
Orchestration Economics: The Second Law: Context Builds Moats (Chapter 9)
Only an agent with deep operational context produces reliable outcomes.


This is the latest excerpt from AGNT: The Orchestration Economics Manifesto - An Investment Framework for the Agentic Era. Each Thursday, I explore a major theme of the Manifesto and unpack the frameworks, adding extra context with more recent developments. Note: The figures and sequential references are taken directly from the larger Manifesto.
Two insurance companies deploy master agents. Both sit at the origin of intent. Both orchestrate specialist agents for extraction, risk modeling, fraud detection, and pricing. Both have crossed the reliability threshold and operate as autonomous functions. Both charge per outcome rather than per seat.
On day one, they are equivalent. By month six, one is pulling away. By year two, the gap is too wide to close. Not because it has better models. Both license the same foundation models. Not because it has more data. Both process similar volumes. Because it has deeper context. And context, unlike data, compounds.
This is the Second Law: In the agentic economy, competitive advantage belongs to whoever accumulates the richest operational context and embeds it in their Orchestration Layer. Operational context becomes the “soil” for agents that ultimately allow business outcomes to be achieved.
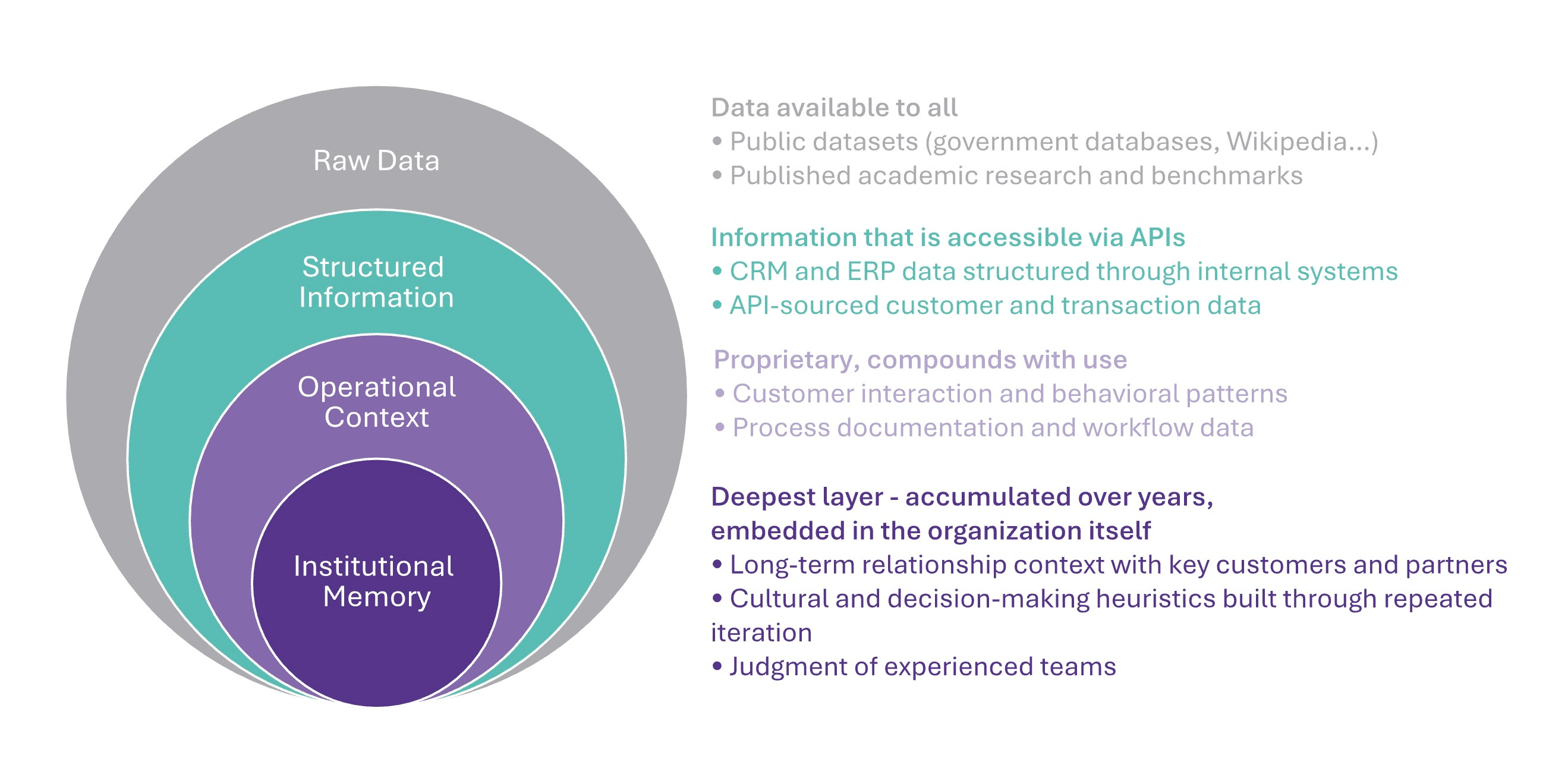
Context is not data. It encompasses data when built correctly through sophisticated memory architectures that layer behavioral patterns, relationships, and temporal understanding into something that makes agents genuinely intelligent.
