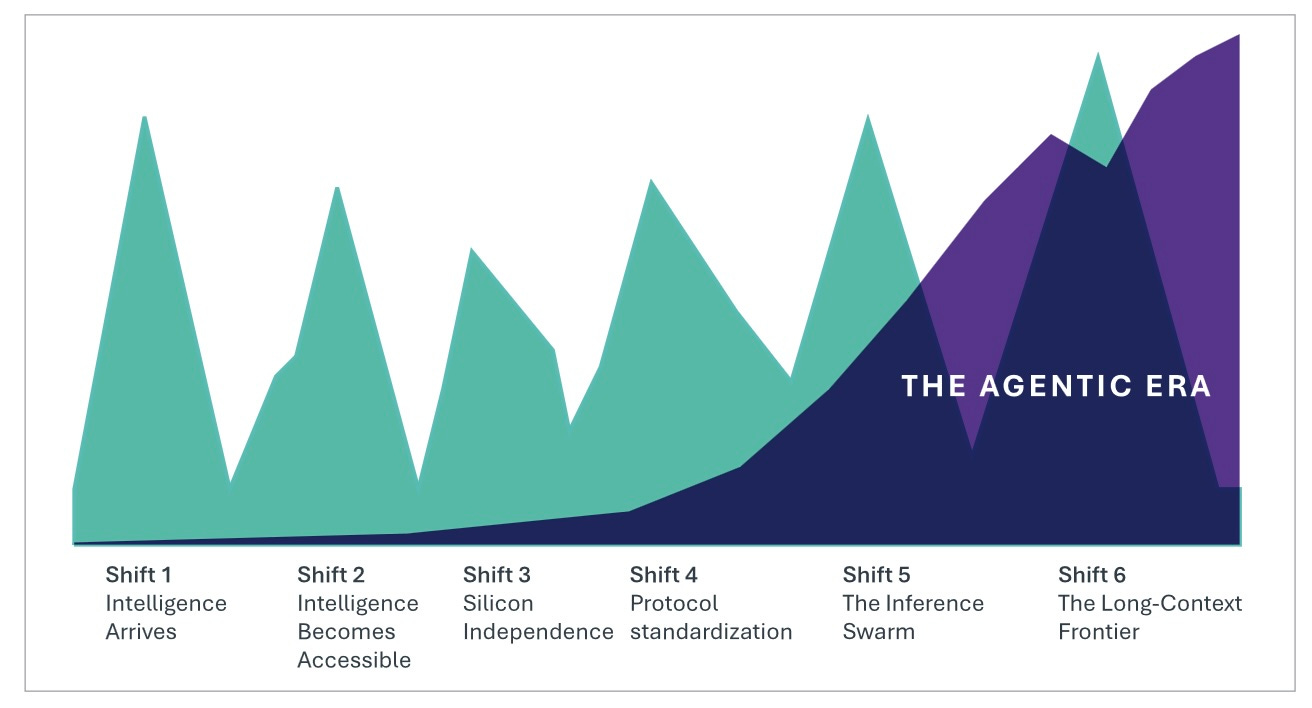
They laid the structural foundation for the Agentic Era in which intelligence is cheap, ubiquitous, and coordinated at machine scale. Intelligence is no longer the scarce resource on which competitive advantage can rest.
Since then, we have only seen these trends accelerate. Open released GPT-5.4 in March 2026 with 1M-token context and native computer-use capabilities, while Anthropic followed with Claude Opus 4.7 in April 2026.
Each was a tremor. Together they traced one fault line. This chapter follows the crack.

Shift 1 – Intelligence Arrives
For years, frontier models impressed without threatening. They could draft, summarize, and generate code. These were useful augmentations that left the structure of professional work intact. GPT-4, the most capable model available from mid-2023 through mid-2024, scored 39% on GPQA Diamond. The machine was fluent. It was not expert.
