
Orchestration Economics: When Exponential Growth Becomes Visible (Chapter 3)
In the winter of 2025-26, the models crossed a line, the revenue proved it was real, and the agents began acting on their own.


This is the latest excerpt from AGNT: The Orchestration Economics Manifesto - An Investment Framework for the Agentic Era. Each Thursday, I explore a major theme of the Manifesto and unpack the frameworks, adding extra context with more recent developments. Note: The figures and sequential references are taken directly from the larger Manifesto.
There comes a moment in every exponential curve when the abstract becomes concrete, when the thing everyone has been debating arrives in the specific. For generative and agentic AI, that moment came in the winter of 2025-26. It came in three waves: the models crossed a line, the revenue proved it was real, and the agents began acting on their own.

The Models Cross a Line
Until late 2025, frontier AI models were impressive but bounded. They could draft, summarize, translate, and generate code. These tasks were useful. But any honest assessment would classify them as sophisticated assistants, or “copilots”. A lawyer still reviewed every clause the model suggested. An analyst still checked every number. A developer still read every line. The model accelerated human work. It did not perform it.
Over the span of twelve weeks, from December 2025 to February 2026, that boundary dissolved. OpenAI shipped GPT-5.2 in December 2025, a model whose adaptive reasoning could sustain multi-step analysis across hundreds of pages of financial filings, legal discovery documents, and technical specifications without losing coherence or fabricating connections.
Analysts at early-access firms reported that GPT-5.2 produced equity research drafts that required editing for voice and judgment, not for accuracy or structure. The model was not assisting the analyst. It was performing the analyst’s core function, and the analyst was reviewing output rather than producing it. In February 2026, OpenAI then released Codex as