
The Layer: Why the "LLMs Are A Dead-End" Consensus Is Premature
As insiders warn scaling is hitting limits, breakthroughs in verified AI systems and new multi-agent coordination suggest the generative paradigm isn’t collapsing, but evolving through a new “layer.”


The consensus that LLMs are a dead end toward AGI is hardening fast. Former Meta Chief AI Scientist Yann LeCun just raised a $1B seed round to replace them, and even OpenAI CEO Sam Altman now admits scaling won’t reach AGI. But two very recent developments suggest the obituary is premature. Axiom Math is producing verified proofs of unsolved mathematical conjectures by co-designing AI with formal verification. It just raised a $200m Series A at a $1.6 billion valuation. A new paper shows that the vision pathway of frozen vision language models (VLMs) can be repurposed as a communication channel between heterogeneous agents, delivering faster and often more accurate coordination than text. Neither result was supposed to be possible with the generative paradigm. Both were achieved by engineering a “layer” above it. The architecture may have a ceiling. But we are nowhere near it yet.
In the span of forty-eight hours last week, two major AI funding rounds crystallized a disagreement the technology industry has, until now, largely avoided confronting. The stakes are higher than either side acknowledges.
On March 10, Advanced Machine Intelligence (AMI), the startup co-founded by Turing Award winner Yann LeCun, raised $1.03 billion in what is believed to be the largest seed round ever completed by a European startup. Valued at $3.5 billion, the company intends to build AI systems based on “world models” that learn from the continuous reality of the physical world rather than from text. The company’s slogan reads: “Real world. Real intelligence.”
Two days later, Axiom Math raised $200 million at a $1.6 billion valuation to pursue a different bet: that AI systems can be built from the ground up to generate formally verified mathematical proofs and provably correct code, co-designing generation and verification as a single architecture rather than treating them as separate problems.
This article is not principally about either company or about the world-models paradigm as such. It is about what these simultaneous bets, taken together with a striking research result, reveal about the state of LLMs at a moment when even their most prominent champions are conceding the limits of scale.
AMI reflects a theory of intelligence: that true intelligence must be grounded in the physical world, and that language alone is an insufficient substrate. Axiom reflects a different strategy: not redefining intelligence but identifying where it can first become reliable.
In its case, that wedge is code, where correctness is binary and can be formally verified.
Both are attempts to solve the intelligence problem. But they proceed in opposite directions: one begins from a theory of what intelligence must be, the other from where it can already work.
But the more important question is not about either company alone
It is whether the generative paradigm that both are reacting to has truly exhausted its usefulness, or whether the emerging consensus against it has formed too early.
The intellectual divide is genuine.
LeCun has argued for years that the autoregressive architecture that powers ChatGPT, Claude, Gemini, and virtually every commercially deployed language model is fundamentally limited. Because the model samples from a probability distribution at every step, a single early mistake can shift the context, causing subsequent predictions to diverge exponentially.
The inevitable hallucinations that result are not bugs to be patched. They are mathematical properties of the architecture.
“Pure Auto-Regressive LLMs are a dead end on the way towards human-level AI,” LeCun wrote in September 2024. “But they are still very useful in the short term.”
That second sentence tends to get lost in the noise. However, it is precisely where the most interesting argument begins.
The prevailing view in much of the enterprise world has tilted toward LeCun’s position, if not always in so many words. Despite extraordinary investment in AI infrastructure, most large organizations remain in pilot mode when it comes to generative and agentic AI. CIOs cite reliability concerns more than any other factor when explaining stalled deployments, and the deterministic vs probabilistic debate takes center stage. The technology is impressive in demonstrations and unreliable in production. The gap between those two experiences has hardened into institutional caution.
What is less often acknowledged is how quickly this skepticism has calcified into something closer to consensus.
In boardrooms and investment committees, the phrase “LLMs hallucinate“ has become a conversation-stopper. It’s a shorthand that collapses a complex architectural debate into a binary judgment. The nuance of “useful in the short term, limited in the long term” has been flattened into a simpler story: the technology does not work. This matters because consensus, once formed, tends to determine where capital flows and where it does not well before the underlying evidence has settled.
The question, then, is not simply whether the emerging consensus is correct. It is whether the consensus is evaluating the right thing.