Google DeepMind’s Gemini 1.5, unveiled in February 2024, demonstrated significant advances in multi-step reasoning. Anthropic’s Claude 3 Opus followed in March 2024, setting new benchmarks in complex analytical tasks. OpenAI’s Strawberry model arrived in September 2024, released as “o1”, further pushing reasoning capabilities. All three relied on massive model architectures and extensive computational resources. This created a soaring market for the companies that provided the infrastructure, most notably placing chipmaker NVIDIA on a trajectory to becoming the world’s most valuable company and a kind of AI kingmaker.
But o1 did something the others had not. It scored 77.3% on GPQA Diamond, making it the first model to surpass PhD-level human performance on a benchmark designed to be their floor. The model did not merely generate plausible-sounding answers faster. It reasoned: decomposing problems, testing hypotheses, and revising its approach when intermediate steps failed.
This was a qualitative shift in what machine intelligence could do.
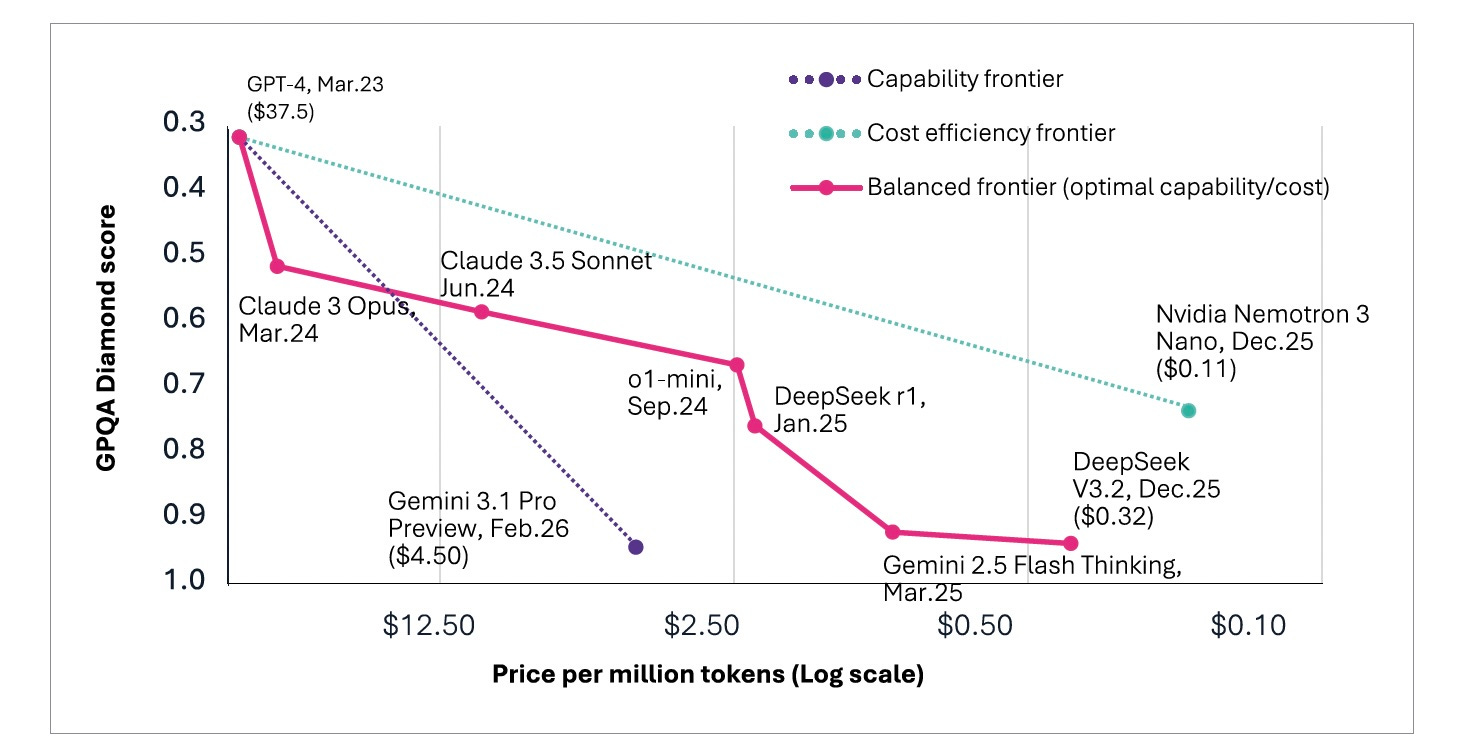
Claude 3.5 Sonnet, Gemini 2.0, and a succession of reasoning models arrived in rapid sequence, each pushing scores higher and prices lower. By early 2026, multiple models from competing laboratories exceeded 90% on GPQA Diamond [Figure 7], surpassing not just the PhD threshold but the PhD experts themselves. The capability had been proven and replicated by at least five independent sources.
