
MiniMax IPO: What China LLM Reveals About the Economics of Intelligence
Our S-1 teardown applies the Durable Growth Moat methodology to this landmark public offering.


Decoding Discontinuity is a strategic advisory and investment platform focused on the structural impact of generative and agentic AI. We develop proprietary frameworks for analyzing how companies are positioned to adapt to generative and agentic AI. This month, we are publishing a 36-page teardown exclusively for our Institutional clients that applies our pioneering Durable Growth Moat™️ analytical framework to the prospectus of MiniMax, a landmark IPO in the LLM space.
Learn more about how to become an Institutional client.
Paid subscribers get access to the executive summary of the report, which includes the Durable Growth Moat score and our overview of MiniMax’s position.
Three years after ChatGPT was released to the public and triggered a wave of discontinuity, two foundational model companies will test the public markets this week when China’s Zhipu AI begins selling its shares via the Hong Kong exchange on January 8, followed one day later by rival MiniMax Group.
This is potentially a watershed moment for the AI industry for many reasons. While both offerings make for fascinating case studies, I want to focus on the MiniMax IPO because it is more of a pure LLM play. Zhipu AI (officially Knowledge Atlas Technology and operating internationally as Z.ai) is more of a full-stack foundation model provider with deep government ties and a model that is a hybrid of OpenAI and Palantir.
To understand the real significance of this moment, we need to dive into three separate but closely related aspects of the MiniMax IPO that I believe are particularly essential: First, as I just noted, it is the first pure LLM IPO globally. It is not bundled with cloud infrastructure, enterprise software, hardware, or consumer platforms. It sells models. This makes it the cleanest test case for foundation model economics we have seen.
Second, it positions itself at the frontier of agentic AI. This is not marketing fluff, but an architectural and strategic commitment. As I have argued previously, the shift from pure model quality to orchestration represents a fundamental transition in how AI systems will be deployed. MiniMax is betting that agentic execution, rather than raw model performance, will define the next control layer.
Third, it will go public ahead of US peers, forcing global investors to confront the economics of foundation models before US narratives are fully defined. The discontinuity of generative and agentic AI has smashed the previous technology economics paradigm, but the new paradigm of the Agentic Era, what I call Orchestration Economics, has not fully formed. For a company like MiniMax, there isn’t even a hype cycle of LLM IPOs to ride. There is no comparable trading comp. There is only the prospectus, the benchmarks, and the business model.
For these reasons, MiniMax is the perfect case study. Not because it answers whether Chinese open source will dominate AI. But because it will offer a valuable verdict of the market’s view on a key economic aspect of foundation models operating under real conditions:
What would a durable growth moat look like for a standalone LLM?
Does MiniMax plausibly exhibit its early contours?
The LLM IPO Challenge
MiniMax may be the first LLM IPO of 2026, but it may not be the only foundation model company expected to go public in 2026. Reports are that Anthropic and OpenAI are preparing IPOs.
Just a couple of years ago, this would have been surprising.
The conventional wisdom until recently was that the application companies built on top of models would make better bets for investors. In contrast, the models that enabled these applications were capital-intensive, compute-hungry, structurally loss-making, even if they were strategically essential. The consensus was clear: high fixed costs, weak differentiation, unclear pricing power, and no obvious path to durable margins. Applications were supposed to capture value; models were supposed to commoditize. The smart money flowed accordingly.
And yet, in 2026, the foundation models are first in line with IPOs. Not the application leaders.
This is a remarkable reversal. But the reason is structural. Foundation models need public markets the most.
As long as we remain in the transformer paradigm, where scaling laws continue to prevail, better models require more compute. More compute requires more capital. Private markets, even at their current scale, are not designed to finance perpetual, frontier-level training races. IPOs are not a sign of maturity. They are a financing instrument.
Consider the economics. OpenAI is projected to burn through over $5 billion in 2026. MiniMax’s prospectus reveals it spent over $150 million on cloud bills in 2025 alone, with R&D consuming approximately $250 million, roughly 90% of which goes to hardware. Against revenue of $53 million through September 2025, the company posted losses of $211 million.
This is not a bug in the business model. It is the business model. And compared to the current economics of the big US LLMs, these economics are better and offer a higher probability of reaching sustainability. (With the caveat, of course, that there are never any guarantees.)
Against this backdrop, OpenAI and Anthropic are widely expected to pursue US listings in 2026, with Anthropic likely moving first. Both have reached a scale where remaining private constrains strategic optionality.