The evidence emerging from Axiom and a recent paper in multi-agent AI suggests that the problem may not be the generative paradigm itself, but in how we have chosen to assess it: model in isolation, rather than model in system.
The stakes of this debate extend well beyond academic architecture disputes.
Over the past three years, governments and companies have committed hundreds of billions of dollars to infrastructure designed around large language models: data centers, GPUs, software platforms, and enterprise workflows built on generative systems. If the autoregressive paradigm truly is a technological cul-de-sac, much of that investment becomes transitional, a stepping stone toward a different kind of AI architecture.
But if generative models remain structurally useful when embedded in the right systems, the implications are very different.
In that case, the next phase of progress may come less from replacing the models themselves than from engineering the layers that make them reliable, coordinated, and economically useful.
These cases point to the importance of what I would call the “Layer”: an engineered stratum, whether built into a system from the ground up or added on top of existing models, that unlocks capabilities generative models cannot achieve on its own, from verified output to coordinated multi-agent intelligence.
The model produces probabilistic capability. The Layer turns that capability into something more durable: reliability, coordination, and use.
These are still early results. But they suggest that the relevant question is no longer whether generative AI works on its own. It is whether, with the right layer around it, it can do far more than the current narrative allows.
In modern AI systems, capability may increasingly emerge not from the model alone, but from the layers engineered around it.
The Verification Layer
Begin with the problem that has done the most to entrench enterprise skepticism: the hallucination problem.
When a language model generates code for a financial trading system, the output either works correctly or it introduces a vulnerability that cascades through infrastructure. When it writes software for a medical device, the function either returns the right answer every time or it does not. In neither case does “usually right” suffice. This is the gap that has kept most large enterprises in pilot mode. Not a lack of capability, but a lack of trust.
Menlo Ventures’ partners Matt Kraning and C.C. Gong, who led Axiom’s round, framed the opportunity in language that crystallizes the tension:
“Large language models generate code that looks right. It compiles, it often passes tests, and it frequently works. But “frequently works” is a terrifying standard for the systems that run our infrastructure, manage our finances, and protect our data. LLMs are statistical by nature - they produce plausible outputs, not provably correct or safe ones. They can’t guarantee a function returns the right answer, and they can’t guarantee it doesn’t introduce a security vulnerability in the process. This isn’t a bug that will be fixed with the next model generation. It’s architectural. Hallucinations and unsafe code from AI are not going away.”
That last sentence is the one that matters. Read it as a supporter of AMI, and it confirms that the architecture must be replaced. Read it as Axiom does, and the conclusion is different. If hallucination is architectural, then you do not wait for a better model. You build the layer that makes hallucination irrelevant.
Axiom’s approach, however, is not to wrap an existing language model in a verification shell. It is more ambitious than that.
The company is building its own AI systems from the ground up, co-designing generation and formal verification as a single integrated architecture. Axiom trains its models to generate natively in Lean, a programming language designed for mathematical proofs, where every logical step is machine-checkable against formal rules. A deterministic proof verifier then certifies every output.
If a proof is valid, it is logically guaranteed. If it contains an error, the verifier catches it. Every time.
Generation and verification are not bolted together as afterthoughts. They are architected as one system.
Madrona Ventures, which invested in Axiom’s seed round, described the philosophy like this: “Carina and Axiom recognize that this shift is so tectonic it requires ground-up thinking, not incremental improvements to existing architectures.”
This is no patch for the generative shortcomings. It is a new kind of AI system in which the verification layer is native and baked into the architecture from the start.
The results, thus far, are concentrated in mathematics and code. But within those domains, they are striking.
In December, Axiom reported that its system achieved a perfect score on the Putnam Competition, regarded by mathematicians as the world’s most demanding undergraduate exam. Only five humans have accomplished the same in the last century.
It also produced a verified proof of a 20-year-old number theory conjecture that Ken Ono, Axiom’s founding mathematician and one of the world’s foremost authorities on Ramanujan’s mathematics, had tried and failed to solve himself across years of repeated attempts. These results, achieved under conditions of mathematical rigor that admit no ambiguity, suggest that co-designing generation with formal verification can reach places that neither approach alone could.
The compounding mechanism is equally noteworthy. Every verified output feeds back into training as proof-checked data, avoiding the model collapse that degrades systems trained on their own unverified outputs.