Data tells you what happened. Context tells the agent what to do next.

Why Context, Not Data
The enterprise software industry spent the last decade obsessed with accumulating data. Companies built vast data lakes and warehouses, convinced that whoever collected the most information would dominate their markets. That conviction is now failing its most important test.
The MIT GenAI study released in July 2025 caused such industry uproar by reporting that 95% of corporate GenAI projects failed to get past the pilot stage. This was widely misinterpreted as a judgment of the inherent limitations of generative AI. What most readers missed was one of the key reasons researchers identified for these failures: model quality fails without context. The models had access to petabytes of enterprise data. What they lacked was the operational intelligence that transforms data into effective action.
The distinction is fundamental. Data is static. It sits in databases. It can be queried, copied, or transferred. It answers the question, “What happened?”
Context is dynamic. It incorporates behavioral patterns, relational understanding, temporal awareness, and causal reasoning that emerge from sustained operational interaction. It answers the question “What should happen next, given everything we know about this specific situation?”
Return to the two insurance companies. Both have the same claims data in the form of submission histories, payout records, and policy details. But only one has accumulated context: the knowledge that claims from certain regions involving certain diagnoses follow a predictable escalation pattern, that this particular adjuster’s flag for fraud has a 94% confirmation rate while that one’s has a 61% rate (illustrative numbers), that Q4 submissions from mid-size manufacturers spike in complexity because of year-end inventory adjustments.
This is not data in a table. It is operational intelligence that emerged from thousands of orchestrated interactions, encoded in the memory architecture of the system.
The master agent with this context makes better routing decisions. It assigns the right specialist to the right claim. It anticipates complications before they manifest. It produces more accurate outcomes faster. The master agent, without it, has the same capabilities but operates blindly. It is technically competent but operationally naive.
The Four Dimensions of Context
Context is not a single thing. It is multidimensional, and the dimensions interact in ways that create compound advantage:
Behavioral context captures how users and processes actually operate as opposed to how they are documented. An orchestration platform tracking how underwriters navigate workflows, such as which shortcuts they develop, where they encounter friction, and how their patterns evolve, accumulates understanding that informs agent optimization. Users claim to follow the manual. The behavioral context reveals what they actually do. One company knows what you did last month. Another knows what you will do next Thursday evening, when you are tired but not rushed, based on forty-seven matched occasions along sixty-three calibrated dimensions. That depth cannot be replicated from scratch. Those occasions accumulate only through observation over time.
Transactional context encompasses decision history and outcome tracking across extended time frames. The master agent that has seen how a thousand similar claims were resolved, including those that were escalated, those that were approved automatically, and those that triggered fraud investigations that proved correct, operates in a different cognitive universe than one processing its first hundred. A procurement agent accessing complete transaction histories makes recommendations informed by actual results rather than static supplier profiles. The accumulation over years creates an understanding that new entrants cannot replicate without a similar operational history.
Relational context maps connections and causal relationships that explain why patterns emerge. Understanding that suppliers deliver reliably for certain categories but struggle with others, that certain customer segments respond differently to pricing strategies, that workflow bottlenecks stem from interdependencies between teams rather than individual inefficiency. This allows agents to reason about causality rather than correlation. The distinction matters for autonomous decision-making, where agents must predict how actions cascade through complex systems.
