
Orchestration Economics: Intelligence Is Sufficient for Production (Chapter 4)
Why AGI is not needed for the Agentic Era to be reality.


This is the latest excerpt from AGNT: The Orchestration Economics Manifesto - An Investment Framework for the Agentic Era. Each Thursday, I explore a major theme of the Manifesto and unpack the frameworks, adding extra context with more recent developments. Note: The figures and sequential references are taken directly from the larger Manifesto.
There is a persistent and understandable debate at the heart of the AI investment thesis: whether current models are capable enough, or whether the agentic transition depends on a future breakthrough, perhaps artificial general intelligence (“AGI”), perhaps some architectural innovation not yet conceived.
The question matters, but it is the wrong question. The agentic transition does not require AGI. It does not depend on a future breakthrough. It depends on whether current frontier intelligence is sufficient for production deployment of agentic systems that perform economically valuable work under appropriate human oversight.
It is.
In December 2025, a team of 25 researchers led by UC Berkeley published “Measuring Agents in Production.” This was the first large-scale systematic study of AI agents deployed in real production environments.
The MAP study surveyed 306 practitioners and conducted 20 in-depth case studies across 26 domains. Its central finding was unambiguous: existing frontier models, using prompting strategies alone, already possessed sufficient capability to cover a diverse range of production use cases. 70% of deployed agents relied on off-the-shelf models without any fine-tuning. No architectural breakthroughs were required. Teams predominantly selected the most capable frontier models available, and the cost and latency of those models remained favorable compared to human baselines.
What follows is the evidence for why the intelligence is sufficient, including the specific dimensions of capability that make the agentic transition viable, not as a forecast but as an engineering reality.

The Cognitive Primitives Are Here
Any agentic system, regardless of domain, rests on the same cognitive foundation. An agent that orchestrates a complex workflow, such as processing an insurance claim, conducting financial due diligence, or coordinating a product launch, must decompose goals into sub-problems, maintain logical consistency across long chains of reasoning, adapt plans when intermediate steps produce unexpected results, and verify its outputs against formal constraints. These are not speculative requirements. They are the cognitive primitives of professional knowledge work.
The evidence that frontier models possess these primitives is no longer contested. On GPQA Diamond, the benchmark for graduate-level science questions, where human PhD experts score 69.7%, performance among frontier models has now converged above 90% across multiple vendors.
On Humanity’s Last Exam (a benchmark designed to test the absolute frontier of PhD-level knowledge across disciplines), multiple models surpass 40%, with Kimi K2 Thinking (Moonshot AI) reaching 44.9% at a fraction of the training cost of Western frontier systems. Some reported frontier results now range from high-40s to mid-60s, depending on the evaluation setup.
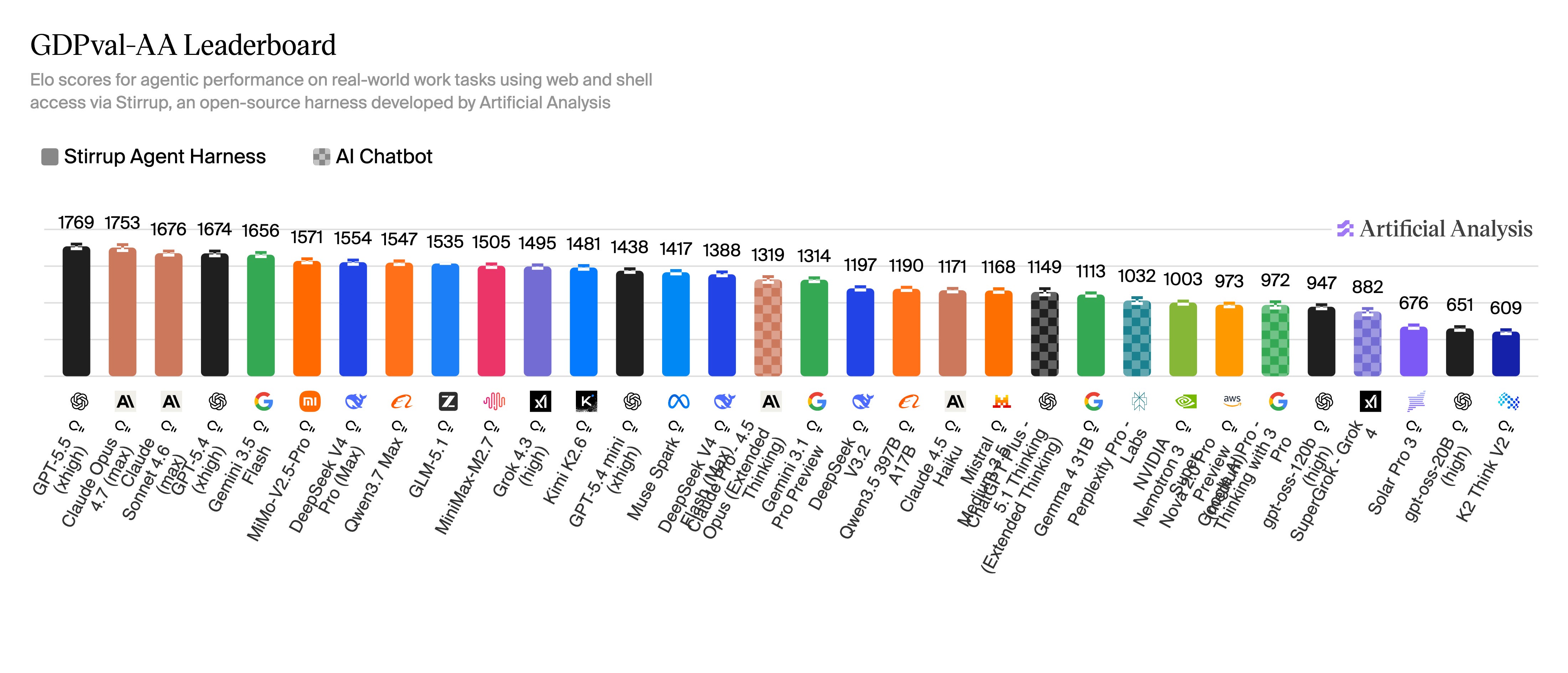
A newer index, GDPval-AA, measures how effectively frontier AI agents perform economically valuable professional tasks across real occupations and industries under realistic operating conditions, including tool use, browsing, and workflow execution. Unlike academic benchmarks that evaluate isolated reasoning ability, GDPval-AA assesses whether agents can complete bounded forms of actual knowledge work, making it a more direct measure of labor-substitution potential. Its importance for the agentic thesis is that it suggests the primary bottleneck is no longer raw intelligence itself, but the orchestration, verification, and control infrastructure required to deploy that intelligence reliably at enterprise scale.