And yet, MiniMax highlights an important twist to this narrative.
The most interesting development is not that US players are preparing to go public. It is that Chinese players moved first.
At the same time that US foundation model companies are preparing for IPOs, a second dynamic has been accelerating in parallel: the rapid rise of Chinese open and semi-open models.
What began in 2025 as a (big) surprise with DeepSeek became, in 2025, a structural shift. Models such as Alibaba’s Qwen, DeepSeek, and Kimi K2 no longer merely “caught up.” In several benchmarks, they reached the frontier, and in some cases, surpassed closed Western models. The implication is not that Chinese models are universally superior, but that the performance gap narrowed faster than most investors expected.
We should see a bis repetita of that shock next month when DeepSeek releases its R2 model with significant training efficiencies, that actually change existing scaling laws.
Indeed, DeepSeek’s latest training paper, released last week, focuses on training efficiency rather than brute-force scaling. The research claims 20-30% better scaling efficiency through architectural innovations like optimized hyper-connections. If sustained, this line of research challenges a core assumption embedded in US AI valuations: that only massive capital expenditure can sustain frontier performance.If R2 effectively demonstrates that “Hyper-Deep” models can outperform traditional transformers without the quadratic cost wall, it will force a total re-valuation of every closed-source IPO currently in the pipeline. But that is in one month, which seems forever in the space.
This is not a hypothetical concern. It is becoming a pricing and valuation reality.
And that brings us back to MiniMax.
On December 31st, MiniMax released a 760-page IPO prospectus. Its trading debut is scheduled for January 9th, targeting a valuation of $6-$7 billion and seeking to raise $500-$600 million.
The valuation is notable not for its ambition, but for its modesty. Compare this to OpenAI’s rumored $800 billion to $1 trillion valuation, and the efficiency gap becomes stark. MiniMax is attempting to compete at the frontier with a fraction of the capital intensity of its US peers.
Let’s take a closer look at how the company plans to do that and the broader implications.
What Is MiniMax?
MiniMax is a leading Chinese artificial intelligence company based in Shanghai, founded in December 2021. It specializes in developing large language models (LLMs) and multimodal AI technologies that handle text, images, voice, and video generation. Often dubbed one of China’s “AI Tigers” alongside firms like Moonshot AI, Baichuan, and Zhipu AI, MiniMax focuses on co-creating intelligent systems with users and has gained attention for products like the Talkie AI companion app. Its models, and notably the latest M2.1 rank within the highest scored models.
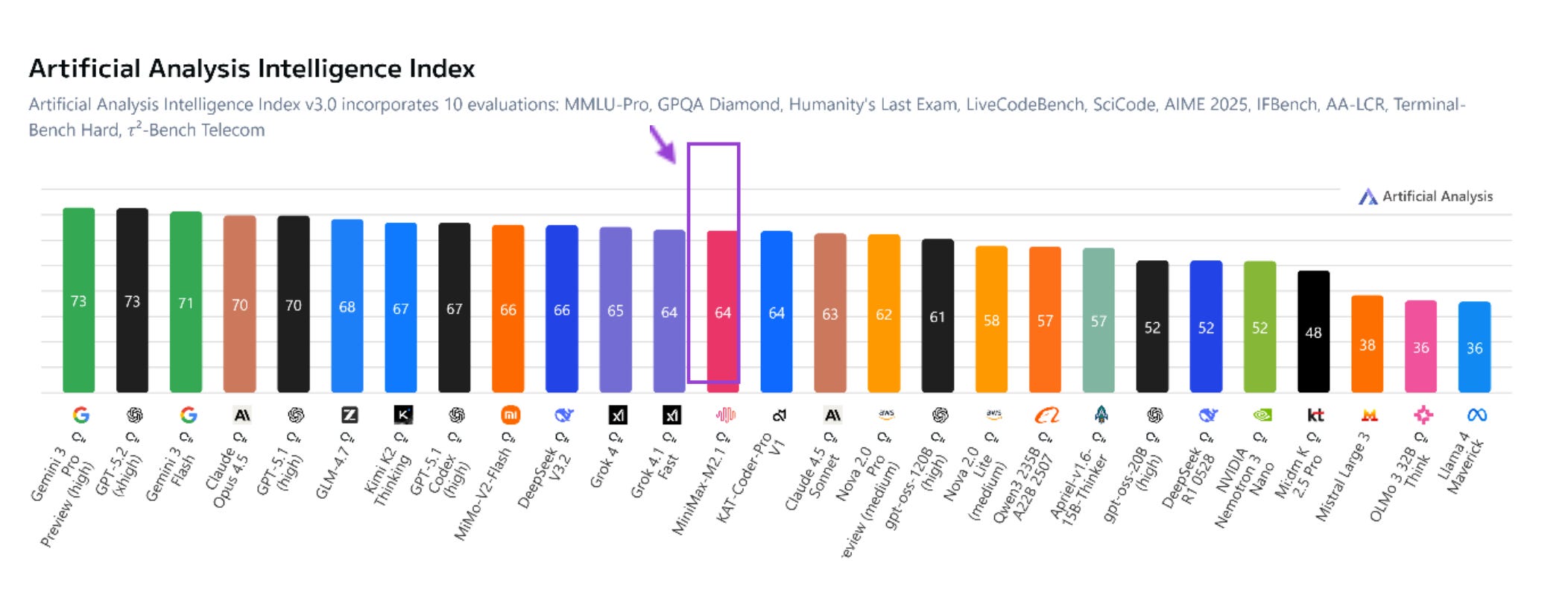
Figure 1. Artificial Analysis Intelligence Index (Source : Artificial Analysis)
MiniMax is best understood as a hybrid foundation model company, spanning both consumer and enterprise markets. In this respect, it resembles OpenAI more than Anthropic.
On the consumer side, MiniMax’s strategy goes beyond a single ChatGPT-style interface. Rather than positioning one canonical product, it experiments across multiple consumer surfaces, most notably Talkie, an AI roleplay platform with high retention driven by emotional simulation (approximately 35% of revenue), and Hailuo AI, a video generation tool (33% of revenue). The remaining 29% comes from B2B API access.
