
Second Law of Value in the Agentic Era: Context is the New Moat
Why memory architecture, context depth, and data defensibility determine who captures value.


Context is the new moat, not data. Context encompasses data when built right through sophisticated memory architectures that layer behavioral patterns, relationships, and temporal understanding. Winners will have proprietary operational context (from physical infrastructure, transactions, unique access), plus the engineering to organize and orchestrate it across agent networks via protocols like MCP and A2A. The advantage isn’t hoarding information, it’s mastering context depth and enabling secure cross-ecosystem flow that makes agents genuinely intelligent and effective at scale.
The enterprise software industry spent the last decade obsessed with accumulating data. Companies built vast lakes and warehouses, convinced that whoever collected the most information would dominate their markets. But as agentic AI systems emerge, driven by autonomous agents capable of reasoning, coordinating, and executing complex workflows, a structural shift is underway.
Data alone no longer creates a competitive advantage. Context does.
In the first part of this series about how and where value accrues in the Agentic Era, I explored how proximity to user intent is the first pillar of orchestration. Building on that foundation, this article examines the Second Law of Orchestration Value: Context is the New Moat.
Understanding this law requires recognizing what context actually means and how it differs from the data accumulation strategies that defined the previous era. Context transforms raw information into actionable intelligence by incorporating layers that data alone cannot provide - user preferences and interaction histories, environmental conditions and temporal patterns, situational awareness and relational dynamics. Without context, an agent is ungrounded, operating in a vacuum where its actions lack meaning and produce unpredictable results. With context, that same agent becomes remarkably effective, making decisions that reflect a deep understanding of its operational reality.
Context (per Merriam-Webster)
- The parts of a discourse that surround a word or passage and can throw light on its meaning.
- The interrelated conditions in which something exists or occurs; also referred to as environment or settingAs the push toward agentic AI and agentic systems accelerates, the opportunities and the needs in this segment of the orchestration stack are coming into focus, and the market is starting to recognize them.
Last week, LangChain, which has developed an open-source framework for building AI agents, announced that it had raised $125 million at a $1.25 billion valuation, while also taking the occasion to release an update to its context/memory tool LangGraph. Earlier in the month, Graph database provider Neo4j unveiled plans to invest $100 million in new products because, as its CEO said “Agentic systems need contextual reasoning, persistent memory.”
How critical is the context problem? Recall the MIT GenAI study that caused such an uproar last summer by reporting that 95% of corporate GenAI projects failed to get past the pilot stage. One of the top reasons cited by the report for this high failure rate: “model quality fails without context.”
The companies that master context accumulation and leverage it effectively will establish moats that prove nearly impossible to replicate. This advantage rests on three interconnected pillars:
sophisticated memory architectures that capture and organize contextual information across multiple dimensions
context accumulation depth that creates high-fidelity operational understanding
defensibility mechanisms that prevent competitors from replicating these advantages.
Understanding how these pillars work together and recognizing their profound infrastructure requirements separates companies positioned for the agentic era from those facing obsolescence.
The Grounding Imperative
The distinction between AI agents and agentic AI illuminates why context matters so profoundly. A recent study (“AI Agents vs. Agentic AI: A Conceptual taxonomy, applications and challenges”) by Ranjan Sapkota, a Cornell University researcher, and colleagues, clarifies this crucial difference through architectural analysis that reveals fundamentally different operating principles.