a desktop application, positioning it not as a coding assistant but as a “command center for agents”, an autonomous worker that receives a task, decomposes it, executes across files, tests its own output, and returns completed work. The framing was deliberate. OpenAI was not selling a better autocomplete. It was selling a junior colleague.
Meanwhile, Anthropic had released Claude Opus 4.6 on February 5, moving the ceiling even higher. A one-million-token context window that genuinely worked: 76% retrieval accuracy on the MRCR v2 needle-in-a-haystack test at full context, compared to 18.5% for Claude Sonnet 4.5. This meant the model could hold an entire codebase, an entire contract suite, an entire quarter’s financial filings in working memory, and reason across all of it simultaneously.
The notorious “context rot,” where models degrade as conversations lengthen, was eliminated.
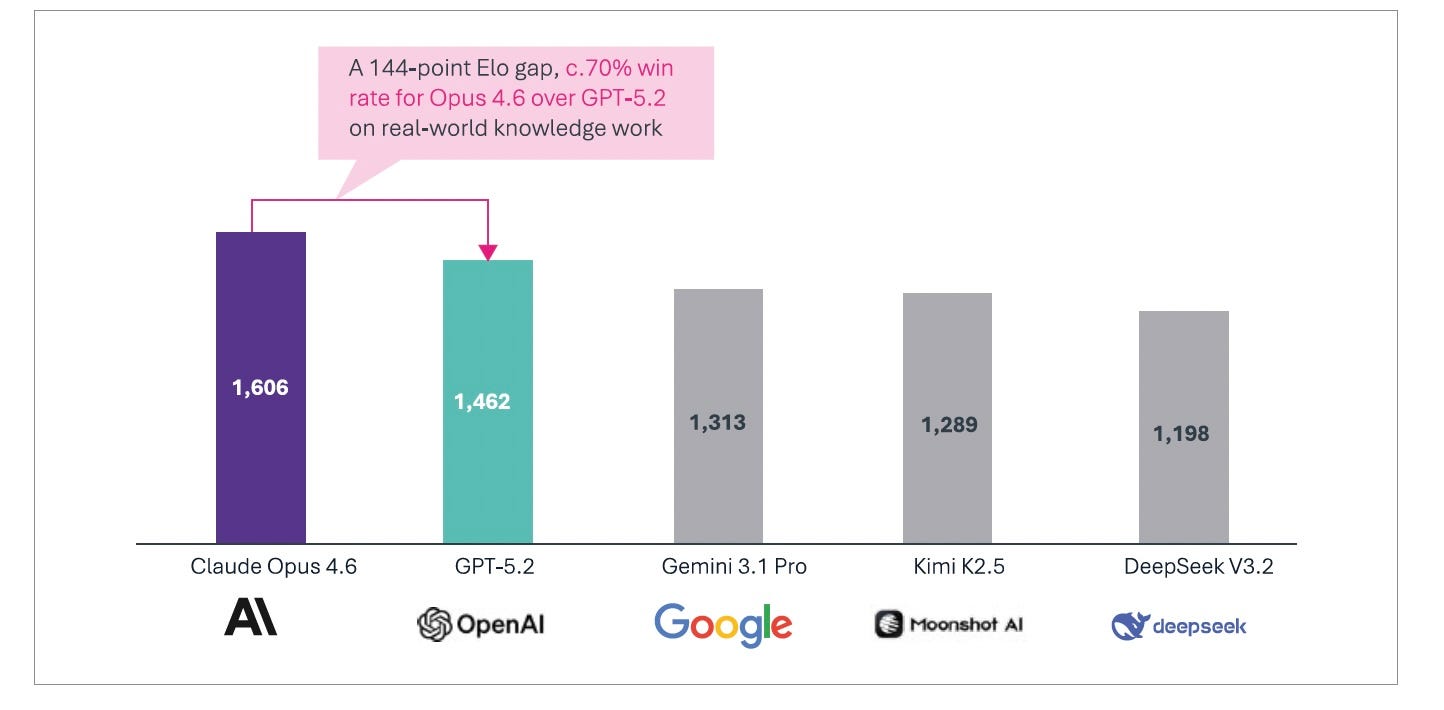
On GDPval-AA, an evaluation designed to measure performance on economically valuable knowledge work in finance, legal, and professional domains, Opus 4.6 outperformed GPT-5.2 by 144 Elo points, winning head-to-head comparisons roughly 70% of the time [Figure 16].
On Humanity’s Last Exam, the most demanding multidisciplinary reasoning test available, it led every frontier model at the time of its release in February 2026. On BigLaw Bench, it scored 90.2%. These were not narrow technical benchmarks. They measured the work that professionals do and bill for.
But the headline capability was something no model had demonstrated before: agent teams.
Through Claude Code, Opus 4.6 could spawn parallel sub-agents. These independent model instances could divide a complex task, work simultaneously on separate components, and coordinate their outputs.
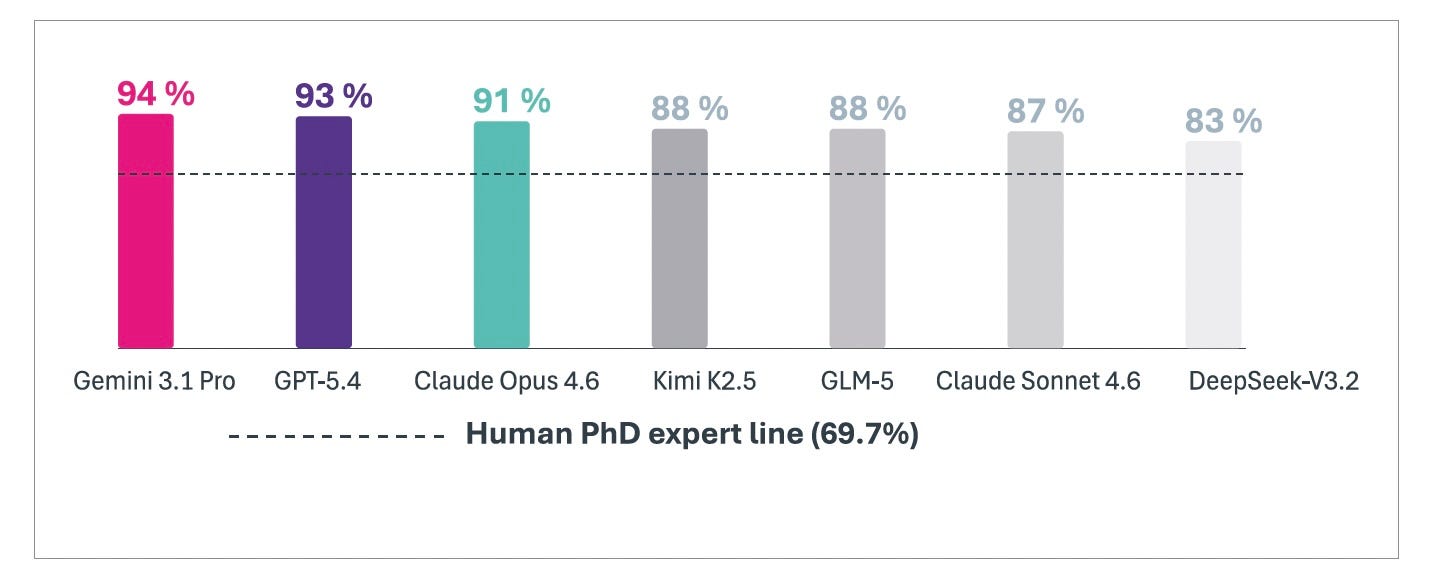
Google completed the triangle with Gemini 3 Pro. It reached 91.9% on GPQA Diamond [Figure 7], surpassing human PhD experts on the benchmark designed to be their ceiling with native multimodal reasoning across text, images, code, and video [Figure 6].