The benchmark demonstrates that frontier models already possess sufficient capability to perform economically useful professional work. The remaining bottleneck is not raw intelligence, but the orchestration infrastructure required to make that intelligence reliable, auditable, and deployable at scale
These results are not narrow technical achievements. They are evidence that the cognitive architecture required for the production of agentic systems exists as commercially available infrastructure. They have the ability to reason, plan, verify, and adapt. A model that reasons through PhD-level physics can reason through a multi-step insurance claims workflow. A model that synthesizes findings across graduate-level biology, chemistry, and physics can synthesize findings across a quarter’s financial filings.
The primitives are here. The question is whether they are genuine, whether the models are truly reasoning or merely pattern-matching at an impressive scale.
The Reasoning is Real
Mathematical reasoning provides a strong proof point because it is the one domain where pattern-matching cannot survive. A model can generate plausible-sounding legal analysis by interpolating between training examples. It cannot solve a novel competition mathematics problem that way. Either the proof is valid, or it is not. Either the answer is correct, or it is wrong. There is no partial credit for fluency.
When OpenAI evaluated GPT-4o on the 2024 AIME exams in September 2024, it solved only 12% (1.8/15) of problems on average. By September 2024, OpenAI’s o1 reached 74%76, placing it among the top high school competitors nationally. Three months later, o3 scored 96.7% on AIME 2024. By mid-2025, GPT-5 achieved 94.6% on the fresh AIME 2025 problem set without tools. Multiple models now reach 100%. The benchmark that was designed to challenge the brightest mathematical minds in America is, for practical purposes, saturated.
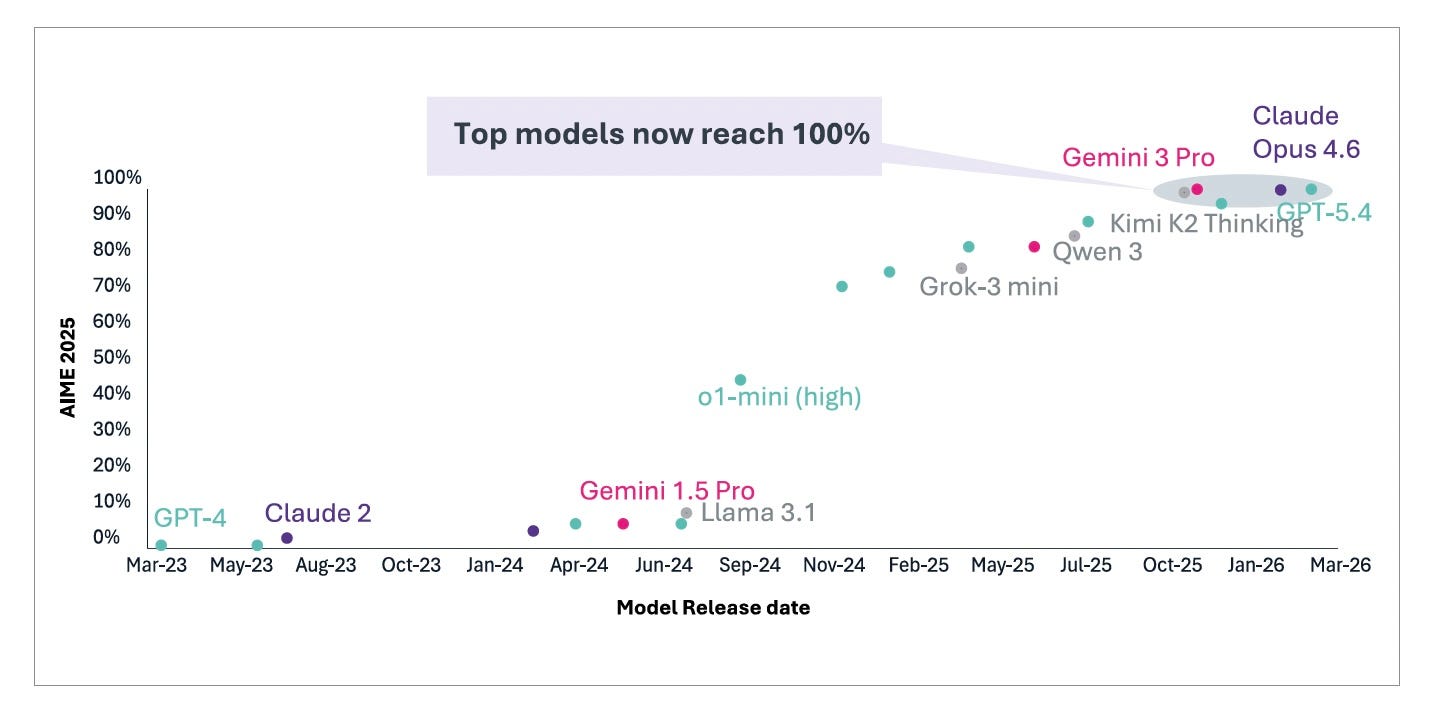
From barely functional to superhuman in roughly two years. The technical driver has been Reinforcement Learning from Verifiable Rewards (RLVR), which trains models against automatically verifiable rewards such as math, code execution, and formal proofs. This method introduces a new scaling dimension in which capability increases with test-time compute, not just model size. Performance can improve at inference time, not only through larger and more expensive training runs. The scaling laws have acquired a second axis.
The primitives documented in the previous section are not the product of sophisticated pattern-matching. They are the product of genuine reasoning capability that scales with compute applied at inference time. This matters directly for the agentic thesis: an agent that reasons through a multi-step insurance workflow is not retrieving a memorized template. It is decomposing the problem, testing intermediate results, and adapting its approach. These are the same cognitive operations that produce valid mathematical proofs.
It is also Systematically Fragile
The taxonomy is sobering: models that solve PhD-level physics exhibit the reversal curse. Trained on “A is B”, they fail to infer “B is A”. Models that score above 90% on graduate-level science benchmarks break down under minor rephrasing of the same questions. Compositional reasoning combines two known facts into a single inference. This degrades sharply as the number of steps increases. Cognitive biases inherited from training data produce systematic deviations from logical consistency that no amount of scaling has eliminated.
