
Orchestration Economics: The Infrastructure Question (Chapter 6)
Everything, including intelligence, agents, protocols, and orchestration, runs on physical infrastructure. Chips. Data centers. Power. Cooling. Fiber. Without the substrate, nothing else exists.


This is the latest excerpt from AGNT: The Orchestration Economics Manifesto - An Investment Framework for the Agentic Era. Each Thursday, I explore a major theme of the Manifesto and unpack the frameworks, adding extra context with more recent developments. Note: The figures and sequential references are taken directly from the larger Manifesto.
The agentic economy is a software phenomenon built on a hardware foundation. That foundation is being constructed on a scale without precedent in the history of private capital allocation. But is it being constructed correctly?
When I first published this Manifesto in late April, the projected $650 billion in AI infrastructure investment in 2026 already represented one of the largest coordinated private investments in peacetime history. Since then, those numbers have continued to soar.
In May, the four largest hyperscalers reported quarterly earnings within hours of each other and raised 2026 capital spending guidance, committing between $650 and $700 billion to AI infrastructure for the year. Goldman Sachs raised its Capex spending forecast for the Big Four Hyperscalers from $4.5 trillion to $5.3 trillion through 2030. Overall, it projects $7.6 trillion of Capex spending between 2026 and 2031 across compute, data centers, and power.
The problem remains, however, that much of this capital is also being committed under assumptions that are already shifting.
The capital was designed for training. The agentic economy runs on inference. The cloud was designed for stateless applications. Agentic workloads are stateful, persistent, and coordination-intensive. The power grid was designed for variable demand. Inference generates a continuous baseload.
The infrastructure does not need to stop being built. It needs to change what it is becoming. This chapter traces that metamorphosis, from the capital flowing in, through the balance sheets absorbing it, to the financing structures underwriting it, to the inflection point where the workload changes, to the efficiency gains that determine the unit economics, to the energy constraint that governs the speed, and finally to the architectural evolution of the cloud itself. Together, they constitute the infrastructure question on which the AGNT thesis ultimately depends.

The Buildout
The numbers announced during Big Tech earnings calls throughout 2025 arguably constituted one of the largest coordinated private infrastructure investments in history. Bloomberg estimated that the four largest hyperscalers would spend ~$650 billion in 2026. Goldman Sachs projected cumulative hyperscaler Capex of $1.4 trillion from 2025 to 2027. That is close to three times the $477 billion spent from 2022 to 2024. Leading hyperscalers have emphasized that they are primarily constrained by power and capacity, not by demand, repeatedly flagging supply bottlenecks on recent earnings calls.
Microsoft carried an $80 billion backlog of unfulfillable Azure orders due to power constraints as of January 28, 2026 (Microsoft Q2 2026 Earnings). Alphabet’s cloud backlog surged to $240 billion at year-end 2025. Amazon said new capacity “sells out immediately”.
Yet investors punished these announcements. Amazon fell 8%. Microsoft dropped ~10%. The four companies collectively shed over one trillion in market value after revealing their spending plans. By February 2026, a Bank of America survey showed overinvestment concerns at an all-time high, roughly 35% warning of excess, the highest reading in twenty years.