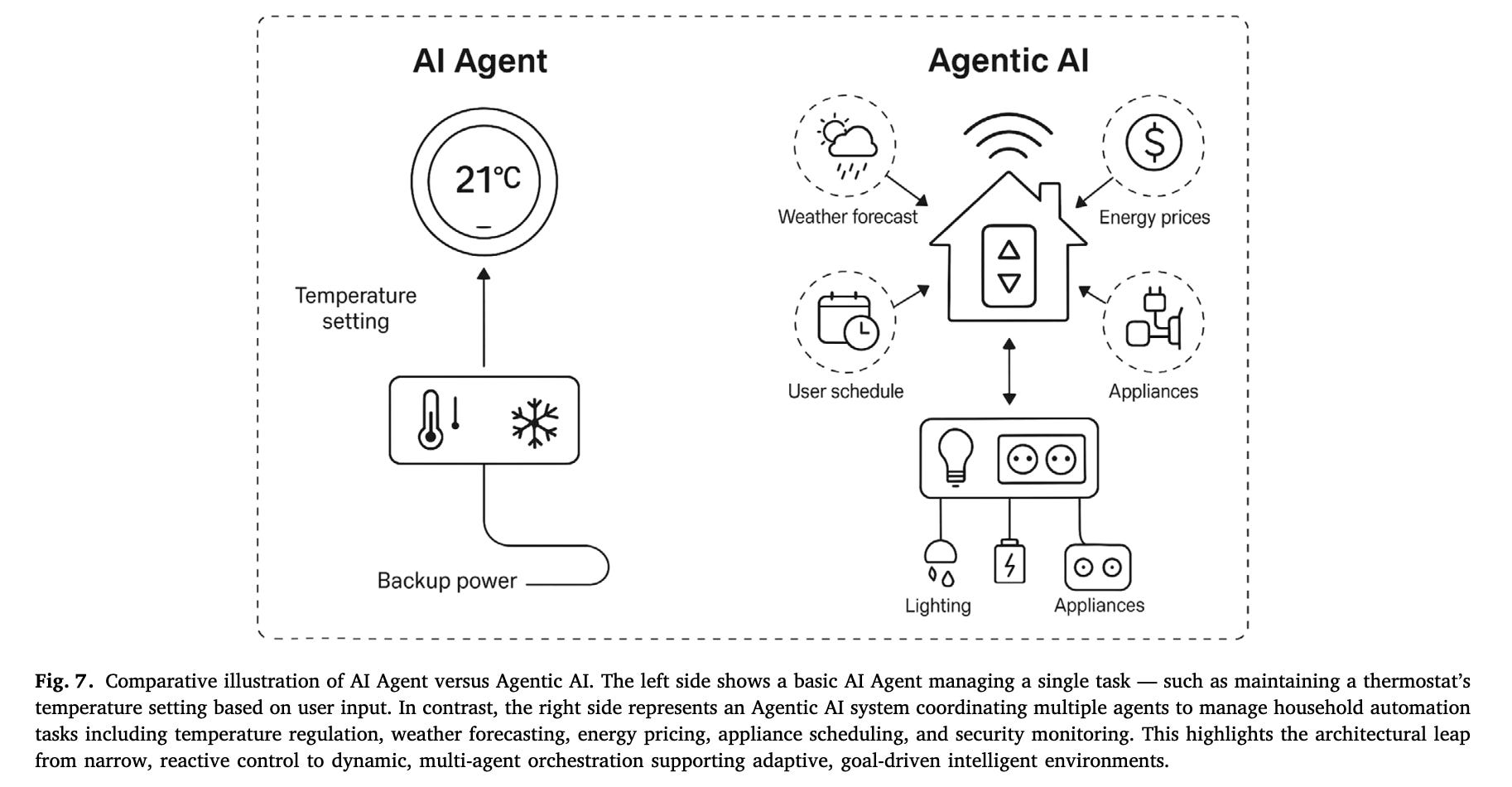
As you can see in this illustration above from the study, individual AI agents function as specialized assistants. Imagine a customer support agent handling tickets, an email filter managing inbox organization, or a scheduling agent coordinating calendars. These agents exhibit autonomy within narrow domains and react to environmental inputs, but they operate in isolation without persistent memory or coordination capabilities.
Agentic AI represents something categorically different: distributed networks of specialized agents that share persistent context, coordinate through structured protocols, and pursue decomposed goals under orchestrated supervision.
The transformation occurs when multiple agents access shared contextual understanding that allows them to collaborate effectively. A financial planning system exemplifies this distinction. Rather than separate agents for portfolio analysis, risk assessment, and compliance checking, an agentic system coordinates these capabilities through unified context that captures investment history, risk tolerance evolution, regulatory requirements, and market conditions.
But this creates risk. Because they are running autonomously across these systems, there is a heightened chance that they will begin to make decisions that are not, in fact, based on the reality of the business.
For that reason, “grounding” becomes essential. This is the process or mechanism that ensures agentic systems remain connected to operational reality, using the same definitions of customers and products, for example. Natural language grounding enables contextual interpretation of instructions and queries, translating user intent into actionable directives informed by situational understanding to achieve results that can be trusted and will be relevant. Perceptual grounding connects to sensory data and interface information, allowing agents to understand their environment through observations that extend beyond text-based inputs. The evolution from simple intent detection in chatbots to sophisticated agent planning and execution hinges entirely on effective grounding mechanisms.