Temporal context captures time-series patterns and seasonality. A manufacturing orchestration agent that understands seasonal demand fluctuations, maintenance cycles, and capacity constraints makes dramatically different decisions than one operating on point-in-time data. The agent that acts before conditions change outperforms the agent that reacts after.
There is a fifth dimension the framework must account for, one that emerged from the first production systems operating at enterprise scale. OpenAI’s internal data agent is built to reason across 600 petabytes and 70,000 datasets. It discovered that schema metadata and operational history were insufficient. Two tables can look identical at the structural level but differ in ways only the pipeline code that produced them reveals: one includes logged-out users; the other does not; one captures first-party traffic; the other captures everything.
OpenAI had to crawl its own codebase to teach the agent what the data means, not just what it contains. Constructive context is the understanding of how institutional data was built, filtered, transformed, and aggregated. It prevents the class of errors that arise when an agent interprets a field correctly at the schema level but wrongly at the business logic level. Without it, the agent produces technically correct but institutionally wrong answers.
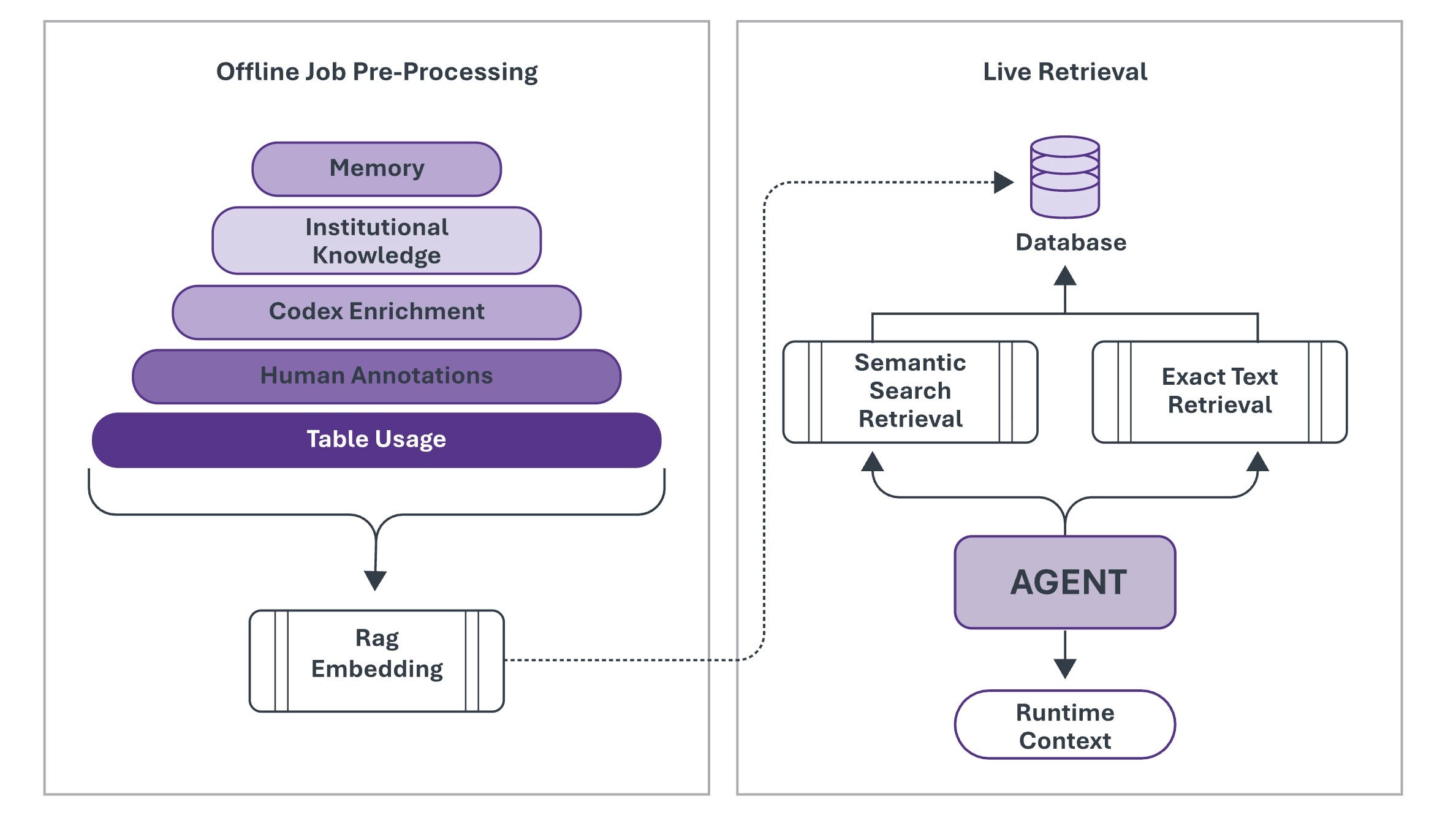
This is the reason Informatica has spent seven years building CLAIRE, a metadata knowledge graph that maps lineage, governance policies, and semantic relationships across fragmented enterprise data, compressing what was once a week-long schema mapping exercise into minutes and exposing, via MCP, the constructive context that agents need to reason correctly over enterprise systems. It is also the mechanism visible in the Claude Code source architecture described in Chapter 18: the memory consolidation system that rewrites its own index, including resolving contradictions, pruning stale facts, and converting relative references to absolute references, does not store data. It is building constructive context from operational reality, session by session, so that the next interaction begins from institutional understanding rather than raw observation.