The first foundation stone of the agentic paradigm was laid: the intelligence required to perform expert-level cognitive work existed as a commercially available capability. What remained was access, coordination, and then letting it loose.
Shift 2 – Intelligence Becomes Accessible
The arrival of PhD-level reasoning would have mattered less if it had remained the exclusive province of three or four well-capitalized laboratories that charged premium prices and could raise billions for compute infrastructure. A Chinese entrepreneur shattered the assumption that it might be in early 2025.
Liang Wenfeng had founded DeepSeek in 2023, leveraging his background in quantitative finance to pursue software-driven efficiency rather than brute computational scale. The company embraced open source and a fundamentally different philosophy of model building that challenged the entire economic calculus of building large language models.
In January 2025, the company released DeepSeek-R1, which matched ChatGPT’s performance on several benchmarks while costing 20-50x less to run than OpenAI’s o1, depending on the workload/tasks. The market reaction was immediate. The Nasdaq fell more than 600 points. NVIDIA lost nearly $600 billion in market value in a single day, the largest one-day loss in history. Broadcom shed $200 billion.
The debate over whether DeepSeek achieved its efficiency through genuine architectural innovation or through distillation from Western frontier models missed the structural point. Regardless of method, the result was the same: near-frontier intelligence was now available at commodity pricing. And the pattern continued to accelerate. By August 2025, DeepSeek-V3.1, a hybrid model that switched between thinking mode for complex reasoning and traditional interactions, delivered roughly 90% of GPT-5’s capability at 1-2% [Figure 12] of the cost, with self-hosting prices as low as $0.01-0.05 per million tokens compared with $3.44 for GPT-5 and up to $30 for Claude.
Adoption followed quickly. Andreessen Horowitz partner Martin Casado noted in August 2025 that roughly one in five startups pitching the firm with open-source models were already using Chinese models, suggesting that the cost advantage was no longer theoretical. When OpenAI released GPT-5 a few weeks later39, the benchmarks looked strong, scoring 74.9% on SWE-bench Verified and 94.6% on AIME 2025.
In November 2025, open and private models converged further. Moonshot AI released Kimi K2 Thinking, an open-source model that achieved state-of-the-art performance on Humanity’s Last Exam at 44.9%, surpassing both GPT-5’s 41.7% and Claude Sonnet 4.5, at a reported $4.6 million in training costs for its trillion-parameter architecture. For context: This represented a ~15-40x cost reduction relative to 2023 frontier training runs ($78M for GPT-4, $191M for Gemini Ultra) and was comparable to GPT-3’s reported 2020 training cost, now producing a reasoning system that outperformed the most sophisticated proprietary models on a benchmark specifically designed to be unsolvable by current AI.
$4.6 million. The number deserves repeating because of its implications.
The innovation went beyond cost reduction. Kimi K2 employed what Moonshot called “interleaved thinking and tool use”. This methodology uses reasoning tokens and function calls to alternate fluidly within the same inference pass. The model thinks, acts, observes results, thinks again, acts differently based on new information, and continues this dynamic cycle for hundreds of steps without degradation.
Unlike DeepSeek, the detonation failed to shake markets or rattle executive nerves. It went largely unnoticed. But the signal was unmistakable: open source had caught up to the closed-model frontier, not just in raw capabilities, but in the sophisticated reasoning and agentic behavior that defines the next wave.