Retrieval Augmented Generation (RAG) has emerged as the foundational approach for informational grounding. RAG is when agents query context stores to retrieve relevant information before generating responses or taking actions. This architecture prevents hallucination and ensures agent outputs reflect actual operational conditions rather than model assumptions. But RAG alone proves insufficient for truly agentic systems, which require persistent context that evolves across interactions rather than stateless retrieval.
Consider an agent network managing healthcare operations. It schedules appointments, coordinates care teams, handles insurance claims, and monitors patient outcomes. Individual agents can handle discrete tasks when grounded in immediate context, like available appointment slots or claim status. But agentic coordination requires shared understanding that spans patient medical histories, provider capabilities and preferences, insurance coverage evolution, and regulatory compliance requirements.
Without this multilayered grounding, agents cannot coordinate effectively because they lack the contextual foundation that makes their collective actions coherent and productive.
Memory Architecture as Foundation
Building effective context requires sophisticated memory systems that mirror cognitive architectures rather than simple data storage.
The MemoryOS framework, developed through research applying operating system principles to AI agent memory management, provides the clearest articulation of what sophisticated memory architecture demands. The system implements three distinct memory tiers: short-term, mid-term, and long-term.
Each of these serve specific functions in context accumulation and retrieval:
Short-term memory stores immediate conversation data in dialogue pages, capturing user queries, agent responses, and temporal information. This tier maintains active context for current interactions, ensuring agents can reference recent exchanges and track evolving conversations. The dialogue chain mechanism links related pages, preserving contextual continuity across multi-turn interactions rather than treating each exchange as isolated. This architecture enables agents to maintain coherent conversations that build progressively rather than resetting with each query.
Mid-term memory adopts segmented paging storage inspired by operating system memory management. Dialogue pages sharing common topics cluster into segments, creating a thematic organization that facilitates efficient retrieval. The system measures similarity through combined semantic and keyword matching, ensuring related content aggregates appropriately while maintaining topic coherence. Heat-based prioritization retains frequently accessed segments while archiving less relevant information, balancing comprehensiveness with retrieval efficiency.
Long-term personal memory captures persistent user and agent characteristics across extended timeframes. User profiles include static attributes like demographic information alongside dynamic knowledge bases that accumulate information extracted from interactions. User traits track evolving interests, preferences, and behavioral patterns, creating a personalized context that informs agent responses. Agent personas maintain consistent self-descriptions while developing dynamic attributes through user interactions, establishing stable identity alongside adaptive learning.
The engineering challenge these memory systems present cannot be understated.
Implementing hierarchical architectures with distinct modules for storage, updating, retrieval, and generation requires sophisticated data infrastructure that extends well beyond traditional database capabilities. The dialogue-chain-based FIFO mechanism for short-term to mid-term updates demands real-time processing that maintains context integrity while managing scale. Mid-term to long-term updates employ heat-based replacement strategies that balance relevance with coverage, requiring constant evaluation of information value and usage patterns.
Still, recent research from UCL’s Centre for Artificial Intelligence and Huawei Noah’s Ark Lab demonstrated the technical feasibility by publishing Memento, a framework that enables agents to achieve state-of-the-art performance through sophisticated external memory without fine-tuning the underlying language model. Memento exemplifies how multi-tiered architectures enable agents to learn continuously, accumulate “execution data,” and build durable, domain-specific intelligence at runtime.

This architectural complexity of memory creates interesting competitive dynamics:
Startups building agentic systems from first principles may actually possess advantages over incumbents burdened by legacy data architectures designed for different paradigms. The freedom to design memory systems optimized specifically for agentic coordination—structuring data for rapid context retrieval, implementing semantic indexing for associative memory, building governance frameworks for dynamic updating—represents strategic flexibility that established companies struggle to replicate without wholesale infrastructure transformation.
However, the resources required for building and maintaining pluralistic memory stacks favor well-capitalized enterprises. Robust data engineering capabilities, efficient retrieval mechanisms operating at scale, and mature governance policies handling quality and relevance filtering demand sustained investment in specialized talent and infrastructure. The companies that can fund sophisticated memory architecture development while iterating rapidly based on agent performance feedback occupy the strongest competitive position.