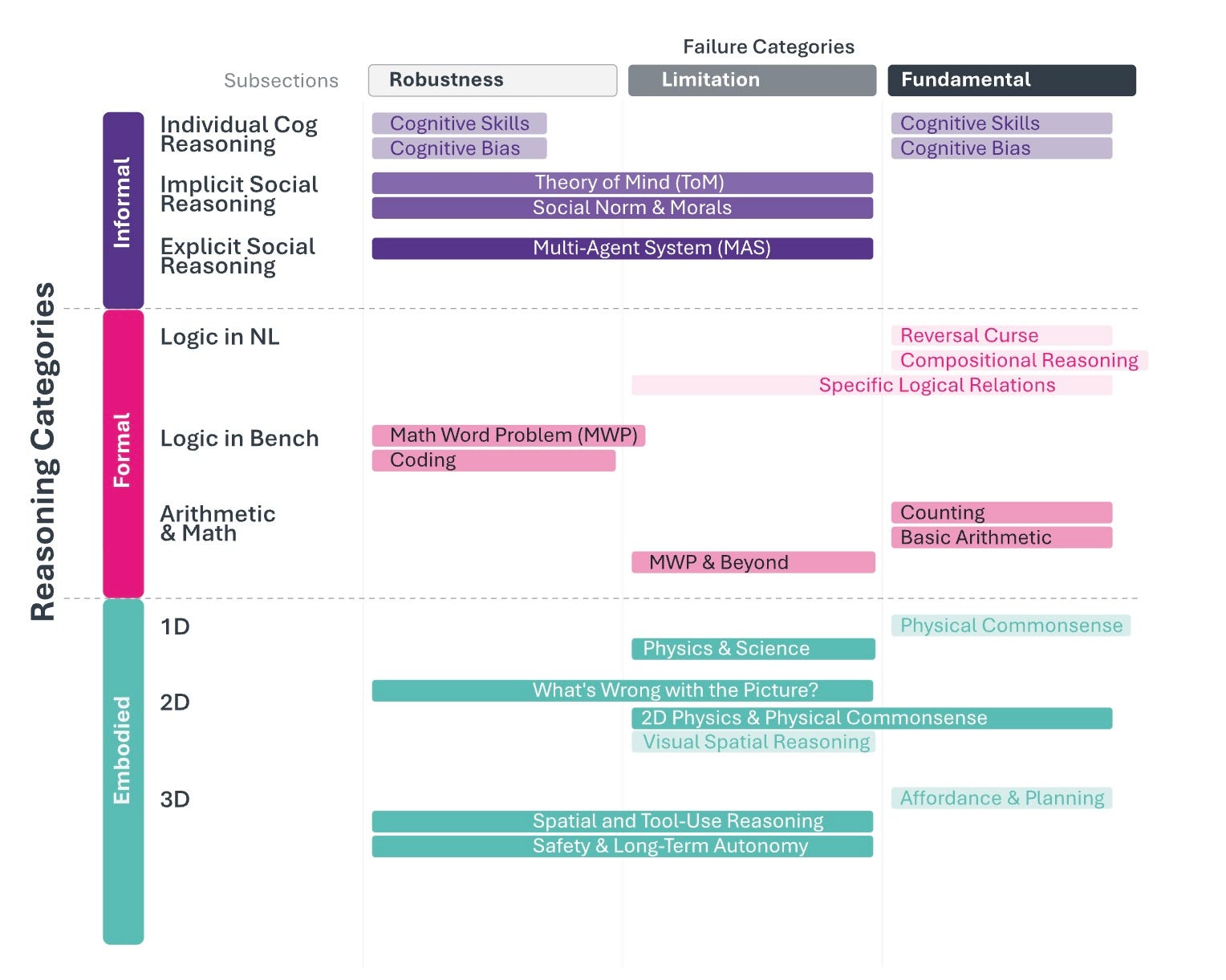
The failures are structural, traceable to architectural constraints that define the medium itself, such as autoregressive generation, attention dispersion under complexity, and the absence of embodied grounding. A model that produces a valid mathematical proof on one formulation of a problem can fail on a semantically identical reformulation.
The reasoning is genuine. The reliability is not. This is not a contradiction of the agentic thesis. It is the foundation of its central economic claim.
If frontier reasoning were perfect, if models could be trusted to execute arbitrary workflows without constraint, verification, or decomposition, then the value would reside in the model itself. The model layer would be the control plane. The Orchestration Layer would be unnecessary overhead.
But the reasoning is imperfect in precise, documentable, and predictable ways. The production agentic systems documented in Chapter 5 work not despite this fragility but because their architecture accounts for it. They decompose complex workflows into verifiable steps. They constrain agent action spaces to domains where failure modes are known and bounded. They insert verification at every junction where compositional reasoning might degrade. They treat model intelligence as a powerful but unreliable input that must be orchestrated to produce reliable outputs.
The Orchestration Layer is not scaffolding to be removed when models improve. It is the load-bearing structure of the agentic economy. Its value increases in direct proportion to the gap between what models can reason and what they can be trusted to do unsupervised.
That gap is where the surplus accrues. But the gap has a second dimension. The reasoning documented above operates within a single context window, page, problem, and pass. An agent that orchestrates a workflow spanning thousands of documents, weeks of interaction, and dozens of interdependent decisions requires something the reasoning benchmarks do not measure: memory.
The Memory That Makes Agency Possible
There is a capability dimension that receives less attention than benchmarks but may matter more for agentic systems than any of them: how much an AI model can hold in its mind at once. An agent orchestrating a complex workflow must hold contracts, regulatory requirements, financial models, and correspondence simultaneously in working memory. Short context makes autonomous agency impossible.
Long context is the substrate on which sustained autonomous work becomes feasible. The trajectory here has been as dramatic as any benchmark. GPT-3 processed 2,048 tokens. GPT-4 extended this to 8,000 tokens in its standard configuration, with a 32,000-token variant available at premium pricing.