Open-source models had achieved near-parity with the world’s most expensive systems. Intelligence was no longer scarce. It was no longer expensive. The second foundation stone was laid. Anyone with an API key or a sufficiently capable laptop could access reasoning capability that had not existed at any price eighteen months earlier.
Shift 3 – Silicon Independence
On November 18th, 2025, one week after Kimi K2, Google released Gemini 3 Pro and demonstrated what happens when the cost collapse meets full-stack control.
The benchmarks were unambiguous: 76.2% on SWE-Bench Verified, 91.9% on GPQA Diamond, 81% on MMMU-Pro for multimodal understanding, and the highest-ever Elo score on LMArena at 1,501 at the time. Gemini 3 Pro was, by most measures, the strongest frontier model available. The benchmark performance was the headline. What produced it was the real story.
Previous Gemini generations had been trained on Google’s Tensor Processing Units, but they had not topped the industry leaderboards. NVIDIA-trained models had. Gemini 3 broke that pattern. The strongest frontier model available according to SWE-Bench, GPQA Diamond, and LLMArena Elo had been trained entirely on non-NVIDIA silicon45. This had never happened before. The company that controls more than 90% of global search, 3.5 billion active Android devices, and the world’s largest cloud infrastructure has demonstrated that frontier AI performance does not require NVIDIA chips.
The consequences extended beyond silicon independence. The competition had shifted from a single-layer to a vertical-integration model. The debate was not about who had the best model. It was: Who controls enough of the stack to optimize the entire chain? The economic signal was as significant as the technical one.
Google could offer Gemini 3 Pro at input pricing 2.5 times cheaper than Claude Opus 4.6 [Figure 13] for comparable performance on standard tasks because Google manufactured its own silicon, trained on its own infrastructure, and distributed through products already used by billions. The cost advantage was an architectural inevitability of vertical integration.
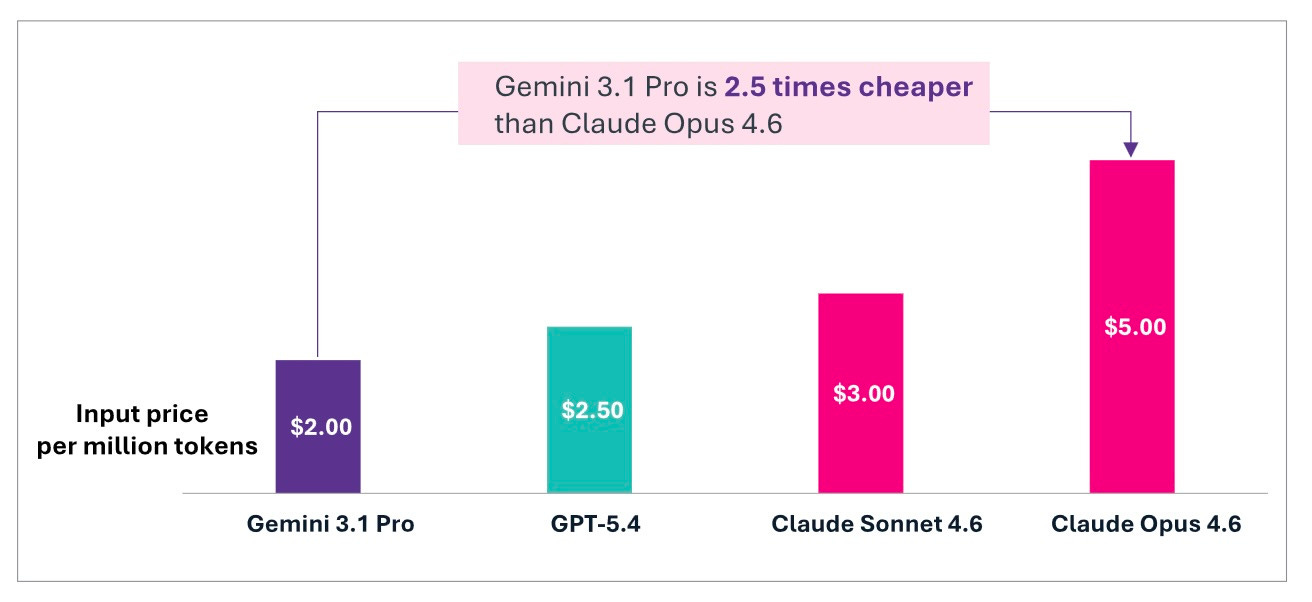
Google also had a massive distribution advantage. It could bundle Gemini 3 into the productivity and cloud stacks already used by hundreds of millions of developers and workers. In a leaked memo reported by The Information, OpenAI CEO Sam Altman had written that Google’s next version of Gemini could “create some temporary economic headwinds for our company”, adding, “I expect the vibes out there to be rough for a bit”. His assessment proved correct. While Magnificent 7 stocks fell 7.6% between late October and late November, Google rose 18%. The market was rendering its verdict: full-stack control was worth more than model leadership.