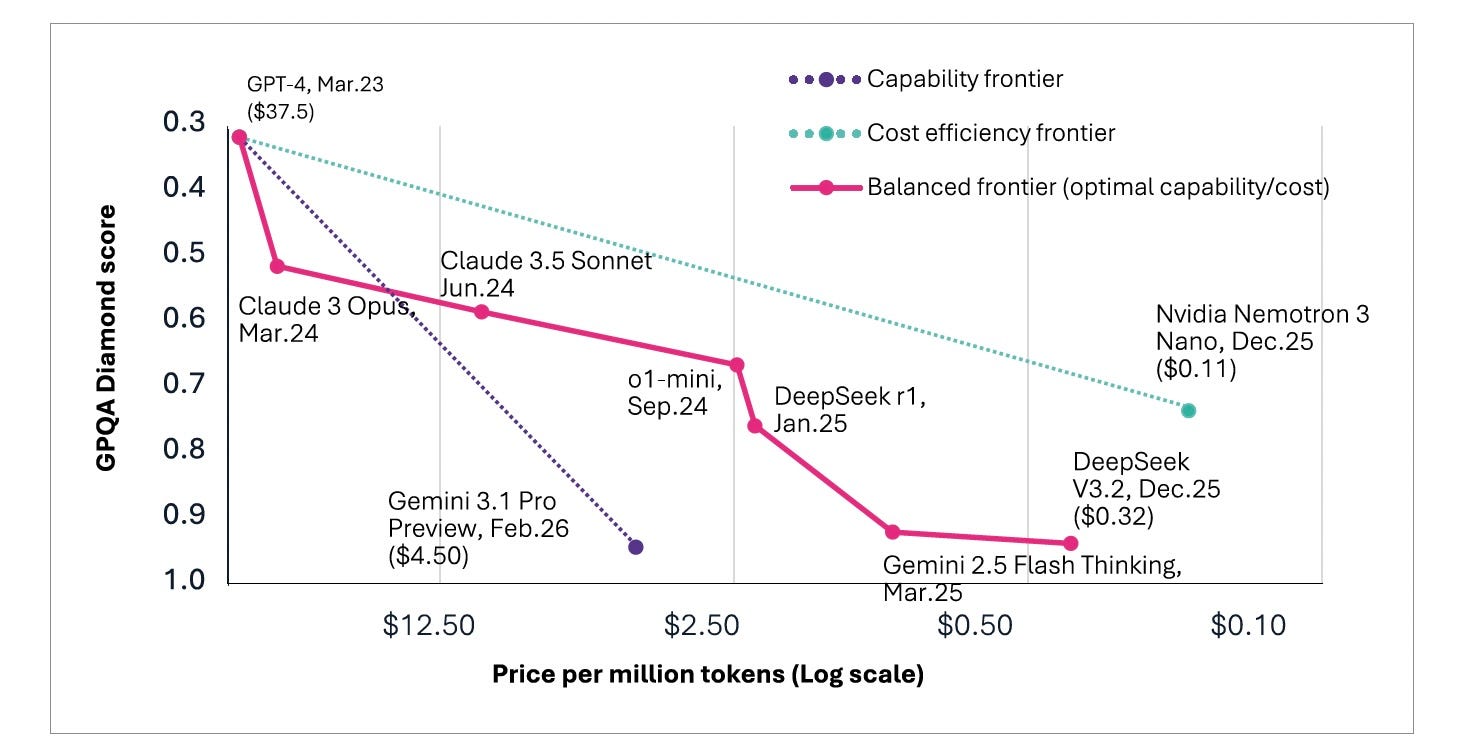
It was the moment the paradigm shifted from abstract to concrete.