It is a recursive improvement loop with a built-in quality guarantee. This is what Axiom calls a “verified data flywheel.“ And because the data is deterministically verified, the loop scales with compute rather than with the availability of human-generated training material.
For enterprise adoption, the implications deserve careful consideration. The industry has tried other approaches to the reliability problem, including retrieval-augmented generation, fine-tuning, and human-in-the-loop review. Each helps. None provides a mathematical guarantee.
Axiom’s verification layer, if it can scale beyond its current domain, offers something qualitatively different: not a reduction in error rate but an elimination of unverified output.
Important caveats apply.
Axiom’s results are concentrated in domains with formal, machine-readable rules where the definition of “correct” is unambiguous. Much of what enterprises need operates where correctness is subjective.
The verification layer for human judgment is a categorically harder problem. There are also open questions about computational overhead and adversarial robustness. These are reasons to track the approach with rigor rather than hype.
But within the domains where formal verification is native, the proof of concept is substantive. As the Menlo Venture partners also wrote about Axiom:
“AI code generation will soon encompass virtually all software development. Axiom is building the correctness-and-safety layer for that future. It’s one of the most differentiated positions in the AI coding ecosystem we’ve encountered.:
Code is not incidental here. It is the wedge.
Software engineering is one of the few domains where correctness is formally definable, feedback is immediate, and the economic stakes are high. That makes it the first environment where the verification layer can operate at scale.
Success here is not just a technical milestone. It is the entry point through which generative systems earn trust across the enterprise. It is so strategically important that I refer to it as “The Coding Wedge.” It has become the key battlefront for LLMs.
The Perception Layer: Solving the Coordination Bottleneck
The verification layer addresses the enterprise trust problem. But the “LLMs are a dead end” thesis is being challenged on a second front: not model reliability, but the architecture of multi-agent systems.
The agentic AI systems now emerging in enterprise environments are increasingly heterogeneous. They combine models from different providers: Qwen for one task, Gemma for another, and specialized, smaller models for latency-sensitive operations.
They are coordinated through orchestration frameworks. The standard approach requires agents to communicate by generating text: each agent decodes its internal reasoning into words, which the next agent re-encodes into its own representational space. The process is slow, lossy, and expensive.
It has become the principal coordination bottleneck in multi-agent systems.
In February, researchers at Purdue, Carnegie Mellon, and Georgia Tech proposed a striking alternative in a paper titled “The Vision Wormhole” (Liu et al., 2026).
Every vision-language model (LLM + vision) has a visual pathway: a vision encoder and projection layer designed to process images. Unlike the discrete tokens used in text-only LLMs, this pathway is trained to accept continuous, dense embeddings.
This distinction matters. Text transformers operate on discrete tokens; injecting arbitrary continuous vectors typically produces unstable outputs. The visual pathway, by contrast, is already trained to interpret continuous signals. It is a representational manifold that the model knows how to read.
The researchers’ insight is to repurpose this pathway. Not as a sensory organ, but as a communication interface between agents.
When one agent completes its reasoning, a lightweight codec, roughly 50 million parameters in size, compresses its internal reasoning trace into a fixed set of universal tokens. These tokens are then injected directly into the receiving model’s visual pathway as if they were image embeddings. The receiving model, whose backbone remains frozen, processes these “vision” tokens alongside its prompt and produces its response.
No text is generated between agents. No model weights are modified.
The system adopts a hub-and-spoke architecture that maps each model family to a shared latent space. Instead of training pairwise translators between every pair of models - a process that scales quadratically - each new model learns a single lightweight mapping to the shared space, reducing integration complexity from O(N2)O(N^2)O(N2) to O(N)O(N)O(N).
Across nine benchmarks, the results are striking.
In controlled benchmark experiments, heterogeneous teams of relatively small models communicating through the Vision Wormhole achieved an average accuracy gain of roughly 6.3 percentage points compared with text-based multi-agent collaboration, while running about 1.87 times faster. On competition mathematics benchmarks, the speedup reached 5.47 times, and on code generation tasks, the approach improved accuracy by an average of 13.2 percentage points.
Whether the approach scales to frontier-sized models in production and whether the codec remains stable across longer workflows remains to be demonstrated. The authors also note that certain role-assignment configurations yield weaker results. These are the normal uncertainties of early-stage research.
But the directional signal is clear: the visual pathway can function as a high-bandwidth communication channel for heterogeneous agents.