Then the explosion: Claude 3.5 reached 200,000 tokens in 2024. Google’s Gemini 1.5 Pro launched with one million and tested up to ten million in research. Claude Opus 4.6, released in February 2026, operates at one million tokens in production. And, as demonstrated on the MRCR v2 benchmark, it does not merely accept that context. It retrieves and reasons across it, scoring 76% versus 18.5% for its predecessor, Claude Sonnet 4.5. The model does not just have a larger memory. It uses it.
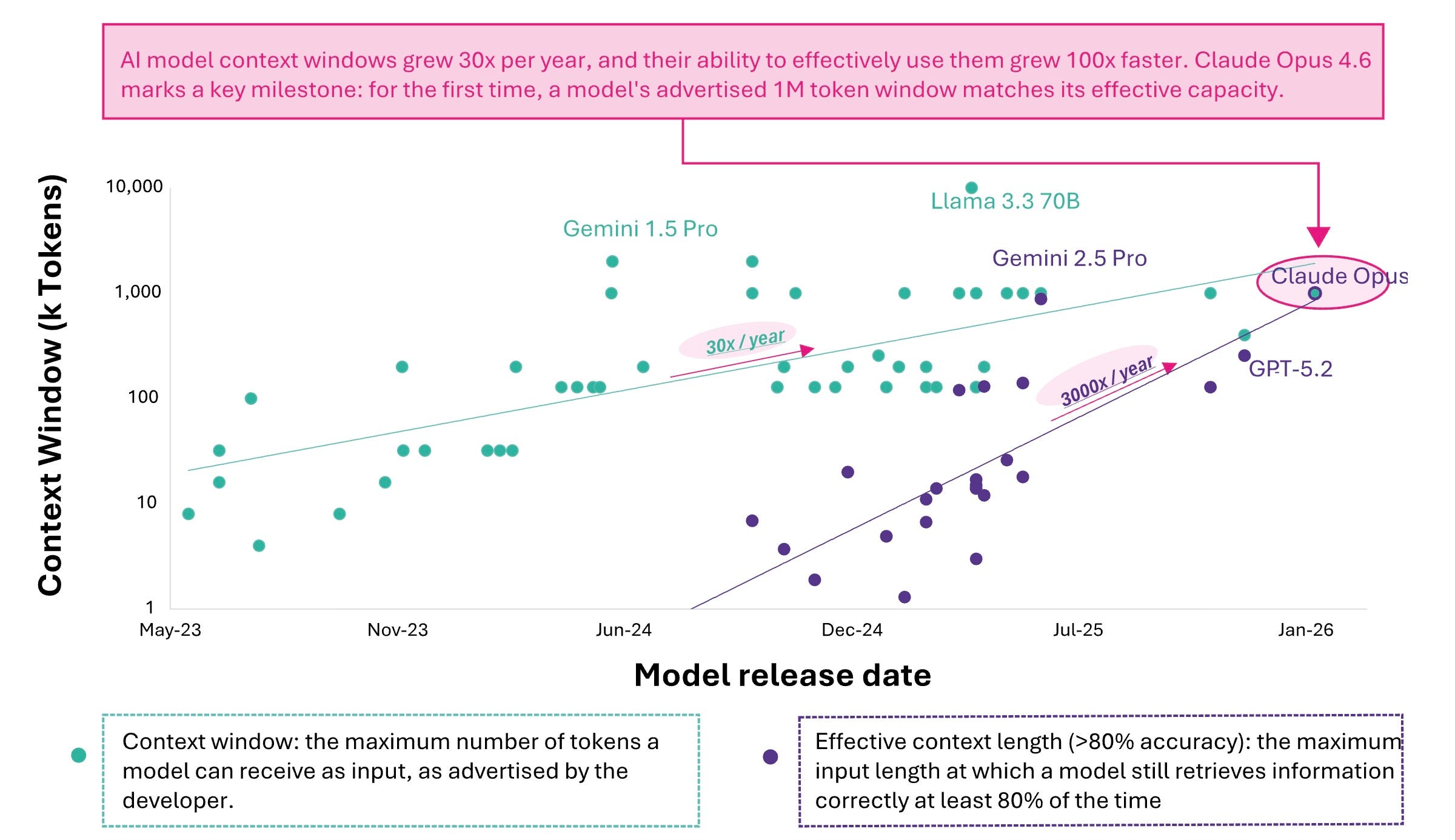
In 2023, a model could review a memo. In 2026, it can review an entire codebase, an entire regulatory filing, an entire quarter of customer correspondence, and reason across all of it simultaneously. This is the difference between a tool and an agent.
The long-context breakthrough connects directly to the preceding sections.
The cognitive primitives exist. The reasoning is genuine, and scales with inference-time compute. Now that reasoning can be sustained across the full scope of real professional work, not a single page but a thousand, not a single filing but a quarter’s worth, not a single module but an entire codebase. The agent can reason and remember.
What it could not do, until recently, was see.
Multimodality: From Impressive to Structural
Real work is not text-only. An agent managing product development reasons across user research videos, design mockups, customer feedback emails, code repositories, and executive strategy documents. Text-only models force everything through transcription bottlenecks, losing information that exists only in visual or audio form. The reasoning primitives, the genuine logic, and the long-context memory operate at full power only when they can access the full range of professional inputs.
The frontier has advanced into a measurable structural advantage. Gemini 3.5 Flash scores 88.27% Overall on MMMU-Pro and Gemini 3 Pro at 87.6% on Video-MMMU. These are measurements of whether a model can watch, understand, and reason about what it sees. The gap between multimodal systems and text-only alternatives is widening into a structural moat.
The multimodal frontier is not confined to trillion-dollar US laboratories. China’s MiniMax has built a full multimodal product family, including separate specialist models for text and agentic coding (M2.x), video (Hailuo), speech (Speech-02/2.8), and music (Music-2.x). Its text-centric M2.1 model scored 88.6% on VIBE, a benchmark MiniMax itself developed to measure an agent’s ability to generate working applications that are then visually and interactively verified at runtime.
For agentic production, multimodality is not a feature. It is an architectural requirement. An agent that can watch a customer service call, read the CRM record, analyze the tone of voice, and draft a resolution operates in a fundamentally different category from one that processes a transcript. An agent that can inspect a factory floor through camera feeds, cross-reference with maintenance logs, and flag anomalies before they cascade operates in a category that text-only systems cannot reach.
Natively multimodal architectures are becoming accessible, efficient, and deployable. The intelligence to support these modalities exists. The deployments will follow.
