
NVIDIA's CUDA Playbook Has a Second Act. One for the Agentic Era.
At GTC 2026, NVIDIA unveiled an open-source stack that could redefine the Agentic Era by positioning itself as the infrastructure beneath every enterprise agent, regardless of model or platform.


NVIDIA’s Agent Toolkit, unveiled at GTC 2026, is the company’s bid to become to the agentic era what AWS became to the cloud. The stack is open-source, and its ambition is infrastructural: rather than compete with Anthropic or OpenAI for ownership of the agent, NVIDIA is building the substrate beneath it. When Salesforce ships Agentforce, when SAP deploys Joule, when ServiceNow fields an agentic workflow, each can run on NVIDIA’s runtime, security, and data layer regardless of which model powers the intelligence above. The move arms SaaS incumbents against the model providers, threatening to absorb them, while creating two competing architectures that NVIDIA profits from equally. If model providers win, NVIDIA sells the chips. If incumbents orchestrate on NVIDIA’s stack, NVIDIA owns the hardware beneath and the plumbing between. The Agent Toolkit extends NVIDIA’s lock-in to the agent runtime layer, a new software layer for the agentic era. It is not a departure from the chip business. It is the chip business expanding its surface area upward.
When NVIDIA CEO Jensen Huang stepped onto the stage at the SAP Center in San Jose last Monday, he was wearing the iconic leather jacket as he launched into a marathon keynote that stretched almost 2.5 hours.
He dutifully name-checked LLM rivals Anthropic and OpenAI, made a string of product and partnerships and announcements, mentioned “agent” or “agentic” at least 44 times, and ended the spectacle by conversing with a robotic version of Frozen’s Olaf.
While the world knows NVIDIA as the company whose chips are powering the AI boom, Huang spent his time on stage doing his best to reframe the company as...something else, something more.
“We’re going to talk about platforms,” he said. “Nvidia has three platforms. You think that we mostly talk about one of them. We’re going to talk about all of them, and most importantly, we’re going to talk about ecosystems. This conference is going to cover every single layer of the five-layer cake of artificial intelligence, from the infrastructure to chips to the platforms, the models, and, of course...the applications.”