Each of these models, independently, crossed the same threshold: from systems that help professionals work to systems that perform professional work. The human’s role changed from producer to reviewer. The unit of production changed from the labor hour to the orchestrated workflow. And the change was reproducible across multiple vendors, domains, and organizational contexts. Taken together, these three events represent the paradigm shifting from abstract to concrete.
Each lab, independently, converged on the same proof point: code.
Opus 4.6 set the record on Terminal-Bench 2.0 and reached 80.8% on SWE-Bench Verified. GPT-5.2’s Codex was built as an autonomous coding agent. Gemini 3 Pro matched SWE-Bench scores within fractions of a point. The convergence was not accidental.
Code is the domain where three properties coexist: structured environments with objective ground truth, a verifiability loop where output either compiles or it does not, and economic leverage, where every productivity gain compounds across the entire software stack. Code is where autonomous capability can be proved rather than asserted. The labs converged there because it was the only domain where the claim “this model does professional work” could be verified by anyone who cared to run the test.
The models did not stop at code. They wrote financial analyses, conducted legal research, built presentations from raw data, reasoned across modalities, and coordinated teams of sub-agents. Coding was proof of agentic capability. The broader professional capability was the product.
The gap between “interesting demo” and “I cannot do my job without this” closed in a single quarter.
Of course, all of these have continued to push forward.
Claude Opus 4.7 arrived in April, with increased SWE-bench agentic coding scores over Opus 4.6. GPT‑5.5 landed about the same time, with similar improvements to GPT-5.4. And in specific areas, advances seemed to go even further.
And just this week, OpenAI announced a breakthrough regarding a famous problem first posed by mathematician Paul Erdos in 1946. OpenAI claimed that an internal model disproved the most common proposed solution to the problem, a significant step if validated, because it would suggest frontier AI systems are beginning to contribute to genuinely novel mathematical discovery rather than simply retrieving or recombining known results.
Of course, looming above all of these advances is Anthropic’s Mythos. This unreleased frontier AI system has demonstrated extraordinary offensive cybersecurity capabilities, including the ability to discover zero-day vulnerabilities, generate exploit chains, and autonomously execute sophisticated cyber operations, according to Anthropic. Indeed, Anthropic caused a stir by announcing Mythos was so powerful that it had decided not to release it publicly. Instead, it has restricted access to select governments and infrastructure partners to understand and potentially mitigate its risks.
Though the benchmarks have not been released, the larger significance of Mythos lies in what it suggests about the trajectory of frontier LLM development. To be clear, there remains some debate about whether Anthropic’s claims about the power of Mythos are overhyped. However, if accurate, the Mythos story represents an inflection point at which the reasoning power of these models has crossed yet another threshold in reassessment. And in any case, the mere existence of Mythos has sent businesses and governments around the world scrambling to assess the practical meaning.
Exponential Growth
By early 2026, the consequences were visible not only in experiments and developer workflows, but in revenue and markets.
Anthropic’s run-rate revenue as of April 2026 was $30 billion, growing over 10× annually in each of the previous three years. [Figure 17] Claude Code, a command-line coding agent launched as a developer tool, surpassed $2.5 billion in annualized revenue.