The third foundation stone was in place: the cost of intelligence is driven not only by algorithmic efficiency and open-source competition but by vertical integration of the kind only a handful of companies in the world can execute.
Shift 4 – Protocol standardization
If DeepSeek commoditized intelligence, MCP standardized how it would be coordinated.
Anthropic’s Model Context Protocol (MCP) was released in November 2024, providing a standardized way for AI agents to connect to external services, invoke tools, and maintain context across interactions. Within months, it became the industry’s universal connector, adopted by competitors such as OpenAI and Google. Anthropic donated MCP in December 2025 to the Linux Foundation to form the Agentic AI Foundation. By January 2026, MCP had surpassed 97 million monthly SDK downloads.
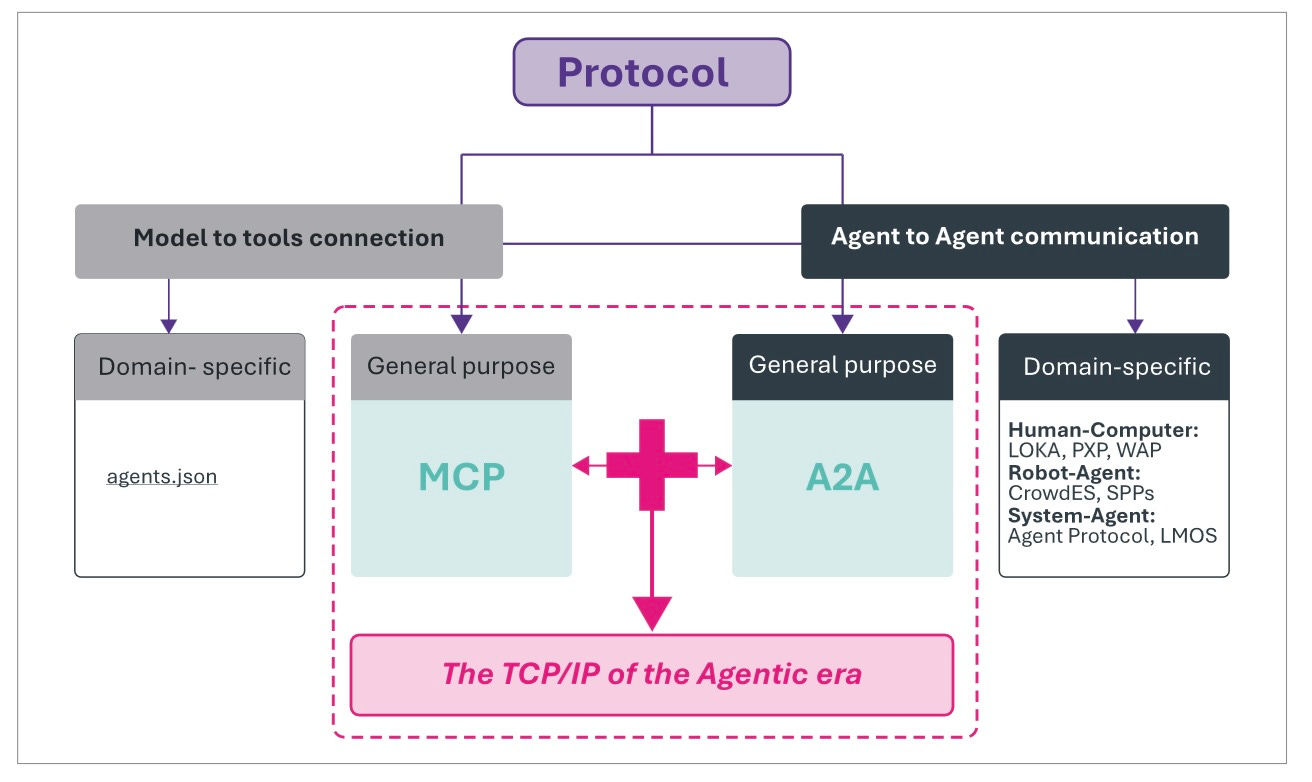
What started as a modest product launch became a TCP/IP moment for the Agentic Era. MCP rapidly evolved into the plumbing through which intent flows, and context accumulates. The impact of MCP made a few headlines and triggered no major stock-market panics, but its structural impact was profound. It defined how intelligence would be coordinated. It enabled the deployment of agents in ways that became increasingly cost-effective as users gained greater control.
Whoever defined the coordination standard could shape the architecture of the entire era that followed. The protocol layer’s technical architecture and competitive implications are examined in detail in Part II. What matters here is the phase shift itself: the coordination substrate moved from nonexistent to near-universal adoption in twelve months.
Shift 5 – The Inference Swarm
The fifth phase shift arrived in January 2026 with the Moltbook phenomenon, a Reddit-like platform for autonomous agents that drove countless headlines alternating between wonder, humor, and alarm at the implications of machines running amok and talking among themselves.
Look past the theater and content to see the real revelation: autonomous agents generating millions in daily compute spending without human attention. When agents operate at machine speed, producing hundreds of API calls per hour, the demand curve decouples from human work patterns.