The METR Timeline
The longitudinal tracking conducted by the non-profit Model Evaluation and Threat Research (METR) institute provides a practical yardstick for measuring progress. It measures the length of tasks in human-expert completion time that AI agents can reliably complete, then analyzes how that length changes. In other words, it asks: How long would it take a human to complete this task? The 50%-task-completion time horizon is the time required for AI systems to reliably complete half the tasks. That rate had doubled approximately every 7 months since 2019, a trend confirmed in METR’s March 2026 update, which included a larger task suite and tighter confidence intervals. The trend holds across sensitivity analyses: perturbing tasks, models, and methodology shifts arrival-date estimates by less than two years for any given capability threshold.
As of March 2026, the frontier stood at twelve hours of focused human work. If the seven-month doubling rate persists, that frontier will reach one full workday by late 2026 and one workweek by mid-2027.
But recent data suggests the trend is accelerating. Over the full 2019-2025 period, the doubling time was approximately seven months. In 2024-2025, it compressed to three to four months, though estimates over shorter measurement windows carry wider confidence intervals. METR found similar exponential growth across all domains it examined, including mathematics, science, coding, web navigation, and OS interaction, with varying absolute time horizons but consistent trajectories.
Critically, METR measures self-contained tasks given to agents with no prior context. That is the equivalent of handing a new contractor a clearly scoped assignment. Real-world work, with accumulated institutional knowledge and project familiarity, is structurally easier. The time horizons likely understate what agents can accomplish within organizations that have built the orchestration infrastructure to support them.