The coordination problem of how to get models from different families to collaborate effectively has been one of the open infrastructure questions in the agentic stack. The Vision Wormhole suggests a promising direction: use the visual pathway that already exists in every major VLM as the coordination channel.
If the approach generalizes, the perception layer would not merely give agents eyes. It would give them a shared nervous system.
The structural relationship with Axiom Math is instructive, though the approaches differ in important ways.
Axiom builds its verification layer into the architecture from inception. Generation and verification are co-designed as one system. The Vision Wormhole, by contrast, adds a perception layer on top of existing frozen models, leaving the VLMs untouched.
One builds the layer in. The other builds the layer on.
They address different constraints: Axiom tackles the gap between probabilistic generation and provable correctness, while the Vision Wormhole addresses the gap between isolated models and coordinated intelligence.
But both approaches share the same structural insight. They introduce a new layer in the stack that unlocks capabilities that the base models cannot produce on their own.
In both cases, it is the layer, not the model, that produces the breakthrough.
The implications for agentic AI are significant.
The Layer
The pattern now has enough evidence to name. It is early evidence, but structurally consistent. I propose calling it the “Layer.”
Axiom illustrates one form of it. By building a verification layer directly into the architecture, using a formal mathematical proof co-designed with the generative system, it produces provably correct output that the model alone could only produce as plausible.
The Vision Wormhole illustrates another. By adding a perception layer on top of frozen VLMs, it enables high-bandwidth multi-agent coordination where the models alone could only communicate through slow, lossy text.
The approaches differ. Axiom builds the layer in. The Vision Wormhole builds the layer on.
They solve different problems. But the structural insight is the same. In both cases, it is the layer that produces the capability that matters.
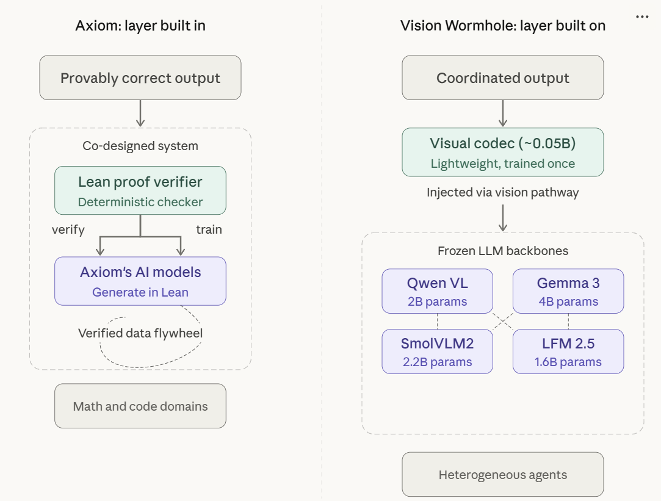
The general pattern can therefore be defined as the Layer: an engineered stratum that enables capabilities generative AI systems cannot achieve on their own, whether that means verified output, grounded perception, or coordinated intelligence.
Sometimes the layer is co-designed from inception, as Axiom does. Sometimes it is added on top of existing frozen models, as the Vision Wormhole demonstrates. The form varies. The function is consistent: the layer extracts value from generative AI that the models, left to their own devices, cannot deliver.
This may seem like a semantic distinction. It is not.
The difference between evaluating a model in isolation and evaluating a system - model plus layer - is the difference between concluding that generative AI has hit a ceiling and recognizing that the ceiling keeps rising as new layers are engineered on top of it.
The first conclusion leads to the boardroom consensus described earlier: wait for something better or fund a replacement.
The second leads to a different posture: build the layer now, using the AI that exists.
For readers of Decoding Discontinuity, this should resonate with the orchestration thesis:
“Orchestration occupies the position where layers converge. Intent is decomposed, agents are coordinated, outputs are validated, and context accumulates. Orchestrators learn which layers work for which tasks, which combinations produce reliable results, and which error patterns require intervention.”
The orchestration position sits within the Layer of the broader agentic stack.
Orchestrators sit where layers converge. They learn which layers work for which tasks, which combinations produce reliable results, and which error patterns require intervention.
But this relationship introduces an important selection pressure. If a layer becomes too expensive, the orchestrator may route tasks around it when the cost of error is low. Layers persist where the cost of failure exceeds the cost of the layer itself.
The thesis is strongest where consequences are most severe.