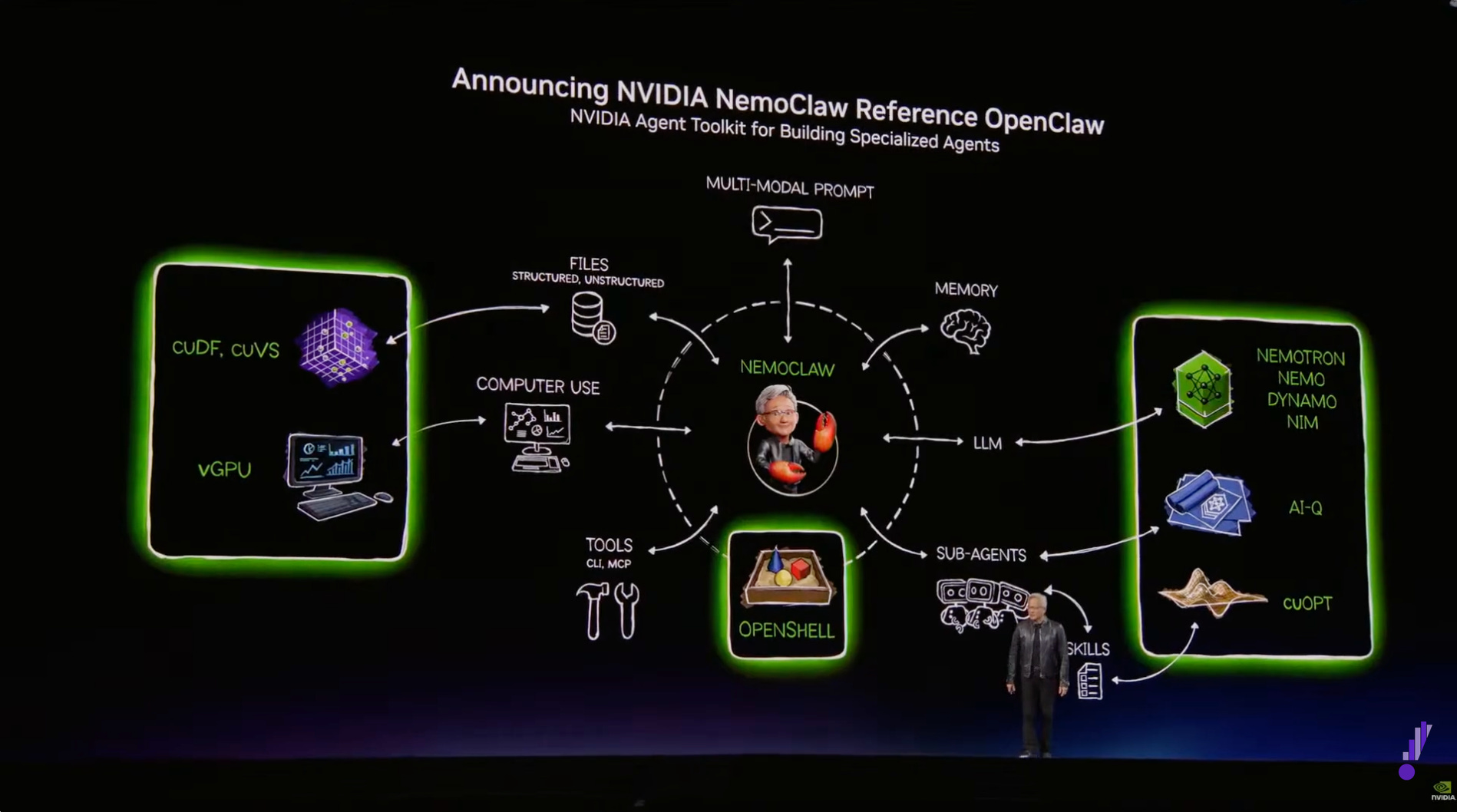
Tucked in between those layers, about two hours into the presentation, was a 4-minute wedge that sounded like a routine announcement. Something about a coalition of companies to advance open, frontier-level foundation models. And then, by the way, the company briefly unveiled an open-source software toolkit for building AI agents that had already been embraced by enterprise software companies, including Adobe, Salesforce, SAP, ServiceNow, Atlassian, Siemens, CrowdStrike, and Palantir. There were new models, a new security runtime, and a new data architecture.
Because the NVIDIA Agent Toolkit was barely a blip, it was easy to miss the bigger significance: A direct challenge to Anthropic and OpenAI, the two companies widely expected to dominate the Agentic Era.
NVIDIA has become the indispensable substrate for AI computation. The Agent Toolkit is a bid to make NVIDIA just as indispensable at the runtime layer where enterprise agents are deployed, governed, and connected to data. It is a move to become the AWS of AI agents, the company that provides the infrastructure on which all AI agents run, regardless of which model powers them and which platform deploys them.
NVIDIA stock rose 1.7% on the day of the keynote, then drifted lower for the rest of the week amid broader macro pressures and the Iran-driven oil shock. Sell-side analysts focused on the $1 trillion order backlog for Blackwell and Vera Rubin chips. Naturally, the open-source Agent Toolkit, which would generate zero direct revenue, did not feature in their models.
The toolkit announcement deserved considerably more attention. But when it comes to NVIDIA, such oversight is not without precedent.
In 2006, NVIDIA released its Compute Unified Device Architecture (CUDA), which enables developers to write software that performs computationally intensive tasks on its GPUs. At the time, NVIDIA was a specialized hardware company whose primary business was its processors for gaming PCs. While CUDA, when it was announced, appeared to be just a niche product from a second-tier chip company, it turned NVIDIA’s chips from graphics processors into the computational backbone of modern AI.