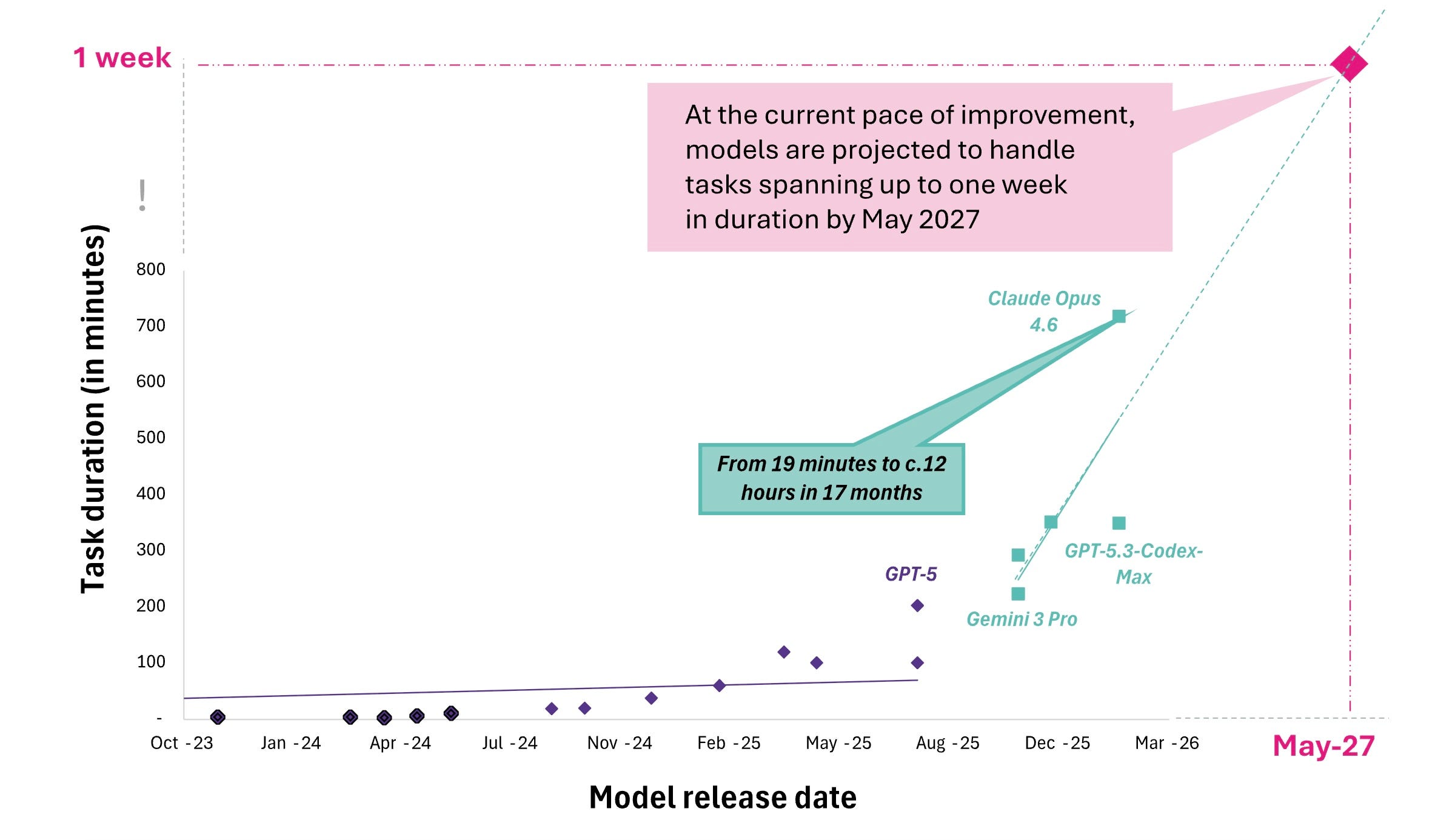
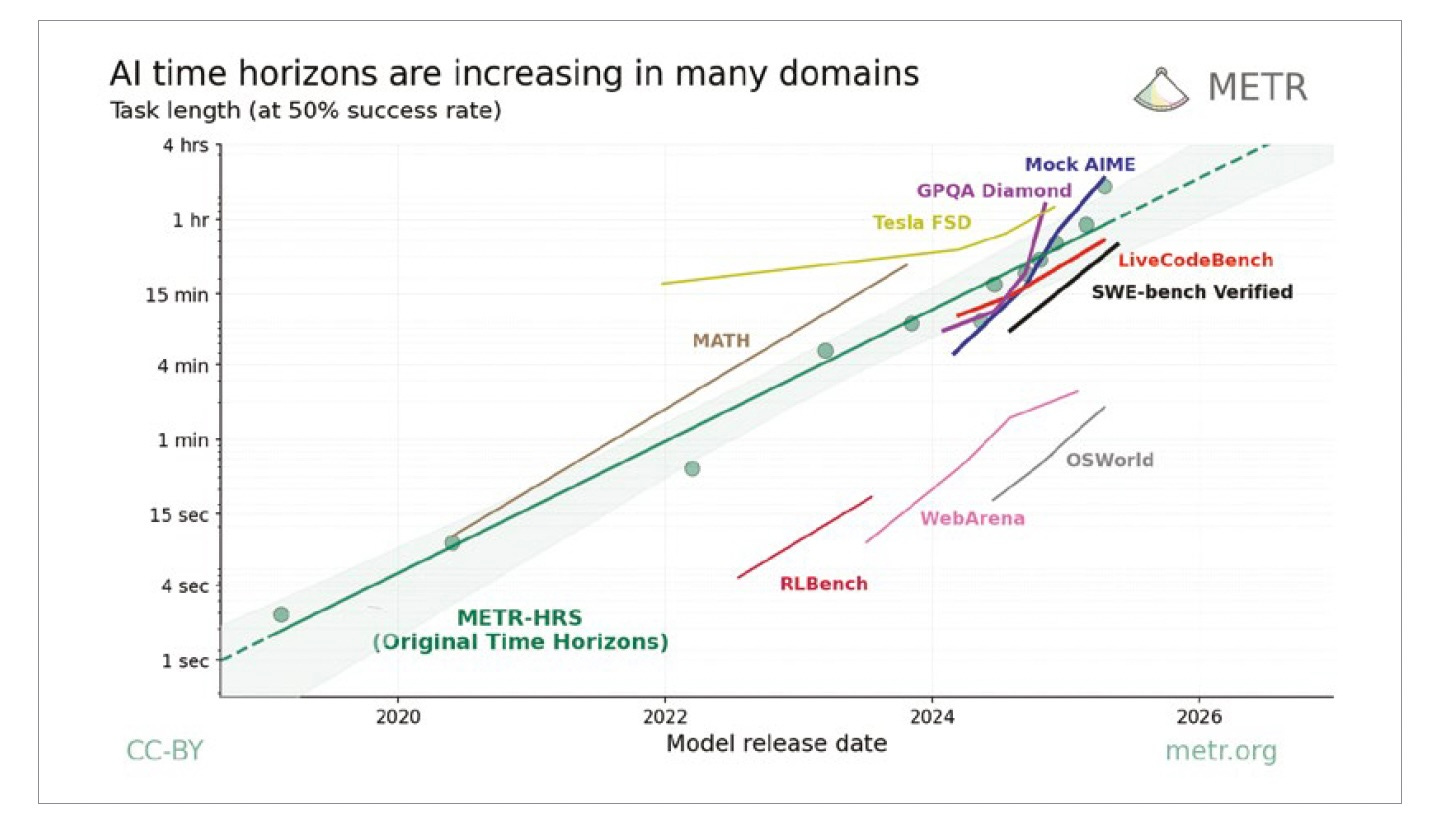
The METR curve is not a technical curiosity. It is the investment calendar of the agentic transition. It sets the pace at which entire categories of knowledge work transition from labor-denominated to inference-denominated. Every business model premised on the stability of a specific domain’s labor structure has an expiration date governed by this curve.
Since the original analysis, the evidence base has shifted from academic reasoning benchmarks toward work-realistic agent benchmarks: GDPval-AA for economically valuable knowledge work, Terminal-Bench 2.0 for autonomous computer use, and updated METR time horizons. These benchmarks strengthen the thesis because they measure not merely whether models can reason, but whether agents can execute bounded professional tasks under constraints around tool access, memory, and verification.
The curve tells us where the frontier is heading. The next section shows where it has already arrived.
Software Engineering: The First Crossing
On the original SWE-bench released in October 2023, the first RAG baseline scored just 1.96%, and the first agent-based system (SWE-agent, early 2024) reached 12.47%. On SWE-bench Verified (OpenAI’s human-filtered 500-task subset introduced August 2024), top agents scored ~20% at launch and ~80.8% by Claude Opus 4.6 in February 2026.
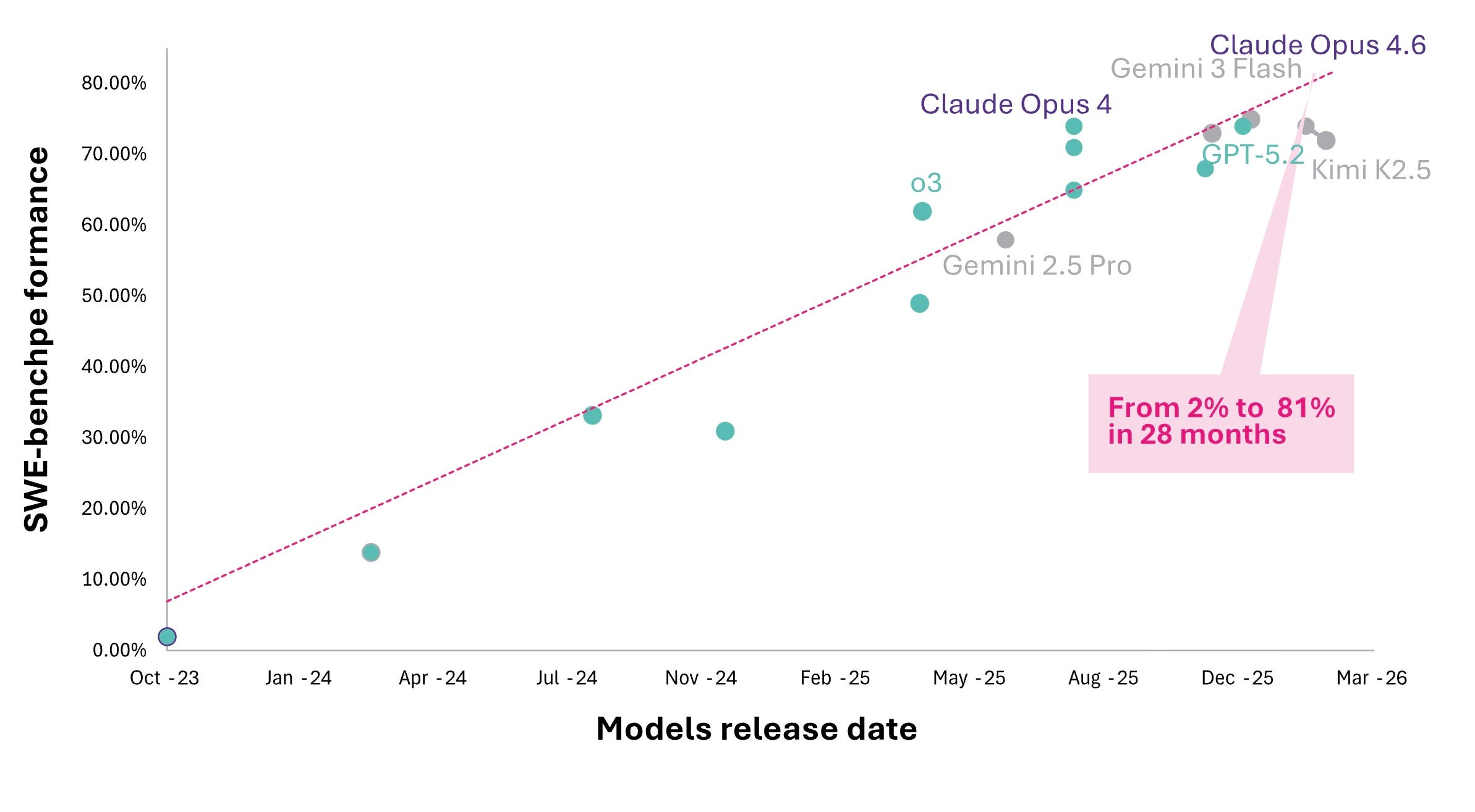
From 2% to 81% in twenty-eight months. What required a team of engineers two years ago now completes in minutes. Not in a research lab. In a production API that any developer can call today.