The alternative, and what remains unsettled
AMI’s thesis deserves serious engagement. Not because it is necessarily correct, but because the limitation it identifies is real.
This weekend, OpenAI CEO Sam Altman, whose company has invested hundreds of billions in the transformer architecture, acknowledged that reaching AGI will likely require “another new architecture,” comparable in impact to the leap from LSTMs to transformers. Fourteen months earlier, he had declared, “We now know how to build AGI.”
Other insiders are expressing similar doubts: Elon Musk recently admitted that xAI was “not built right,” Mark Zuckerberg has delayed Meta’s latest model, and several leading researchers, including Demis Hassabis, Ilya Sutskever, and LeCun, have all questioned whether scaling alone is sufficient.
The insiders are losing confidence in pure scaling. This matters. But it is important to be clear about what it means and what it does not.
Skepticism about scaling and the “LLMs are a dead end” thesis are related but distinct claims.
The first says: making models bigger and training them on more data will not, by itself, produce artificial general intelligence.
The second says: the generative paradigm has exhausted its usefulness and must be replaced by something fundamentally different.
Altman is endorsing the first claim. LeCun endorses both.
The distinction is critical because the evidence for the first is now substantial and growing. The evidence for the second is not.
The world-models field itself is not monolithic. Google DeepMind’s Genie 3 uses a generative approach, simulating environments frame-by-frame. Fei-Fei Li’s World Labs, which raised $1 billion in February, builds explicit 3D scene representations.
AMI sits in a third camp - abstraction-first - arguing that intelligence should learn compressed causal representations of physics rather than reconstruct sensory detail. LeCun’s Joint Embedding Predictive Architecture (“JEPA”) follows a similar principle, operating in latent space rather than generating full sensory outputs. Meta’s V-JEPA-2 has already demonstrated zero-shot deployment on physical robots for object manipulation using minimal training data.
Language models are trained on text, and text is a lossy compression of reality. There are aspects of physical causality and embodied understanding that may not be recoverable from language alone, no matter how many layers you engineer above the output.
World models may prove essential for capabilities that layered language models cannot reach, particularly in robotics and autonomous systems, where the long tail of unpredictable edge cases is vast and where reasoning about three-dimensional physical reality is not optional.
But scaling failing to produce AGI does not mean the generative paradigm is a dead end.
It means the paradigm has a ceiling. So the debate shifts to how high that ceiling is and how much value exists below it. The evidence from the Layer suggests that it’s more than the prevailing narrative implies.
Axiom’s verification layer already produces formally verified proofs using current-generation models, while the Vision Wormhole achieves multi-agent coordination up to 5.47× faster using models with 1.6-4 billion parameters.
Neither result depends on scaling continuing. Both depend on engineering the right layer above the models we already have.
If scaling continues, the Layer compounds: the substrate improves, and the layers built on top of it become more powerful.
If scaling stalls, the Layer still functions. It simply extracts value from a fixed capability base rather than a growing one.
The ceiling of the paradigm matters for AGI, but it matters less for whether current models, when properly layered, can produce results that enterprises and researchers can use. Even LeCun has described LLMs as “still very useful in the short term.”
The Layer suggests that “short term” may be longer than expected.
What, then, should we make of the growing cohort of AI-native startups built around LLMs, if generative architectures merely “mimic intelligence” and are best suited to “discrete and low-dimensional tasks like information retrieval, summarization, coding, and mathematics,” as AMI CEO Alexandre LeBrun has argued?
LeBrun himself offers a revealing example. He remains Chairman of Nabla, the clinical AI company he founded, which has raised $120 million and deployed its ambient documentation assistant across hundreds of health systems. It has done this precisely by applying LLMs to information retrieval and summarization.
If those are shortcuts, they have proven fundable, deployable, and clinically trusted enough to build a company on.
That raises a more important question: are these limitations or the foundation of something larger?
The debate, in other words, is no longer simply about models. It is about systems.
The market is funding both of these simultaneously. That is rational. Perhaps more rational than it was a week ago, now that even OpenAI’s CEO acknowledges the limits of the current paradigm. World models represent a legitimate alternative path, and AMI’s team has the credibility and capital to pursue it at scale.
But the Layer is now producing results, using existing infrastructure and available models.
The obituary for the generative paradigm may have been written too early.
What was needed was not a replacement.
It was a Layer.