Context Depth Beyond Data
Memory architecture provides the scaffold, but the substance of the moat lies in context depth. This is where we find the richness and multidimensionality of contextual understanding that agents can access and leverage. Context transcends static data by incorporating dynamic, relational, and temporal dimensions that transform information into actionable intelligence. Understanding these dimensions and how they differ from traditional data accumulation reveals why context creates such powerful competitive advantages:
Behavioral context captures user patterns, habits, and preferences through observation of actions rather than explicit declarations. An orchestration platform tracking how users actually navigate workflows, which shortcuts they develop, where they encounter friction, and how their patterns evolve over time, accumulates behavioral understanding that informs agent optimization. This contrasts sharply with stated preference data, which often diverges from actual behavior—users claim to want certain features while consistently using different approaches in practice. Behavioral context enables agents to anticipate needs based on demonstrated patterns rather than relying on potentially inaccurate self-reporting.
Transactional context encompasses decision history and outcome tracking across extended time frames. A procurement agent accessing complete transaction histories—supplier selections, price negotiations, delivery performance, quality issues, relationship dynamics—can make recommendations informed by actual results rather than static supplier profiles. This depth allows for nuanced decision-making that accounts for contextual factors like seasonal patterns, volume relationships, and historical problem resolution. The accumulation of transactional context over the years creates an understanding that new market entrants cannot replicate without a similar operational history.
Relational context maps entity connections and causal relationships that explain why certain patterns emerge. Understanding that particular suppliers consistently deliver on time for specific product categories but struggle with others, that certain customer segments respond differently to pricing strategies, or that workflow bottlenecks stem from interdependencies between teams rather than individual inefficiencies—this relational understanding allows agents to reason about causality rather than just correlation. The distinction matters profoundly for autonomous decision-making, where agents must predict how actions will cascade through complex systems.
Temporal context captures time-series patterns and seasonality that influence optimal actions. Manufacturing orchestration agents understanding seasonal demand fluctuations, maintenance cycle requirements, and capacity constraint evolution make dramatically different recommendations than agents operating on point-in-time data. Temporal context enables proactive optimization—adjusting inventory levels ahead of anticipated demand, scheduling preventive maintenance during low-utilization periods, and shifting production between facilities based on predicted capacity availability.
The power of context depth emerges when companies integrate all four dimensions into composite operational understanding. A financial services orchestration platform that tracks behavioral patterns in how clients make investment decisions, maintains complete transactional history of portfolio performance and market timing, maps relational connections between asset classes and market conditions, and incorporates temporal patterns in client risk tolerance creates context that dramatically outperforms platforms with narrower scope. This comprehensive context enables agents to provide remarkably sophisticated guidance that reflects deep understanding of individual client situations.
The flywheel effect amplifies these advantages. Better context leads to better agent performance, which attracts more users and deeper platform integration, which generates richer context, which further improves agent capabilities. The companies establishing early leads in context accumulation benefit from compound advantages that accelerate over time, making competitive displacement increasingly difficult. This dynamic explains why incumbent enterprises in regulated or physically-grounded industries possess potential advantages despite slower technological adoption—their operational context accumulated over decades provides foundation.
Context Defensibility
Context advantages become durable moats only when defended against replication.
Two factors determine defensibility:
whether competitors can collect similar context
whether users can transfer accumulated context to competing platform
Companies securing both dimensions via proprietary access and high switching costs will establish positions that prove extraordinarily difficult to displace.
Proprietary access stems from unique data collection opportunities. Physical infrastructure companies exemplify this advantage.
Tesla accumulates driving context through millions of vehicles operating continuously across diverse conditions. This includes real-world navigation decisions, edge case handling, environmental condition responses, driver intervention patterns. This context flows from operational reality rather than synthetic data generation, capturing nuances that simulations cannot reproduce. Competitors attempting to build comparable autonomous driving capabilities without similar real-world context accumulation face fundamental limitations regardless of computational resources or algorithmic sophistication.
The financial services industry demonstrates similar dynamics. JPMorgan Chase’s decision to restrict competitor access to its transaction data recognizes that payment flow context creates strategic advantage for building financial orchestration platforms. The bank processes trillions in transactions annually, accumulating context about business cash flows, seasonal patterns, vendor relationships, and financial health indicators that inform intelligent treasury management and working capital optimization. This operational context enables agent recommendations reflecting actual business dynamics rather than aggregated industry statistics.
Yet the assumption that physical infrastructure creates unassailable context advantages warrants scrutiny.