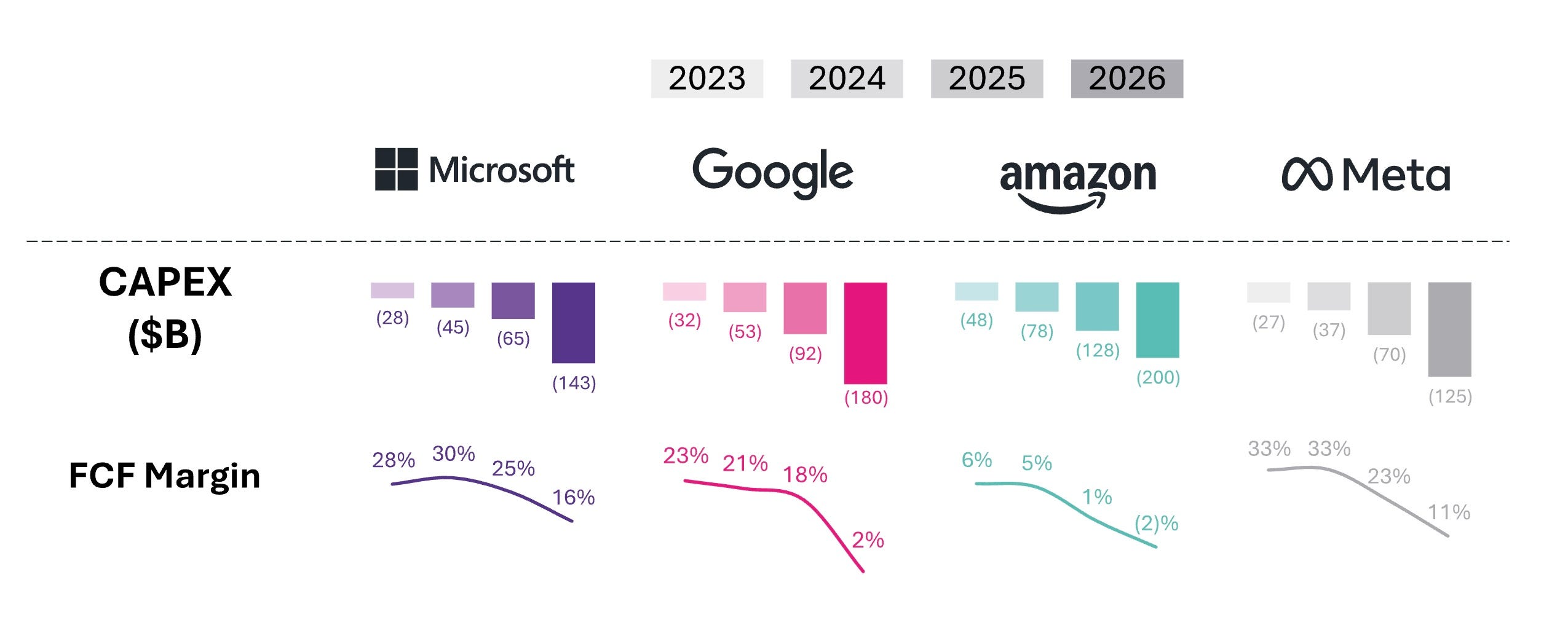
Is this Capex buying what the agentic economy will require?
The Balance Sheet Transformation
The balance sheets of the world’s most profitable technology companies underwent a structural transformation beginning in 2025. For two decades, the defining characteristic of large-cap technology was capital efficiency. It was driven by asset-light models generating extraordinary returns on modest physical investment.
That era ended when the AI buildout began. The more than fourfold increase in capital intensity from 2015 to 2026, the dollars of capital required to produce one dollar of sales, tells the story.
Cloud computing infrastructure from 2015 supported predictable workloads with well-understood utilization patterns and multi-year lifecycles. AI infrastructure serves workloads with radically different characteristics: shorter useful lives, uncertain utilization, and a pace of obsolescence that makes traditional depreciation assumptions unreliable.