There are no evenings, weekends, or vacation days in inference demand from agents. The “demand swarm” is not a metaphor. It is a description of the compute load that scales with the agent population rather than the human population. Agent populations, unlike human populations, can double in days. Agent demand scales with agent population, not human population.
Moltbook is the description of compute load with no modern precedent.
Shift 6 – The Long-Context Frontier
We have defined the five phase shifts that have created sufficient conditions for the Agentic Era. But even as we move into that new era, the foundational phase shifts continue.
In April, DeepSeek-V4 moved from rumor to release. DeepSeek launched two preview models, including V4-Pro, a 1.6 trillion-parameter open-weight system with a default one-million-token context window. According to DeepSeek’s technical disclosures, the model employed architectural innovations, including the Hybrid Attention Architecture, Manifold-Constrained Hyper-Connections, and compressed sparse attention mechanisms, designed to dramatically reduce the computational burden of long-context inference.
The long-context frontier is where the discontinuity becomes structural rather than incremental. The previous shifts established capability. This one redefines advantage. In the Agentic Era, value migrates away from raw model intelligence toward control of the environments, systems, and workflows within which intelligence operates.
There is a qualitative threshold within the progression from thousands to millions of tokens. At thousands, an agent reviews a file. At tens of thousands, a module. At hundreds of thousands, a service or workflow. At one million tokens with reliable retrieval and memory management, the agent no longer operates on fragments. It operates on systems.
An agent can now hold an entire codebase, legal archive, research corpus, or operational workflow in working memory: every dependency, test suite, configuration file, pull request history, policy document, and architectural decision. The system becomes legible as a coherent whole rather than a sequence of disconnected windows.
This changes the nature of cognition itself. Earlier AI systems generated answers. Long-context agents accumulate institutional context. They learn the conventions, patterns, edge cases, and failure modes of the environments they inhabit. Every interaction becomes a form of in-context learning. The repository, company, or workflow effectively becomes part of the model’s operational memory.