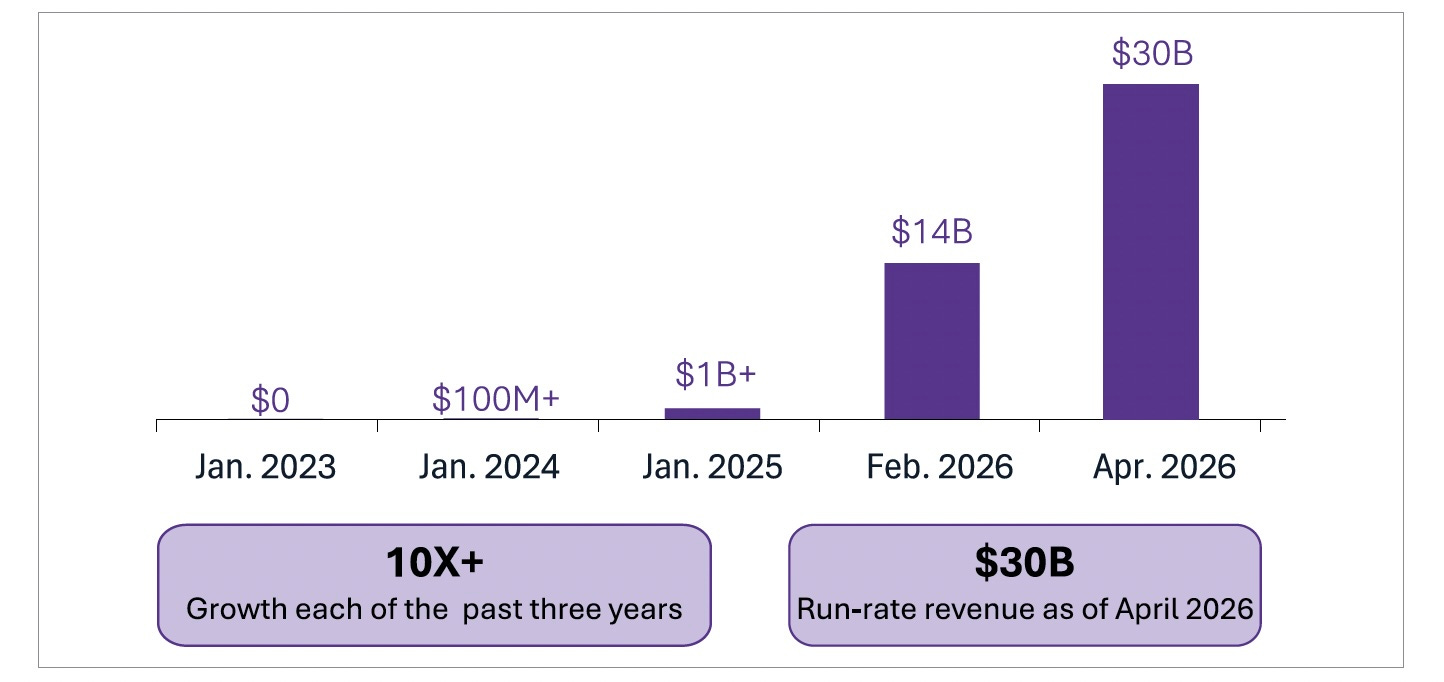
That figure doubled in the first six weeks of 2026 at the time of announcement. The number of customers spending over $1 million annually went from a dozen to over 500 in two years. Eight of the Fortune 10 are now Claude customers. This is measurable, compounding revenue for a product that has been publicly available for less than a year. More recently, SemiAnalysis reports that the ARR figure has climbed to $44 billion.
And Anthropic is one company. OpenAI reported rapid growth. Google’s AI-driven cloud revenue accelerated. Microsoft’s Copilot revenue emerged as a material line item.
The implications of this revenue growth began to shake the markets that did not yet fully understand it. In early February 2026, Anthropic announced plugins for several verticals within Cowork. The product itself was still relatively niche. The repricing it triggered was not. Roughly $285 billion in software market capitalization was erased in just 48 hours. ServiceNow, Salesforce, Workday, and Adobe each lost between 6% and 15% that week [Figure 3]. Figma hit an all-time low at the time [Figure 18].