Revenue growth has been substantial: 130% year-over-year, from $30 million in 2024 to $53 million through the first nine months of 2025. But the consumer play is not frivolous. It serves a strategic purpose: rapid iteration loops, diverse usage patterns, and optionality on viral adoption. Sounds familiar?
But it also carries risk. Consumer attention is fickle, and consumer AI products have not yet demonstrated durable retention or willingness to pay at scale. Moreover, MiMimax faces an ongoing intellectual property lawsuit from Disney and Universal over Hailuo’s video generation capabilities. It’s a reminder that regulatory and legal risks compound alongside technical ones.
On the enterprise side, MiniMax positions its models for widespread use rather than absolute frontier dominance. The implicit assumption is that many enterprise workloads do not require the very top of the performance curve. They require reliability, cost efficiency, and integration into existing workflows.
This is pragmatic positioning, but it carries risk. Enterprise buyers may consolidate around a smaller number of “trusted” model providers over time. Being good enough is not the same as being strategically essential. And in enterprise AI, trust compounds faster than performance.
Where MiniMax differentiates most clearly today is in agentic coding.
Its models show state-of-the-art performance in certain agentic coding benchmarks and workflows. This has translated into real developer adoption and early enterprise traction. The company reports meaningful revenue from customers using its models for code generation, debugging, and increasingly, autonomous coding tasks.
The strategic logic is clear. Coding is not just another application domain. It is a gateway to autonomous task execution, system orchestration, and ultimately, control over how work gets done. If intelligence becomes infrastructure, the companies that control how that infrastructure operates will capture disproportionate value.
But this is also where durability questions begin.
Is coding a wedge, or a moat?
At present, it is too early to say. The agentic coding market is nascent, workflows are evolving, and developer loyalty remains fluid. Anthropic is arguably ahead in enterprise credibility and safety-aligned positioning, particularly in regulated environments. GitHub Copilot has distribution. Cursor has product-market fit with developers.
MiniMax’s bet is that technical leadership in agentic execution can translate into structural control. That is a plausible, but unproven path.
Architectural Innovation: Directional, Not Yet Foundational
MiniMax has published meaningful architectural research, including a notable paper earlier this year on efficiency improvements in transformer training. The work suggests genuine ambition to move beyond pure scaling.
MiniMax’s technical positioning rests on three architectural choices that distinguish it from both Western closed-source models and Chinese competitors:
First, hybrid Lightning Attention. While the M2 release temporarily reverted to standard Transformer architecture due to training instability, the December 2025 M2.1 reintroduced linear attention through a hybrid design. This enables native processing of up to 4 million tokens - roughly 20-30× the context window of most frontier models (128-200k). For enterprise coding workflows involving entire repositories or complex financial documents, this is major. It eliminates the need for retrieval-augmented generation (RAG) systems, reducing both infrastructure costs and latency.