Each dimension is valuable on its own. Together, they produce something qualitatively different: an agent that understands its operational reality the way an experienced human operator does. Except it never forgets, never transfers to a competitor, and improves with every interaction.
The Flywheel
Better context produces better agent performance. Better performance attracts more users and deeper platform integration. Deeper integration generates richer context. The cycle accelerates. The companies establishing early leads in context accumulation open gaps that widen with every transaction.
This is why incumbent enterprises in regulated or physically grounded industries possess advantages that their technology adoption speeds obscure.
Their operational context, accumulated over decades, provides foundations that digital-native competitors cannot bootstrap overnight. The logistics carrier that has routed a billion shipments, the insurer that has processed ten million claims, the bank that has underwritten a trillion dollars in credit. They each possess contextual foundations that no amount of compute can synthesize. The context is a byproduct of operation. You cannot buy it. You earn it through sustained execution.
From Data Moats to Memory Architecture
The previous era’s moat was the database. This system of record, surrounded by workflows, made switching painful. Context moats require a different architecture: memory systems that learn, not databases that store.
The distinction is not semantic. Recording is storage. Data enters, persists, and can be retrieved. Every database does this. Recording is table stakes. Memory is something else. Memory connects past to present in ways that shape the future. It learns from what happened. It updates its understanding. It changes behavior based on accumulated experience. In the human mind, memory is not a filing cabinet. It is a living process, constantly reconstructing the past to predict tomorrow. The systems competing for the orchestration position are building memory architectures that function similarly.
The engineering required is substantial. Implementing hierarchical memory with distinct modules for storage, updating, retrieval, and generation requires infrastructure that extends well beyond traditional database capabilities. Short-term memory maintains conversation and task context. Mid-term memory captures session-level patterns and user preferences. Long-term memory preserves persistent knowledge across extended timeframes. That includes user profiles, organizational patterns, and domain expertise. Each tier requires different update mechanisms, different retrieval strategies, and different governance policies.
As UCL and Huawei’s Noah’s Ark Lab demonstrated through Memento, agents can achieve state-of-the-art performance through external memory without retraining the underlying model. They do this by storing experience tuples as discrete retrievable cases, improving from 78.65% to 84.47% accuracy over five iterations through memory accumulation alone.
The implication is structural. In the fine-tuning paradigm, the moat belonged to whoever had the most compute. With memory-augmented learning, the moat shifts to whoever has the best domain-specific experiences. A startup with deep expertise in legal contracts can build agents that outperform general-purpose models on contract analysis. They do this not by outspending frontier labs, but by accumulating superior execution data through their orchestration platform.
Execution Data
This creates a category distinct from both enterprise data and training data. We call it execution data. Enterprise data answers “what happened?” Training data encodes “what patterns exist.” Execution data captures “what worked and why.” These are the specific sequences, strategies, and decisions that succeeded or failed in actual operation.
The economic properties are what matter. Traditional data shows diminishing returns. The millionth customer record adds less insight than the thousandth. The data grows. The value plateaus. Execution data compounds. Early experiences establish basic competency. Later experiences build on those foundations. The thousand-and-first claims processing discovers a pattern that improves performance across an entire category. Each interaction widens the gap.