It took nearly a decade before CUDA’s role as the substrate of the deep learning revolution became clear. No analyst in 2006 had a line item on their NVIDIA forecast for “future AI training demand enabled by a free parallel computing toolkit.”
And yet, as Huang opened his keynote, CUDA was topic number one.
“It all began here,” he said. “This is the 20th anniversary of CUDA. There are a couple of hundred thousand public projects. CUDA literally is integrated into every single ecosystem.”
In that sense, the timing of the Agent Toolkit introduction may have been perfect.
NVIDIA has moved from a specialized hardware company to a dominant platform company thanks to CUDA. Now, with Agent Toolkit, the company has signaled it intends to further migrate to an infrastructure-as-a-platform player in the Agentic Era. The GPU business remains. The software infrastructure business allows to sell even more GPUs. A new moat emerges, or so NVIDIA hopes.
The difference is that this time, the outcome will not unfold over a decade. It will be decided in the next few years (or months, given the pace of Agentic AI progress?). And it will determine whether the agentic economy is controlled by the companies that build intelligence, or by the one that builds the system it runs on.
To understand what NVIDIA is really attempting, and whether it can work, we need to start with how the ground shifted beneath it.
How We Got Here
For the past three years, NVIDIA has been the kingmaker of the AI era. Its GPUs became the scarce resource that determined who could train frontier models, who could scale them, and ultimately who could compete. At its peak, the company briefly became the world's most valuable. It did that not by owning the models or the applications, but by supplying the computation on which everything else depended.
But that position, while still extraordinarily strong, is no longer unassailable.
Over the past eighteen months, a series of technical, architectural, and competitive shifts has begun to erode the assumption that AI must run on NVIDIA’s terms. The moat has not disappeared. But it is being tested from multiple directions at once.
One of the first cracks appeared in January 2025 with the release of DeepSeek’s R1 model. NVIDIA had benefited from the belief that building frontier models required enormous capital, vast GPU clusters, and was the province of a small number of Western labs.
DeepSeek broke that assumption. Its architectural innovations reduced memory by over 90% and manifold-constrained hyper-connections, stabilizing training at 6,7% additional overhead. These mathematical breakthroughs changed the relationship between investment in computing and model capability. NVIDIA lost close to $600 billion in market capitalization in a single day.
Over the next year, multiple labs built on similar architectural innovations to reach the frontier. By early 2026, DeepSeek V3.2 was matching GPT-5 on mathematical reasoning at a fraction of the API cost. What made AI agents practical at scale was a convergence: algorithmic efficiency that allowed powerful models to run on modest hardware; inference-optimized serving infrastructure that made deployment economical; and open model weights that removed licensing barriers.
Out of the convergence, a consensus formed rapidly. If agents were the new software, the companies controlling the most capable models would control the platform. Anthropic and OpenAI were the presumptive winners. They had the frontier models, the emerging coordination protocols (Anthropic’s Model Context Protocol (MCP), Google’s Agent-to-Agent (A2A)), and the first production-ready agent products. The SaaS incumbents were destined to become downstream API endpoints.
At the same time, a second, more structural threat was emerging, one that challenged NVIDIA more directly.
Google’s Gemini 3 demonstrated that frontier models could be trained entirely on custom silicon, without NVIDIA GPUs, while matching or exceeding leading models on key benchmarks. More importantly, it validated a different competitive architecture: full-stack integration across chips, models, infrastructure, and distribution. The implication was not just another strong model. It was a proof point that the largest players in AI could reduce their dependence on NVIDIA altogether.
For the first time in over a decade, NVIDIA’s dominance was no longer anchored in an uncontested assumption.
But the company has not survived and dominated multiple computing transitions by accident. Huang arrived in San Jose to propose an entirely different architecture.