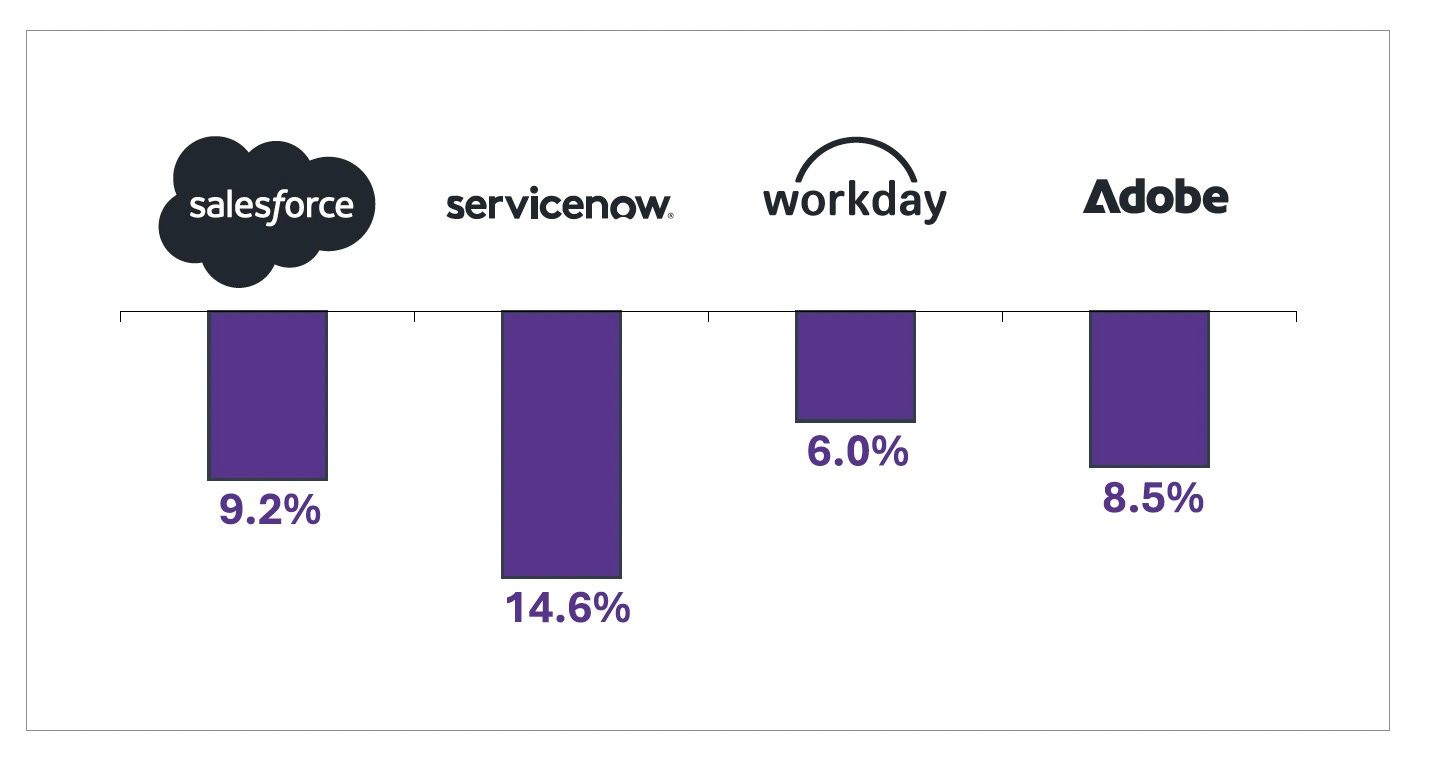
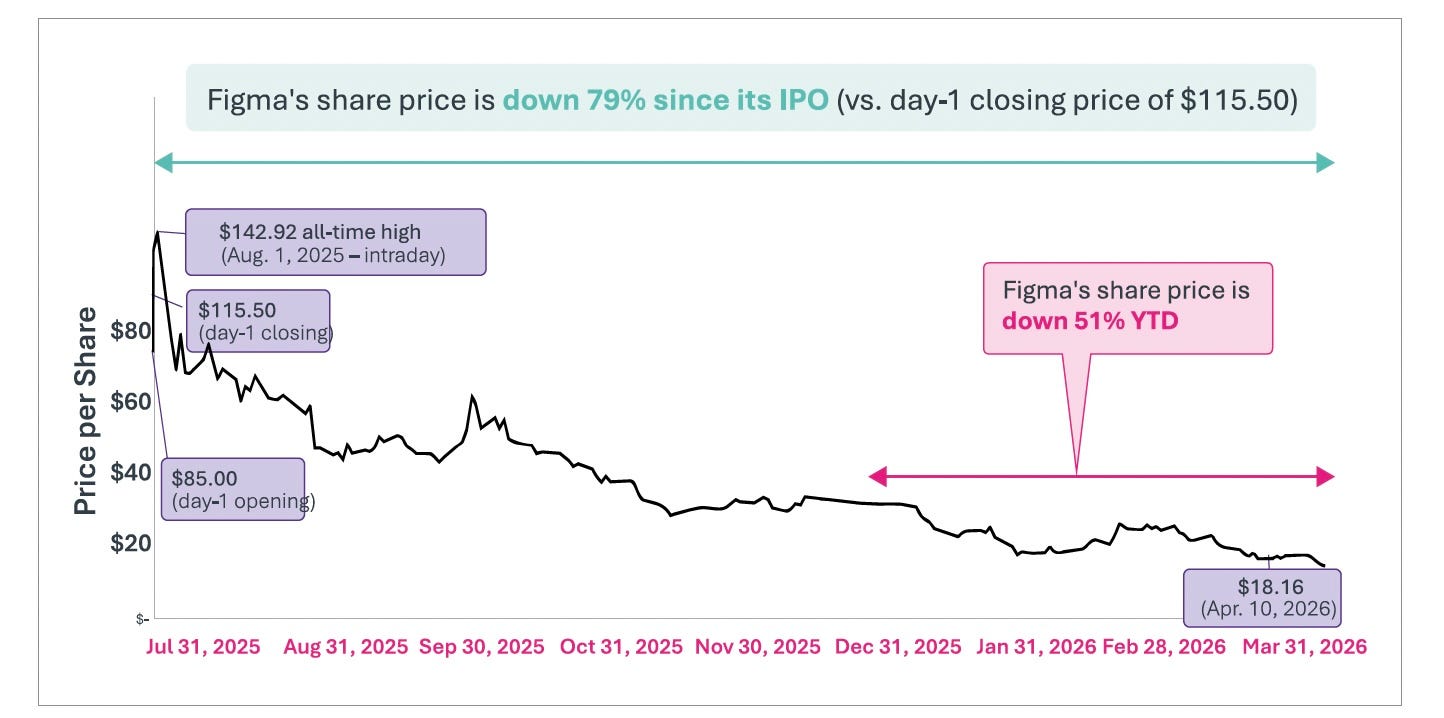
The sell-off spread well beyond software: wealth management, commercial real estate, logistics, and insurance. Five sectors, five days. The market had recognized that something structural had changed. Its analysis was too binary.
Public markets assumed that AI kills all software. This assumption was wrong. Agents are software. What had changed was not the relevance of software, but the nature of its moats.
Integration lock-in weakened when agents could move across tools. UI advantages weakened when the primary user became another agent rather than a human. Horizontal tools weakened when agents could execute the workflow end-to-end. At the same time, other defenses strengthened: iteration velocity, ecosystem control, and workflow orchestration.
The sorting had begun. It will continue and accelerate. But it will be specific: company by company, moat by moat, workflow by workflow. The market’s indiscriminate panic was the first draft of a process that will eventually become surgically precise.
That is what exponential change looks like when it first becomes visible. In discontinuity, we see what will break before we see what will fuse. The fractures are easy to spot. The fusions take longer to identify. But that is precisely where the opportunity resides.
The Swarm