Digital natives demonstrate increasingly sophisticated strategies for bootstrapping context without owning hard assets. Open-source data collectives enable distributed context accumulation - shared benchmarks, simulation environments, and federated learning frameworks allow agile players to pool contextual intelligence across industry participants. The robotics industry exemplifies this dynamic, where companies like Roboflow create specialized datasets and computer vision models that democratize context previously requiring expensive proprietary data collection. As Scott Belsky notes, long-tail specialized datasets captured purposefully—atmospheric data, warehouse workflows, assembly line nuances—can unlock precision automation without requiring ownership of the underlying physical operations.
Synthetic data generation accelerates this democratization.
Advanced simulation environments now replicate operational contexts with sufficient fidelity to train agents effectively, closing gaps faster than incumbents expect. Autonomous vehicle development demonstrates both the power and limitations of this approach—while simulated driving scenarios cannot fully replace real-world edge cases, they dramatically reduce the operational context gap that physical fleet operators once considered insurmountable. The combination of synthetic environments, federated learning across industry participants, and strategic partnerships for real-world validation creates pathways for digital natives to accumulate context depth rivaling incumbents over compressed timeframes.
Switching costs emerge when users cannot easily export accumulated context to competing platforms. Enterprise software traditionally created switching costs through data lock-in which made migrating data between systems proved technically complex and organizationally disruptive. Context switching costs operate differently and create stronger barriers. Even when raw data transfers technically, the contextual understanding agents developed through extended interactions, cannot transfer because it exists in agent memory architectures and training rather than exportable data formats.
The nature of defensible context itself evolves beyond traditional data assets. Historical data will become increasingly transferable as enterprises control their own data through Snowflake or Databricks instances. So different contextual elements will emerge as strategic.
For instance, relational graphs capturing who-works-with-whom dynamics, permissioning structures, and social connections take years to construct and resist easy portability. These graphs, whether representing teamwork patterns across projects or trust relationships between business entities, embed contextual understanding that raw data exports cannot capture.
Portable personalization profiles provide the deep understanding of individual preferences, working styles, and decision patterns that agents develop. These, in turn, create switching costs precisely because this contextual intelligence exists in memory architectures and learned behaviors rather than exportable records.
The strongest defensive positions combine both elements.
Companies with unique context collection capabilities and platforms that accumulate non-transferable contextual intelligence create compound moats. Physical world operators building intelligent orchestration layers on irreplaceable infrastructure such as utility companies orchestrating energy distribution, telecommunications providers coordinating network optimization, transportation companies managing logistics flows may occupy positions that pure software competitors cannot displace because the context derives fundamentally from physical asset operation and accumulated operational understanding.
This reality explains why the dominant players in the agentic era likely emerge from companies possessing proprietary context sources rather than companies with superior algorithms or models. The commoditization of foundation model capabilities through API access and open-source availability means algorithmic advantages prove temporary.
Context advantages rooted in operational reality and accumulated over years prove durable precisely because competitors cannot replicate them through engineering effort alone.
Infrastructure Requirements
The shift to agentic AI creates profound infrastructure challenges that existing data systems, designed for human-mediated access, cannot meet. Agentic systems operate on a different paradigm, engaging in high-throughput “agentic speculation.“ This refers to exploratory, heterogeneous, and high-volume queries to test solutions and ground their reasoning. This new workload, characterized by massive branching, forking, and rollbacks, overwhelms traditional data architectures, creating critical bottlenecks in query latency and context retrieval that undermine agent performance at scale.
Mastering context, therefore, demands a new “agent-first” data stack. This requires fundamentally new architectural components: agentic memory stores to cache grounding information for reuse, probe optimizers that can “satisfice” exploratory queries with approximate results instead of full execution, and multi-world isolation to manage the storage demands of speculative reasoning. These systems must be engineered for agent-scale access, not human-scale analysis, treating exploratory queries as a distinct and primary workflow.
Finally, this infrastructure must extend beyond any single organization. The true power of context is realized not when it is siloed, but when it is orchestrated. Critical protocols like Model Context Protocol (MCP) and Agent-to-Agent (A2A) communication standards are the infrastructure that enables this flow, allowing context to be shared securely across ecosystems. Without this dual investment in both a high-performance internal data stack and the external protocols for context-sharing even the deepest, most proprietary context moat will collapse, as the agents relying on it will be unable to access or coordinate information effectively.