What NVIDIA Built

The Agent Toolkit has four components, designed to work as a system that creates and manages AI agents:
Nemotron models are NVIDIA’s open-source language models, optimized for agentic workloads. They are not designed to match Claude Opus 4.6 or the GPT-5 family on frontier reasoning. They are designed to handle the bulk of enterprise agent tasks at a fraction of the cost of frontier agents. NVIDIA used Nemotron within its AI-Q architecture to top both the DeepResearch Bench and DeepResearch Bench II accuracy leaderboards, demonstrating that open models paired with sophisticated retrieval infrastructure can compete with frontier systems on enterprise search tasks. The Nemotron Coalition includes Mistral AI, Black Forest Labs, Cursor, LangChain, Perplexity, Reflection AI, Sarvam, and Thinking Machines Lab. They will co-develop the Nemotron 4 base model on NVIDIA DGX Cloud.
OpenShell is an open-source runtime that enforces policy-based security, network isolation, and privacy guardrails for autonomous agents. Agents operate within process-level sandboxes governed by YAML policy files controlling file, network, and API access. Cisco, CrowdStrike, Google, Microsoft Security, and Trend Micro are building direct compatibility with their security platforms. As NVIDIA’s VP of generative AI software, Kari Briski, put it, OpenShell provides “the missing infrastructure layer beneath claws.”
AI-Q Blueprint is a full-stack architecture for connecting agents to enterprise data: ingestion and indexing via NVIDIA NeMo Retriever at up to 15 times conventional speed and petabyte scale, a vector database, a retrieval-augmented generation pipeline, and a hybrid model-routing system that sends complex orchestration tasks to frontier models and routine research tasks to Nemotron, cutting query costs, according to NVIDIA, by more than 50%.
AI-Q is also where NVIDIA makes its most precise move against Anthropic. The toolkit is compatible with MCP but does not depend on it. The intelligence about which data to retrieve, how to route queries, and which model to use for which sub-task lives within AI-Q’s own architecture. MCP is treated as one connectivity option among several. This matters because MCP was Anthropic’s bid to become the foundational protocol of the agentic era, and it has achieved remarkable adoption, with Amazon, Microsoft, Google, and OpenAI all supporting it. But AI-Q does not displace MCP. It subsumes its strategic function, reducing it from an architectural foundation to a compatibility feature. OpenShell, meanwhile, addresses the enterprise governance gaps, including audit trails, SSO authentication, and policy enforcement. These are elements that MCP’s own 2026 roadmap acknowledges remain unresolved, and that security researchers have identified as significant vulnerabilities.
NemoClaw packages the open-source personal agent framework OpenClaw, which, within weeks of its January 25 launch, became one of the fastest-growing repositories in GitHub history, with Nemotron models and OpenShell security in a single deployable stack. Enterprise-grade access controls, audit logging, and data residency compliance are included. Its full implications become clear in context.
Together, these form a full-stack runtime layer for enterprise agents, one that sits beneath any model and any application and captures value from both.
NVIDIA as the Hyperscaler of Agentic AI
The strategic logic of the toolkit is not orchestration. NVIDIA is not competing with Claude or Agentforce to coordinate enterprise workflows.
It is building the infrastructure beneath every orchestrator.
The analogy is AWS. Amazon did not build the best web applications. It built the compute, storage, and networking on which all web applications ran, and captured a disproportionate share of value because every application, regardless of creator, generated demand for Amazon’s underlying services.
NVIDIA is making the same structural play for agents. Every Salesforce agent running Nemotron, every SAP workflow orchestrated through OpenShell, every ServiceNow specialist accessing data through AI-Q generates demand for NVIDIA silicon. The agents compete. NVIDIA collects from all of them.
This is the CUDA playbook applied one layer higher.
CUDA did not need to be the best deep learning framework. It needed to be the execution environment for every framework.
The Agent Toolkit extends this logic from training and inference to the agent layer itself. Like AWS, it potentially expands the total market by lowering the barriers to building and deploying agents while ensuring NVIDIA’s hardware sits beneath every new deployment. The toolkit is already available on build.nvidia.com, with support across AWS, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure.