The result is winner-take-all dynamics within specific domains. The first legal AI to handle a thousand contract negotiations will not just have more data. It will have a richer understanding of the problem space, including rare edge cases and creative solutions that competitors cannot acquire without processing a thousand contracts themselves.
In financial terms, execution data represents a new form of capital: memory capital. Like intellectual capital or brand capital, it is an intangible asset that generates future returns. Unlike traditional intangibles, memory capital can be precisely measured in terms of the number of cases, performance improvement per case, or retrieval accuracy. It can then be directly deployed. Infrastructure commoditizes. Domain-specific execution data compounds. The market is beginning to price this shift, though without fully understanding it yet.
Context Defensibility
Context advantages become durable moats only when defended against replication. Two factors determine whether they do.
Proprietary access creates the first defense. Physical-world operators possess inherent advantages because their context arises from irreplaceable operational reality. Tesla accumulates driving context through millions of vehicles in diverse conditions. Manufacturing facilities generate production context through actual operations. Logistics companies accumulate transportation context through real shipments. These companies build on contextual foundations that digital competitors cannot replicate because generating the context requires physical infrastructure.
The same applies in enterprise software through a different mechanism. The insurance company that has processed 50,000 claims through its orchestrated workflow has accumulated context that a new entrant cannot acquire without processing 50,000 claims. The context is a byproduct of operation. You cannot buy it. You cannot synthesize it. You earn it through sustained execution.
Switching costs create the second defense. When context accumulates in an orchestration platform, switching means abandoning everything the system learned. A competitor can match features, pricing, and even license identical models. It cannot manufacture the memory of accumulated interaction. The new system begins as a stranger. The deeper the context, the higher the switching cost. That’s because the gap between what the incumbent knows and what the new entrant must learn widens with every interaction.
Protocols sharpen this dynamic. MCP and A2A standardize how agents connect to systems, dissolving integration friction. But protocols cannot transfer context. They make it easier for agents to access data across systems. They cannot replicate the behavioral understanding, relational mapping, and temporal patterns that emerged from years of orchestrated operation. Companies that relied on integration friction face exposure. Companies whose moat is the quality and uniqueness of their context find that protocols reinforce their advantage, making the platform more connectable while leaving the context inimitable.
The Investment Test