This architectural shift suggests that exponential value creation emerges not from hoarding context but from orchestrating its secure flow across agent networks. The protocols enabling this cross-ecosystem coordination become infrastructure moats themselves platforms that implement MCP and A2A standards early establish themselves as contextual hubs through which agent networks must coordinate.
Yet the promise of frictionless context exchange through protocols like MCP may create its own paradox for moat construction.
Recent research demonstrates that MCP enables automated conversion of specialized tools into standardized interfaces using only documentation, which reduces integration time from months to minutes per tool. This standardization threatens a critical assumption underlying context moats: that proprietary context remains defensible through integration complexity. When any tool can be MCP-enabled automatically, and any agent can access that tool through uniform protocols, the friction costs that previously protected contextual advantages evaporate. The companies that assumed their moats derived from making context difficult to access may discover that in an MCP-enabled ecosystem, defensibility shifts entirely to the quality and uniqueness of the context itself rather than the architectural barriers surrounding it.
This dynamic favors operators with genuinely irreplaceable context sources: physical infrastructure, unique operational data, and proprietary relational graphs. At the same time, it exposes pure software plays that relied on integration friction as their primary defense.
The Context Imperative
The emergence of agentic AI profoundly redefines where competitive advantage resides in technology markets.
Companies that dominated the previous era through data accumulation strategies face displacement by competitors who recognize that context determines orchestration effectiveness. Yet the transition creates more nuanced dynamics than simple asset ownership for determining winners. The interplay between proprietary context sources, collaborative context accumulation, and cross-ecosystem orchestration capabilities will shape competitive outcomes.
The three pillars of context advantage are sophisticated memory architecture, context depth across multiple dimensions, and defensibility through proprietary access and switching costs. These work synergistically rather than independently.
Memory systems without rich contextual content provide structure without substance. Deep context without architectural sophistication to organize and retrieve it efficiently proves unwieldy and underutilized. Defensible context that agents cannot effectively leverage due to infrastructure limitations delivers strategic value slowly and incompletely.
Physical-world operators possess inherent advantages in this landscape precisely because their context arises from irreplaceable operational reality. Manufacturing facilities generating production context through actual operations, logistics companies accumulating transportation context through real shipments, energy utilities capturing distribution context through physical infrastructure—these companies can build orchestration platforms on contextual foundations that pure digital competitors cannot trivially replicate. Their challenge lies in recognizing this advantage and investing in the memory architecture and infrastructure required to leverage it effectively before digital natives bootstrap sufficient context through synthetic data, federated learning, and open-source collectives.
Yet the ultimate competitive advantage may accrue not to those who hoard the deepest proprietary context, but to those who orchestrate context flow most effectively across ecosystems. The companies implementing MCP and A2A protocols to enable secure, governed context exchange position themselves as coordination hubs through which multi-agent workflows must flow. This orchestration layer connects manufacturing context to supply chain intelligence, links financial transaction patterns to market dynamics, and integrates healthcare provider knowledge with patient outcome data. In doing so, it creates value exceeding any individual context source. The exponential returns emerge from compound intelligence generated when contextual understanding flows across industry boundaries rather than remaining locked within vertical silos.
Incumbent enterprises face a choice that will determine their relevance in the agentic era. Those treating context as merely refined data accumulation, applying traditional data warehouse approaches to organizing operational information, will find their supposed advantages evaporate as agentic systems demonstrate that volume without structure and depth provides minimal competitive protection. Organizations that recognize context as fundamentally different position themselves to establish moats that compound over time.
The companies mastering context in the agentic era will achieve two defining characteristics.
First, they will possess unique contextual intelligence, whether that’s through operations in the physical world, privileged access to high-value information flows, or sophisticated aggregation of distributed context across collaborative networks.
Second, they will master the complex engineering required to build living, learning context layers that allow agents to act with unparalleled intelligence and effectiveness while orchestrating secure context flow across organizational and industry boundaries.
This combination of contextual intelligence and orchestration infrastructure represents the defining moat of the next decade, separating platforms that merely participate in the agentic era from those who will come to define it.
This was Part 2 of my series: “Laws of Value in the Agentic Era.”
Part 1 examined how competitive advantage shifts from owning systems of record to capturing where intent begins and orchestrating work from there.
Part 3 will explore the Third Law: Workflow integration power.