Second, Mixture-of-Experts efficiency. The M2.1 model achieves 230 billion parameters with only 10 billion activated per forward pass, fitting the entire model in 230GB. This means it runs on commodity hardware - a 256GB Mac Studio can execute it locally per experts. For enterprises requiring on-premise deployment or air-gapped environments (financial services, healthcare, defense), this creates optionality that multi-trillion-parameter models cannot provide.
Third, native multimodality from inception. Unlike models that bolt vision or voice capabilities onto text-primary architectures, MiniMax trained across text, speech, music, and video simultaneously from day one. This manifests in Hailuo’s video generation capabilities and Talkie’s integrated text-voice-visual experiences. The company’s 88.6% score on VIBE (Visual & Interactive Benchmark for Execution) - which measures an agent’s ability to not just write code but visually verify and interact with the resulting UI - suggests genuine integration rather than surface-level multimodal “wrappers.”
However - and this is critical for investors – some of these advantages are real but incremental, not fundamental.
MiniMax’s Lightning Attention approach can be seen as a sophisticated engineering “patch” rather than a mathematical breakthrough. DeepSeek’s December 2025 paper on manifold-constrained hyper-connections (mHC) demonstrates a more “elegant” solution to the training stability challenges MiniMax still navigates through hybrid architectures and careful hyperparameter tuning. The cost advantage versus Claude is meaningful - roughly 3-5× after adjusting for model verbosity - but nowhere near the “8% of cost” marketing claim that ignores output token inflation.
US closed-source providers should pay attention, not because MiniMax threatens to displace frontier models, but because it demonstrates that architectural efficiency creates real deployment advantages in specific segments. And thus accelerates path to profitability. The question is whether these advantages compound into durable moats or erode as capability convergence accelerates.
Not a Pure China Story
One underappreciated element of the MiniMax prospectus is its geographic revenue mix.
Only 26% of revenue comes from China, while 20% comes from the US, with the remainder distributed across Singapore and other markets. This is not a company positioning itself as a purely domestic Chinese champion. It has customers in North America. It has developer adoption outside China. It is targeting global LLM infrastructure, not national infrastructure.
That does not eliminate geopolitical risk. But it complicates the narrative. MiniMax is positioning itself as a global LLM provider, not a national one. This creates optionality: partnerships, cross-border relevance, and potential strategic interest from global players who need agentic capabilities and cannot rely solely on US providers.
For US investors, this matters. It suggests that MiniMax is not simply an arbitrage play on China’s AI development. It is a bet on whether a non-US foundation model company can achieve global relevance in a fracturing geopolitical environment.
That is a harder question to answer. But it is potentially a more valuable one.
The Core Investment Question: Why Own a Loss-Making LLM?
At the heart of MiniMax’s IPO lies an uncomfortable reality.
The company is not profitable and won’t be soon. A significant share of its revenue will continue to be spent on training compute. Gross margins, while improving, remain at 23%. But that’s roughly half the ~50% margins projected by US labs like Anthropic for 2025.