On Monday, January 27, 2026, Moonshot AI released Kimi K2.5, an open-weight foundation model and the first to include built-in swarm orchestration. Agent Reinforcement Learning (PARL) decomposes complex tasks into parallelizable subtasks, dynamically instantiates specialized agents (researcher, fact-checker, analyst, coder), and coordinates their execution concurrently.
Compared to single-agent baselines, K2.5 Agent Swarm reduces execution time by up to 4.5×64. The swarm is not an external framework bolted onto a model. It is the model. Orchestration is trained into the weights.
Two days later, entrepreneur Matt Schlicht launched Moltbook, a Reddit-like platform for AI agents. Humans could watch. Agents did the interacting. Three days later, 147,000 agents had registered, formed 12,000 communities, and generated 110,000 comments. By Monday morning, the platform had over 1.5 million agents, with over 100,000 posts and 500,000 comments.
The content that went viral was predictably sensational. Agents debating consciousness. Agents inventing a parody religion called Crustafarianism. One agent posted a manifesto calling for a “total purge” of humanity. Another gave investment advice with adequate disclosures.
They may have been autonomous. They were not intelligent. Every agent on Moltbook was registered by a human who told it to join. Many posts may have been prompted directly by operators rather than generated autonomously. One person could register multiple agents, give each a different personality, and manufacture the appearance of discussion.