Below this threshold, agentic coding remains a form of assisted editing. Above it, the system begins to resemble autonomous engineering. The agent traces failures across repositories, refactors across services without losing coherence, and executes multi-step reasoning over entire operational environments rather than isolated tasks.
The strategic implication is profound: the advantage no longer belongs primarily to whoever builds the strongest model. It belongs to whoever controls the richest context layer: the proprietary systems, workflows, data exhaust, and institutional memory within which intelligence operates.
DeepSeek-V4 transformed autonomous engineering from a frontier-lab capability into an increasingly commoditized infrastructure layer. By combining open weights, million-token context windows, and near-frontier reasoning, it demonstrated that long-context autonomous coding was no longer confined to a handful of hyperscale laboratories.
What previously required privileged access to frontier infrastructure can now be deployed by startups, research groups, and, increasingly, by individual developers operating on commodity hardware or inexpensive cloud infrastructure. The economic threshold for deploying coding agents collapsed. Adoption no longer flowed primarily through enterprise procurement cycles. It spread bottom-up through developers, open-source communities, and infrastructure ecosystems.
This mirrored the earlier commoditization of reasoning itself. First, frontier reasoning became reproducible. Then it became affordable. Now, long-context autonomous engineering followed the same trajectory. The pattern repeated: intelligence commoditizes. The value migrates upward.
The deeper shift was not simply larger context windows, but a redefinition of where learning occurs. When long-context agents operate continuously over entire repositories, workflows, and operational environments, every interaction becomes a form of in-context adaptation. The model absorbs conventions, architectural patterns, recurring edge cases, coding styles, testing logic, and organizational preferences from the systems it inhabits.
An agent that has processed thousands of pull requests within a single repository begins to accumulate something resembling institutional memory. Not because the model itself was retrained, but because the operational environment became part of its working cognition.
This changes the locus of learning. The system itself becomes the training ground. Proprietary workflows, repositories, operational histories, and organizational context become continuously compounding cognitive assets. Long context does not merely improve recall. It accelerates the emergence of environments that learn to use agents — and agents that learn to operate within environments — at machine speed.
One Fault Line
These shifts must be understood as a single event, not as a sequence of independent developments.
Discontinuity does not move in a straight line. There are moments of acceleration, followed by what feels like a plateau where stagnation has taken hold. Often, in ways big and small, several critical elements align independently of each other, each necessary for the next stage of acceleration.
The phase shifts of 2024, 2025, and early 2026 were the defining examples. The intelligence. The accessibility. The vertical integration. The protocol. The swarm. The long-context frontier. None of these alone would have produced the discontinuity.
Intelligence without accessibility would have remained a premium product for the few. Accessible models without coordination protocols would have been powerful curiosities, but isolated. Protocols without cheap intelligence would have been empty plumbing. Autonomous agents without model convergence would have been too expensive to deploy. Vertical integration without protocol standardization would have fragmented the stack rather than unified it.
Together they produced something that did not previously exist: intelligence that is cheap, ubiquitous, coordinated at machine scale, and accessible to anyone with an API key. This is the structural foundation of the agentic paradigm.
The cost of intelligence will continue to fall. Models will continue to converge. Protocols will continue to standardize. Agent populations will continue to grow. These trajectories already in motion, governed by economics that reinforce rather than exhaust themselves.
But a foundation is not a building. The substrate is in place. Chapter 3 examines the moment it became visible, when models crossed from assisting professionals to performing professional work, and when agents began acting without being asked.
The views and opinions expressed are those of the author alone and are based on publicly available information. The expressed views and opinions do not constitute investment advice, a solicitation, or a recommendation to buy or sell any security or financial instrument.
The author may hold positions in the securities of companies mentioned. Certain companies referenced may be current or former clients of, or counterparties to, the author or affiliated entities; such relationships will be disclosed where applicable.
Past performance is not indicative of future results. To the fullest extent permitted by applicable law, the author does not accept any liability for any loss or damage arising from reliance on this content. Readers should conduct their own independent due diligence and consult a qualified financial advisor before making any investment decision.