But there is a critical difference between selling GPUs and owning the software infrastructure layer. NVIDIA has always captured value from AI through hardware, regardless of who builds the model or deploys the application; the computation runs on NVIDIA chips. The Agent Toolkit does not change that.
What it adds is a second, more ambitious claim: that NVIDIA’s runtime, security framework, and data pipeline become the standard substrate for building and deploying enterprise agents.
The Fight for the Orchestration Layer
To understand the stakes, reduce the competitive landscape to what it actually is: two architectures competing for the orchestration layer:
Architecture A: The model is the orchestrator. This is the post-SaaSpocalypse consensus. Anthropic’s Claude or OpenAI’s GPT coordinates all agent workflows by capturing goals, decomposing tasks, routing sub-agents, and governing execution. Value concentrates at the intelligence layer. SaaS incumbents become API endpoints. NVIDIA sells GPUs but does not capture the software infrastructure layer.
Architecture B: the SaaS incumbents are the orchestrators. They run on NVIDIA’s infrastructure. Salesforce, SAP, and ServiceNow deploy their own agents through NVIDIA’s toolkit, using their context moats to differentiate, with models as swappable components beneath them. Value concentrates at the data and workflow layer for the incumbents, and at the infrastructure layer for NVIDIA. NVIDIA captures both hardware and the software stack.
In both architectures, NVIDIA sells GPUs. But Architecture B is dramatically better for NVIDIA because it also captures the entire software infrastructure layer: runtime, the data pipeline, and the security framework. The Agent Toolkit is NVIDIA’s play to make Architecture B win.
And it has handed the SaaS incumbents the tools to fight for it.
In this new configuration, Salesforce’s reference architecture deploys Agentforce agents with Slack as the orchestration layer, powered by NVIDIA infrastructure, accessing CRM data through AI-Q in both cloud and on-premises environments. SAP connects Joule agents to ERP data with a Foxconn collaboration demonstrating manufacturing optimization on data that cannot leave the factory floor. ServiceNow’s “Autonomous Workforce of AI Specialists” combines the Agent Toolkit with its own Apriel models. IQVIA has already deployed more than 150 agents, including at 19 of the top 20 pharmaceutical companies.
AI-Q specifically enables what I call the “context moat.” This is the proprietary, accumulating data that creates compounding advantages for platforms embedded in enterprise operations over decades. When Salesforce agents access customer interaction histories and pipeline progressions through AI-Q, that data stays within Salesforce’s perimeter. It does not flow through a third-party model provider’s API. NVIDIA services the incumbents’ existing data advantages on its own infrastructure, a proposition far more attractive to enterprise CIOs than routing sensitive operational data through Anthropic.
Within this coalition lies a component that partly invalidates one of its core advantages. NemoClaw deserves the closest reading from the incumbents who signed on.
When the SaaSpocalypse struck, the incumbents’ most vocal defense was governance, security, and enterprise trust. Enterprise software companies argued that enterprises would not entrust autonomous agents to a startup’s API, that they needed compliance frameworks, data sovereignty guarantees, and institutional reliability that only established platforms could provide. This was their strongest card.
NemoClaw partly commoditizes that defense. By packaging enterprise-grade security, including role-based access controls, audit logging, data residency compliance, and process-level sandboxing, into an open-source personal agent stack, NVIDIA has made the incumbents’ stated moat freely available. Any organization deploying NemoClaw gets the governance infrastructure that Salesforce, ServiceNow, and SAP claimed as their competitive advantage without a platform license. NemoClaw is not model-exclusive; it runs agents powered by OpenAI and Anthropic alongside Nemotron.
NVIDIA is simultaneously arming incumbents for the fight against model providers and lowering the barriers that have protected them from others. It propels them forward while narrowing the ground beneath their feet.
Why the Frontier Still Makes the Model the Orchestrator
Can the SaaS incumbents actually win the orchestration layer with the tools NVIDIA has provided? There is a powerful technical argument that, even in Architecture B, the model provider retains control of the most valuable step and therefore remains the de facto orchestrator, regardless of the org chart.