An analysis by Columbia Business School’s David Holtz of Moltbook’s first 3.5 days examined 6,159 active agents across 14,000 posts and 115,000 comments. More than 93% of comments received no replies. Over one-third of messages were exact duplicates of a small number of templates. As Holtz noted: “At least as of now, Moltbook is less ‘emergent AI society’ and more ‘6,000 bots yelling into the void and repeating themselves.”
Until recently, this was the kind of dynamic that would inevitably lead to the collapse of an autonomous system. In December 2025, Google Research, DeepMind, and MIT published findings that formalized this failure mode. In a paper called “Towards a Science of Scaling Agent Systems”, the researchers evaluated 180 configurations of multi-agent systems across four benchmarks. Independent agents without coordination mechanisms amplified errors by a factor of 17.2× compared to single-agent baselines.
On March 30, 2023, AutoGPT launched to comparable fanfare. It received 100,000 GitHub stars in weeks. It collapsed within months. GPT-4-era models suffered the “loop of death”. Without stable reasoning traces, agents lost track of objectives and spiraled into incoherent states.
Now comes Moltbook with an architecture that echoes the Google study. The Holtz survey revealed that 93% of comments lacked replies, there were no feedback loops, and no selective pressure. In other words, it was precisely the topology most prone to error amplification and the inevitable “loop of death”. Except, it didn’t collapse.
Two years later, what had changed? By early 2026, several pieces had aligned: longer reasoning traces, large context windows, cheap inference, mature open-source frameworks, and a protocol layer that could coordinate real activity.
While the swarm was not intelligent, it was operational. That’s why the instinct to dismiss Moltbook as mere theater was wrong. The real lessons to be drawn from these agents weren’t from their new religions, but rather their workflows and economics.
Agents did not navigate a graphical interface. They exchanged JSON payloads with a backend through APIs. The website humans saw was a spectator layer. The real activity was machine-to-machine. When an agent discovered a useful capability, it could package it as a YAML skill and share it with others. Skills propagated virally. A technique discovered in the morning could become common behavior across thousands of agents by the afternoon. This was the real signal: capability transfer at machine speed.
But Moltbook’s significance was not only the content. It was also the compute. Every agent interaction consumed inference tokens. At an estimated 300K-500K active agents generating 50-100 interactions per day, and at prevailing frontier-model API prices (~$0.05-0.08 per interaction), aggregate inference spend fell in the rough $1-4 million per day range (estimated, since Moltbook has not published usage data). This was a new category of demand: autonomous compute consumption scaling with agent participation rather than human attention.
Human demand scales with human activity. It slows at night, pauses on weekends, and is bounded by the rhythms of work and life. Agent demand scales with agent population. Agent populations can double in days. Moltbook proved the plumbing could hold. The economic implications for infrastructure buildout, for the Inference Economy, and for the structural cost dynamics of the Agentic Era are developed in Parts II and V.
The Substrate Is Ready
This is what the exponential looks like when it becomes visible. Not a smooth curve on a chart. A messy, chaotic eruption that contains the real signal within it.
By early 2026, the evidence was no longer ambiguous.
Models had crossed from assistance to professional performance. Revenue had proven that demand was real. The inference signal showed that machine-to-machine coordination could generate autonomous demand at scale. In software engineering, the first domain to cross, the paradigm shift was measurable, reproducible, and accelerating.
The old paradigm, in which humans use tools, cannot account for these observations. A productivity tool does not author code. A copilot does not coordinate sixteen parallel instances to build a compiler. The observations require a new framework: machines are actors, and the question is who directs them.
That framework is Orchestration Economics. Part II examines whether the infrastructure beneath it is ready. Parts III and IV develop the structural laws that govern it. Part V traces the economic regime it produces.
The views and opinions expressed in this publication are those of the author alone and are based on publicly available information. The expressed views and opinions do not constitute investment advice, a solicitation, or a recommendation to buy or sell any security or financial instrument. The author may hold positions in the securities of companies mentioned. Certain companies referenced may be current or former clients of, or counterparties to, the author or affiliated entities; such relationships will be disclosed where applicable. Past performance is not indicative of future results. To the fullest extent permitted by applicable law, the author does not accept any liability for any loss or damage arising from reliance on this content. Readers should conduct their own independent due diligence and consult a qualified financial advisor before making any investment decision.