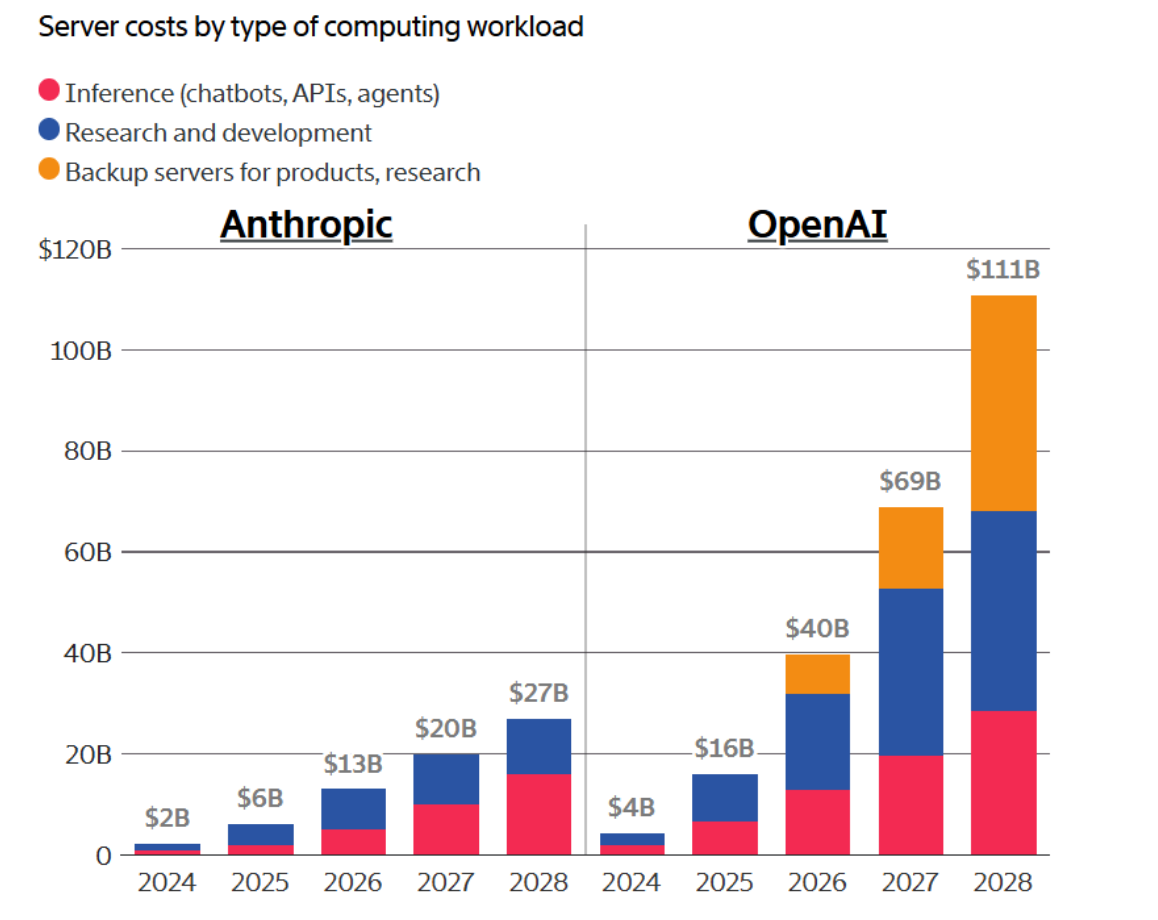
Figure 2. Server costs by type of computing workload (Source : The Information)
Yet there are signs of structural improvement. MiniMax has reduced inference costs by 45% year-over-year, suggesting that operational efficiency could ease margin pressures faster than the market expects. Still, the path to profitability remains distant and contingent on execution.
So why would a rational public-market investor buy the stock?
The answer cannot be earnings. It cannot be near-term margins. It cannot be predictable cash flows or traditional valuation multiples.
The only credible answer is optionality on control.
Investors are effectively buying a claim on one of four outcomes:
MiniMax becomes a control point in agentic AI workflows. If the shift to orchestration accelerates and MiniMax establishes itself as the preferred model for autonomous task execution, it could extract durable rents from that control layer. This is the bull case. It requires sustained technical leadership, ecosystem development, and network effects that have not yet materialized.
It achieves sufficient scale and efficiency to sustain independent frontier competition. If MiniMax can continue improving performance while maintaining cost efficiency below US peers, it could carve out a durable position as the “efficient frontier” alternative. This is the base case. It requires relentless execution and capital discipline in an environment where neither is guaranteed.
It becomes a strategic acquisition target for a global LLM provider seeking to win the agentic race. If agentic AI proves strategically essential and MiniMax demonstrates technical credibility, it could be acquired by a hyperscaler, enterprise software provider, or hardware company looking to integrate foundation models into their stack. This is the exit case. It requires maintaining relevance long enough to be valuable to someone else.
It becomes a defensible consumer AI platform that transcends “AI companions” by creating a new category of mainstream entertainment or social experience where AI is invisible infrastructure, not the product. This would require delivering exceptional engagement (70+ minutes/day), deep multimodal integration, and tens of millions of user-created characters that suggest MiniMax is tapping into “AI that helps you feel,” with growing network effects and content moats that are structurally more defensible than model-centric chatbots. If this evolution succeeds, MiniMax captures platform-level value and optionality far beyond cash-flow AI apps; if it fails, the consumer business risks commoditization alongside other persona-based chat experiences.
If none of these materialize, the equity is structurally fragile.
This is not a comfortable traditional investment framework. It is not a DCF. It is not a classic multiple. It is a bet on structural position in an emerging architecture with all the attendant uncertainty that implies.