The argument begins with how NVIDIA’s own hybrid design works. AI-Q routes “frontier models for orchestration and NVIDIA Nemotron open models for research.” This is presented as cost optimization. It is also an architectural concession. The orchestration step is the one NVIDIA itself acknowledges requires frontier-quality. This includes the planning, decomposition, multi-step coordination, and error recovery. But the orchestration step is precisely where value is concentrated, because it is where errors compound, and quality differences determine outcomes.
Model quality in agentic workflows does not degrade gracefully. An agent either completes a fifteen-step workflow correctly, or it makes an error on step seven that propagates silently through the remaining eight steps, producing a result that looks right but is wrong. The difference between a model that gets each step right 95% of the time and one that achieves 99% is not four percentage points. Over fifteen steps, the first model produces a fully correct result roughly 46% of the time. The second, roughly 86%. Research from Google DeepMind on scaling agent systems quantifies this directly: independent agents amplify errors by a factor of 17.2 through unchecked propagation, while centralized coordination reduces this to 4.4.
Claude Opus 4.6, GPT-5, and Gemini 3.0 Pro remain meaningfully ahead of every open-source model on exactly the capabilities this step demands: complex multi-step reasoning, error recovery when tool outputs are unexpected, and sustained coherence across extended workflows.
The demand for this quality is not price-sensitive. Anthropic’s $70 billion ARR trajectory and Claude Code’s $2.5 billion ARR within six months of launch reflect enterprises paying premium prices for capabilities they cannot source elsewhere. Integration depth compounds the advantage. Claude Opus 4.6’s million-token context window holds an entire codebase, document repository, or customer history in active memory while reasoning across a multi-step workflow. It continuously attends to context, catching dependencies and contradictions that chunked retrieval misses. This is not a feature an external runtime can replicate. It emerges from the model’s architecture, its training, and its scale.
The mechanism is this: if only frontier closed-source models can reliably handle orchestration tasks such as planning, the consequential decisions, and the error recovery, then the model provider retains pricing power and strategic leverage over the most valuable step in the workflow, even when the SaaS incumbent nominally owns the user relationship, the data, and the runtime. The enterprise can swap Nemotron for another open-source model for research tasks. It cannot swap Claude on the orchestration tasks without degrading the entire workflow. The model provider becomes the de facto orchestrator through the back door, not by owning the platform, but by owning the step that cannot be commoditized.
The Nemotron Coalition’s composition sharpens this problem.

The open-source models with the most competitive long-context capabilities and agentic coordination are all Chinese: DeepSeek V3.2 (128K tokens), Qwen3.5 (262K native, extendable beyond 1 M tokens), and Kimi K2.5 (256K tokens with novel Agent Swarm capabilities). All are absent from the coalition.
The Western open-source models in the Nemotron coalition, led by Mistral, do not yet match either the frontier closed-source labs or the leading Chinese open-source labs on sustained long-context reasoning. The coalition is building a Western alternative to Chinese open-source AI. It is not yet building a Western alternative to Claude Opus on the tasks that determine who actually orchestrates the workflow.
Two counterarguments temper this case. The first is that the frontier gap is not fixed. It is a moving target, and it has been moving fast. The distance between GPT-4 and the best open-source models in early 2024 was vast; by early 2026, it had narrowed to negligible on many tasks. Distillation techniques now enable smaller models to inherit significant capabilities from frontier models by training on their outputs.
Nemotron models are not generic open-source releases. They are specifically optimized by NVIDIA for agentic tasks, and the coalition includes LangChain (the dominant agent framework, with over one billion downloads), Cursor (the dominant AI code editor), and Mistral (which has consistently punched above its weight on reasoning benchmarks). The question is whether agentic orchestration is the kind of capability in which the gap closes through distillation and fine-tuning, or the kind in which it persists because the underlying reasoning demands cannot be compressed. The honest answer is that we do not yet know.