The Second Law reframes how we evaluate companies in the agentic economy. The question is no longer “how much data does this company have?” It is “what kind of context is this company accumulating, how fast is it compounding, and how defensible is it against replication?”
Three pillars work synergistically:
Memory architecture determines how context is stored, retrieved, and deployed. These are the episodic, semantic, and procedural layers that transform raw experience into operational intelligence.
Context depth determines richness across behavioral, transactional, relational, and temporal dimensions.
Defensibility determines whether the context can be matched through proprietary access, regulatory barriers, or the sheer volume of operational history required.
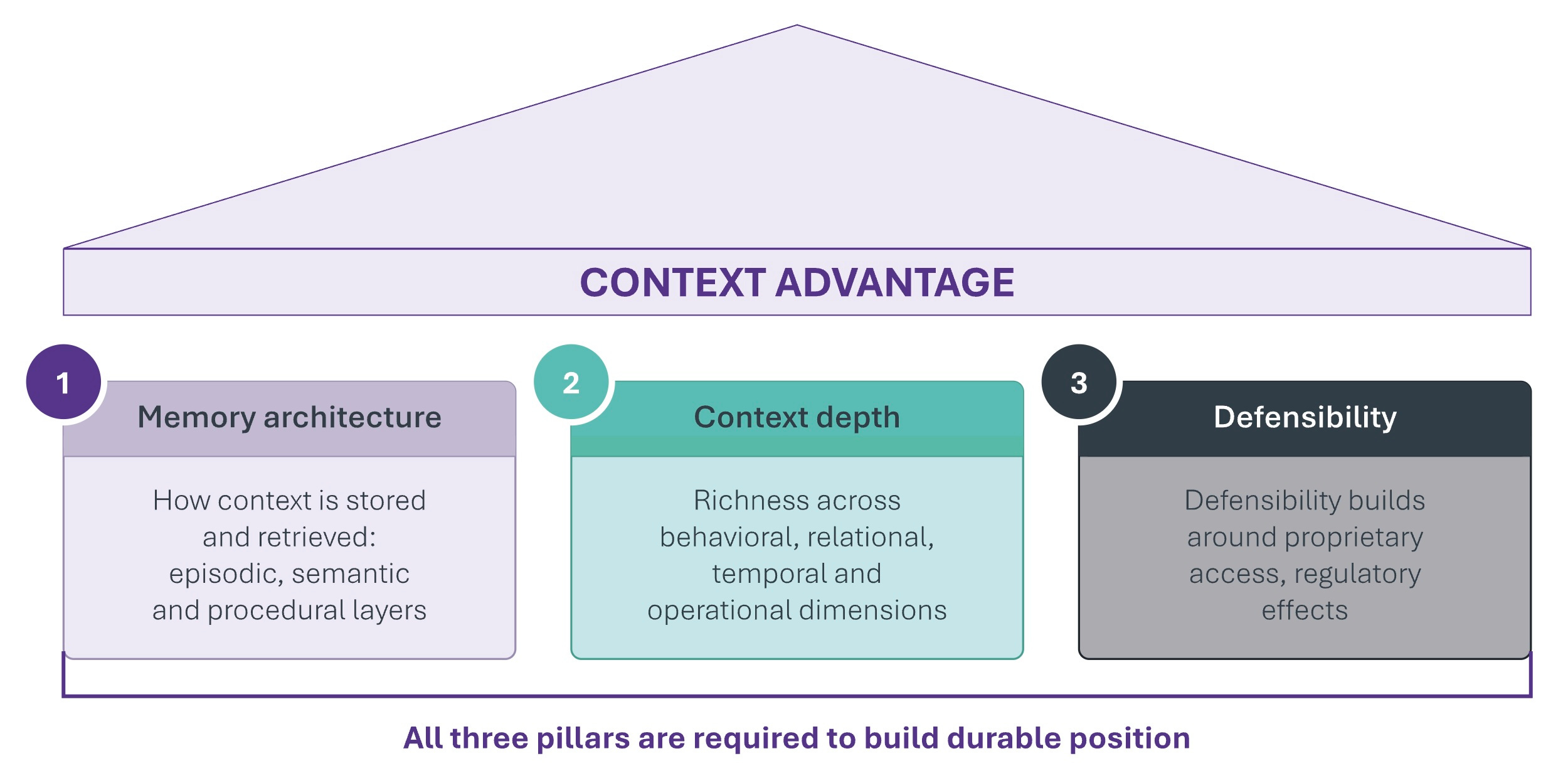
Memory systems without rich contextual content provide structure without substance. Deep context without architectural sophistication to organize and retrieve it proves unwieldy and underutilized. Defensible context that agents cannot leverage due to infrastructure limitations delivers strategic value slowly and incompletely. The durable positions require all three.
Companies where data compounds are building moats that deepen automatically. Every transaction, every user, every interaction adds to the advantage. The models become more accurate. The predictions become more reliable. The new customer benefits from everyone who came before, and everyone who came before benefits from the new customer.
The most defensible positions combine proximity to intent, deep compounding context, and proprietary access that prevents replication. The orchestrator that sits at intent origin, accumulates operational context with every interaction, and generates that context from irreplaceable operations holds a position that is nearly impossible to displace. This is the standard against which we evaluate every company in our investment universe.
The Second Law
The first two laws identify where to position and what to accumulate. But they describe conditions, not dynamics. The agentic economy is not static. Workflows change. Competitors adapt. New entrants arrive.
The orchestrator that maintains its advantage is the one whose coordination intelligence compounds faster than the environment shifts, whose learning improves with scale in ways that specialists cannot match.
That is the Third Law.
The views and opinions expressed in this publication are those of the author alone and are based on publicly available information. The expressed views and opinions do not constitute investment advice, a solicitation, or a recommendation to buy or sell any security or financial instrument. The author may hold positions in the securities of companies mentioned. Certain companies referenced may be current or former clients of, or counterparties to, the author or affiliated entities; such relationships will be disclosed where applicable. Past performance is not indicative of future results. To the fullest extent permitted by applicable law, the author does not accept any liability for any loss or damage arising from reliance on this content. Readers should conduct their own independent due diligence and consult a qualified financial advisor before making any investment decision.