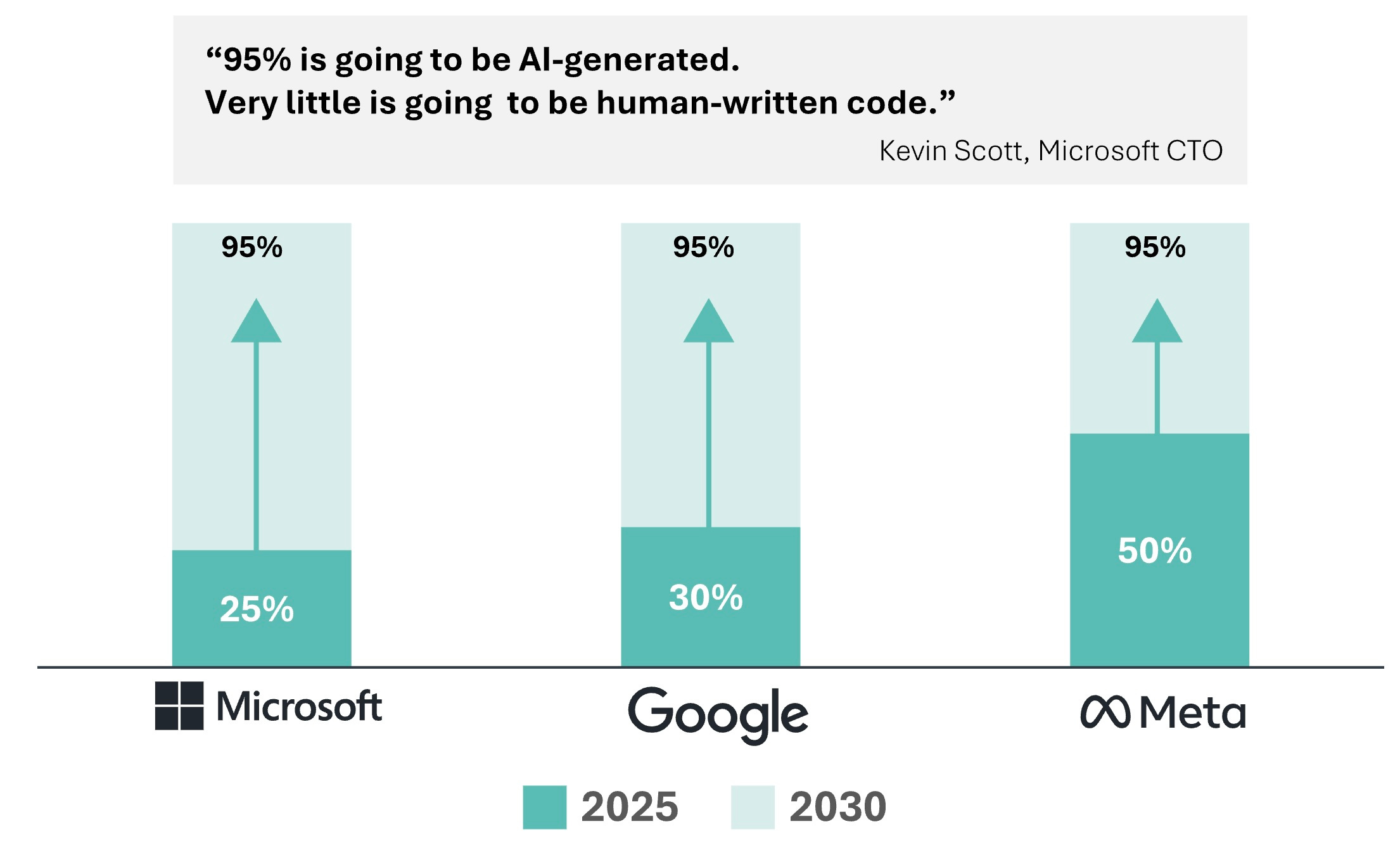
AI now writes more than 30% of code at both Microsoft and Google. Meta CEO Mark Zuckerberg stated in April 2025 that he aspires to have most of Meta’s code written by AI agents in the near future.
The benchmark frontier has also evolved beyond isolated software engineering tasks toward full operational execution environments. While SWE-bench assesses whether models can resolve bounded code repository issues, Terminal-Bench 2.0 evaluates whether agents can operate autonomously in real terminal environments spanning software engineering, infrastructure management, cybersecurity, data science, and system administration.