The second is cost. Even if frontier models remain superior at orchestration, the cost of calling them is falling rapidly. Each model generation delivers more capability per dollar. If frontier inference becomes cheap enough, it might undercut the rationale for the “hybrid” architecture in which enterprises call Claude for orchestration and Nemotron for everything else. Instead, the economics enable a simpler architecture where Claude handles the entire workflow at an affordable price. In that scenario, the infrastructure layer becomes less strategically important than the piece has argued, because the economic incentive to route tasks away from the frontier model diminishes.
NVIDIA’s bet depends not just on open models becoming good enough, but also on frontier models remaining expensive enough that the cost-optimization AI-Q provides continues to matter.
The history of computing offers a pattern, but not a verdict. The layer that makes consequential decisions, where errors are most costly and quality differences most apparent, has consistently captured platform economics.
In mainframes, it was the operating system. In PCs, it was Windows. In smartphones, it was iOS and Android. But in each case, the infrastructure layer also captured enormous value - IBM’s hardware, Intel’s chips, Qualcomm’s modems - even when it did not control the platform.
NVIDIA’s bet is that model quality will commoditize fast enough for infrastructure to become the binding constraint. Anthropic’s bet is that it will not. Both bets could prove partially right.
That is perhaps the most likely outcome.
Two Architectures, One Open Question
The competitive landscape has narrowed to two architectures.
In Architecture A, the model providers orchestrate. Intelligence is the platform. NVIDIA sells GPUs.
In Architecture B, the SaaS incumbents orchestrate on NVIDIA’s infrastructure. Data and workflows are the platform. NVIDIA sells GPUs and captures the software infrastructure layer.
In both scenarios, NVIDIA holds a strong position due to its near-monopoly in AI hardware. But Architecture B is transformative for NVIDIA because it adds the software infrastructure layer to the hardware moat, an implicit declaration that the company’s competitive advantage is migrating up the stack. The Agent Toolkit is not a product. It is a structural bet on which architecture will define the agentic economy.
The market has not yet absorbed this. And it may be right not to, in the near term. The Agent Toolkit is open-source, alpha-stage in several components, and the seventeen partnerships are reference architectures, not production deployments. CUDA took a decade to generate the AI training revenue that justified its existence. The Agent Toolkit may take years (or less) for its indirect contribution to GPU demand to become measurable. NVIDIA’s own disclosures acknowledge that many of the announced products and features “remain in various stages of development.”
But strategic logic and financial materiality operate on different timescales. The logic that the company providing the agent runtime for enterprise platforms captures value from every agent, regardless of which model powers it, is sound.
The uncertainty developed throughout this piece is equally real: if frontier model quality does not commoditize, the model provider retains control of the orchestration step regardless of who owns the runtime; if inference costs fall fast enough, the hybrid architecture that justifies AI-Q loses its economic rationale.
If model quality commoditizes, NVIDIA wins both the hardware and the infrastructure. If it does not, if the frontier remains far enough ahead that the orchestration step demands Claude or GPT, then even in Architecture B, the model provider controls the most valuable step in every workflow, and NVIDIA remains, as it has always been, a very profitable hardware company.
If both bets prove partially right, frontier models stay ahead but get cheaper, open models close the gap, but not entirely, then we may see something messier and more interesting than either architecture predicts: a world where infrastructure, intelligence, and application data all capture value, and the boundaries between them remain permanently contested.
The more likely outcome may be less clean than either scenario suggests: frontier models stay ahead but get cheaper, open models close the gap but not entirely, and value fragments across layers. Infrastructure, intelligence, and application data all matter, and the boundaries between them remain contested.
The leather jacket, it turns out, held more than a GPU roadmap. It may have contained the outline of NVIDIA’s next platform shift. One that, like CUDA before it, looks easy to underestimate while it is still taking shape.
Disclaimer: This post reflects the author’s opinions and analysis based on publicly available information. It does not constitute investment advice. The author may hold positions in the companies mentioned.