Execution, Consolidation, and the Geopolitics of AI
Execution will determine everything.
China’s AI market is already brutally competitive. As mentioned, MiniMax is not alone in seeking public markets. Zhipu AI, another Chinese foundation model company with similar loss profiles and revenue between $150-180 million, is pursuing its own IPO in parallel.
The near-simultaneous listings will establish precedents for how public markets price loss-making, compute-intensive intelligence infrastructure. Globally, the competitive environment is even harsher. Margins are under pressure, differentiation is fleeting, and customer switching costs remain low. Foundation models, unlike SaaS platforms, do not benefit from data lock-in or workflow integration by default. They must earn durability through continuous performance improvement or ecosystem control.
MiniMax could emerge as a durable, independent foundation model company, a consolidator or acquisition target or a casualty of commoditization.
Which outcome prevails will depend not only on technology, but on rules that do not yet exist.
The geopolitics of AI includes export controls, model access, capital flows, regulatory regimes, and the fracturing of global AI infrastructure into regional spheres. These factors will shape valuation as much as benchmarks. This is not a hypothetical risk. It is a structural uncertainty embedded in the business model.
Consider the regulatory landscape. If the US tightens export controls on advanced chips, MiniMax’s ability to scale compute could be constrained. If China restricts data flows or mandates local model deployment, MiniMax’s global ambitions could be limited. If Europe implements strict AI regulation, enterprise adoption could slow. Conversely, state support could create asymmetric advantages. Competitors like Zhipu have secured government contracts that provide revenue stability and implicit endorsement.
These are not edge cases. They are baseline scenarios.
For US investors, this creates a paradox. The very factors that make MiniMax interesting are its global positioning, its technical credibility, and its potential as a non-US alternative. Yet those are also the factors that make it geopolitically exposed.
What This Reveals About Foundation Model Economics
The MiniMax IPO is not just about one company. It is a stress test for an entire category.
It forces us to confront three fundamental questions that will define AI investing in 2026:
First: Can foundation models sustain independent economics?
The consensus a year ago was no. Models would commoditize, applications would capture value, and foundation model companies would either become infrastructure utilities or get acquired. MiniMax is testing whether that consensus was wrong or premature.
The evidence is mixed. On one hand, gross margins remain compressed, and cash burn is substantial. On the other hand, inference costs are falling faster than expected, 45% year-over-year for Minimax. This suggests that operational leverage could materialize sooner than traditional scaling curves would predict. If efficiency improvements continue to outpace performance requirements, the economics could stabilize before public markets lose patience.
Second: Is agentic AI a durable control layer, or a transient performance advantage?
If orchestration becomes the new messaging—if the shift from stateless prompts to stateful workflows creates structural lock-in—then companies that control agentic execution could extract durable rents.
MiniMax is betting yes. The market has not yet decided.
Third: Can public markets price loss-making, capital-intensive intelligence infrastructure?
Foundation models are not cloud companies. They are not SaaS companies. They are not hardware companies. They are something new: compute-intensive, continuous-training, structurally loss-making entities whose value depends on sustained frontier performance. Public markets have never priced this before. MiniMax is the first test.
These are not questions with obvious answers. They are questions worth asking.
Why This Matters Beyond the IPO
MiniMax is not just an IPO. It is a reframing.
For two years, AI investing has been dominated by US narratives, US valuations, and US assumptions about moats, margins, and competitive dynamics. Those narratives have been remarkably durable, even as evidence accumulated that they might be incomplete.
MiniMax forces a different conversation.
Not because it is better than US peers. Not because Chinese models will dominate. But because it makes explicit the questions that US investors have been able to defer: What does durability mean when models are global? What does a moat look like when compute is scarce and architectural innovation is fast? What happens when the rules governing AI access, capital, and competition are still being written?
In a world where intelligence is global, compute is scarce, and moats are architectural rather than financial: What does durable growth actually mean?
That question will define AI investing in 2026.
MiniMax is the first company bold enough to ask public markets to answer it.
This is an excerpt from our full analysis of the Minimax IPO, including detailed financial adaptability analysis, single point of failure assessment, and investment framework.
For paid subscribers, we’ve published a comprehensive breakdown covering revenue composition, technical benchmarks, geopolitical risk scenarios, and valuation methodologies for loss-making foundation models.
Keep reading with a 7-day free trial
Subscribe to Decoding Discontinuity to keep reading this post and get 7 days of free access to the full post archives.