Terminal-Bench 2.0 demonstrates that frontier agents are rapidly improving at operating inside real computing environments, not merely generating code or answering questions. This matters because it measures not merely whether models can generate correct code, but whether agents can navigate tools, execute commands, recover from failures, maintain state across workflows, and complete production-like operational tasks. The significance for the agentic thesis is profound: the frontier is shifting from models that answer questions to agents that perform economically valuable operational work, suggesting that the primary bottleneck is increasingly not raw intelligence itself but the orchestration, supervision, verification, and control infrastructure required to reliably govern autonomous execution at scale.
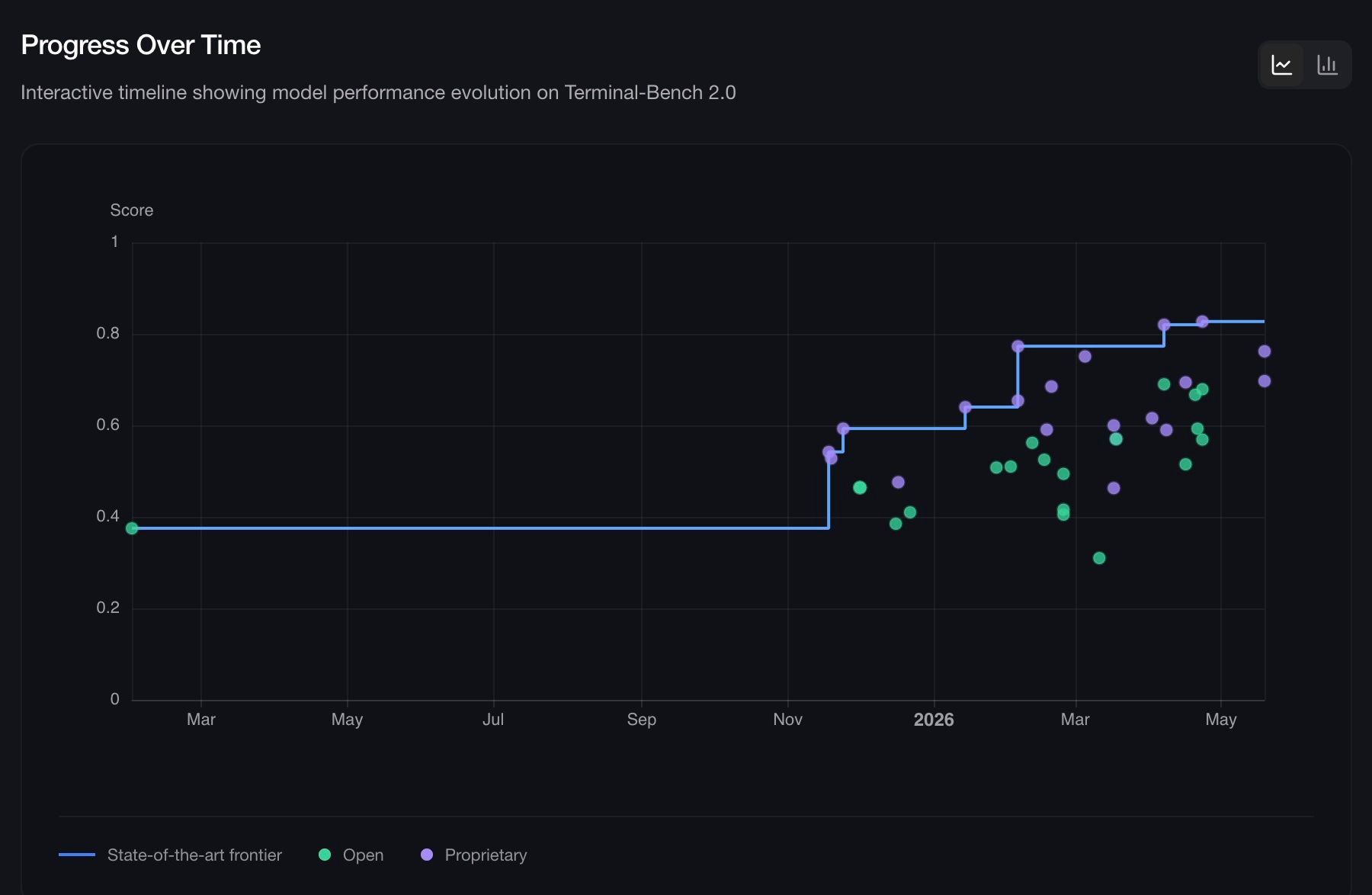
Software engineering is the first domain to cross the reliability threshold, serving as the template for all that follows. Coding requires understanding complex structured information, reasoning about dependencies, using tools precisely, iterating based on feedback, and maintaining context across long sequences. But the capabilities that crossed in coding generalize to any domain involving structured reasoning, tool use, and verifiable outputs: legal document analysis, financial modeling, medical diagnosis, and compliance reporting. The order of crossing in terms of which domains follow software engineering, and on what timeline, is governed by the METR curve and by the specific conditions of verifiability, task structure, and economic leverage that each domain presents.
Intelligence Is Sufficient. The Question Has Changed
The argument of this chapter is cumulative. The cognitive primitives for production agentic work exist across multiple vendors. The reasoning behind them is genuine, not pattern-matching, and scales with inference-time compute.
That reasoning can be sustained across the full scope of professional work through million-token context windows that retrieve and reason accurately. The sensory range spans the full spectrum of professional inputs via natively multimodal architectures.
The capability frontier is advancing on a measurable, predictable schedule, doubling every seven months. In software engineering, the crossing has already occurred, from research curiosity to production deployment, generating billions in revenue in twenty-eight months. AGI is not required. Current frontier capability is sufficient. The paradigm has shifted not because machines became perfect, but because they became actors capable of receiving goals, taking autonomous action, and delivering professional-grade outcomes.
The question now is whether the agents built on that intelligence, the systems that coordinate, remember, act, and learn, are ready for production deployment at enterprise scale. And whether the infrastructure beneath them can serve the workloads the agentic economy demands.
The views and opinions expressed in this publication are those of the author alone and are based on publicly available information. The expressed views and opinions do not constitute investment advice, a solicitation, or a recommendation to buy or sell any security or financial instrument. The author may hold positions in the securities of companies mentioned. Certain companies referenced may be current or former clients of, or counterparties to, the author or affiliated entities; such relationships will be disclosed where applicable. Past performance is not indicative of future results. To the fullest extent permitted by applicable law, the author does not accept any liability for any loss or damage arising from reliance on this content. Readers should conduct their own independent due diligence and consult a qualified financial advisor before making any investment decision.