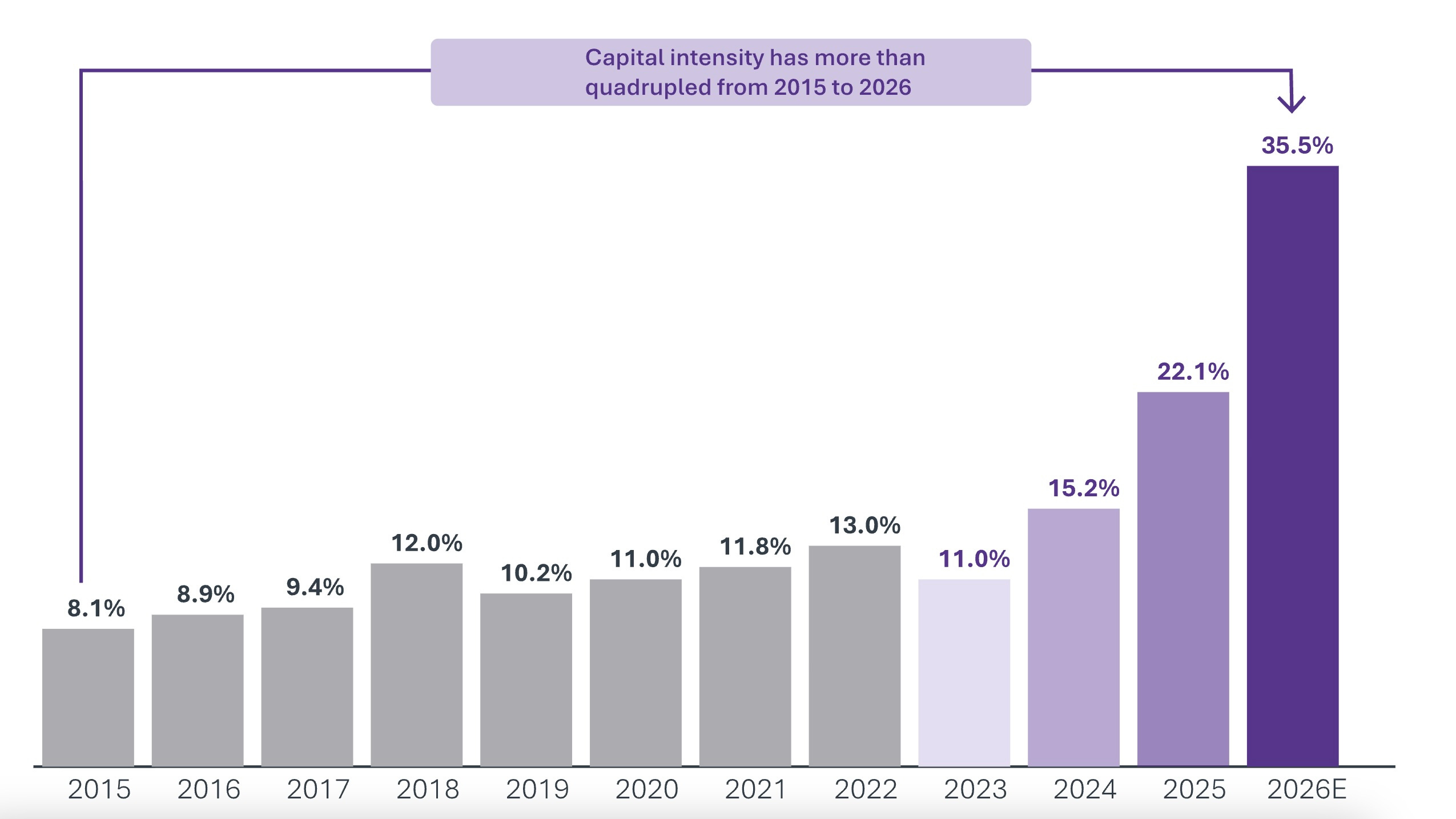
The depreciation debate alone reveals the depth of uncertainty. Amazon shortened the useful lives of a subset of its servers and networking equipment from six to five years in January 2025. Microsoft extended expected asset life in FY 2023, adding $3.7 billion in operating income from the change alone. These are not accounting technicalities. They are competing theories about how long AI hardware will retain value. The answers differ by billions of dollars.
Yet, the demand for NVIDIA H100’s has never been higher, suggesting longer utility than GAAP rules. When the industry cannot agree on whether its core infrastructure lasts one year or six, every capital allocation decision rests on a foundation of sand.
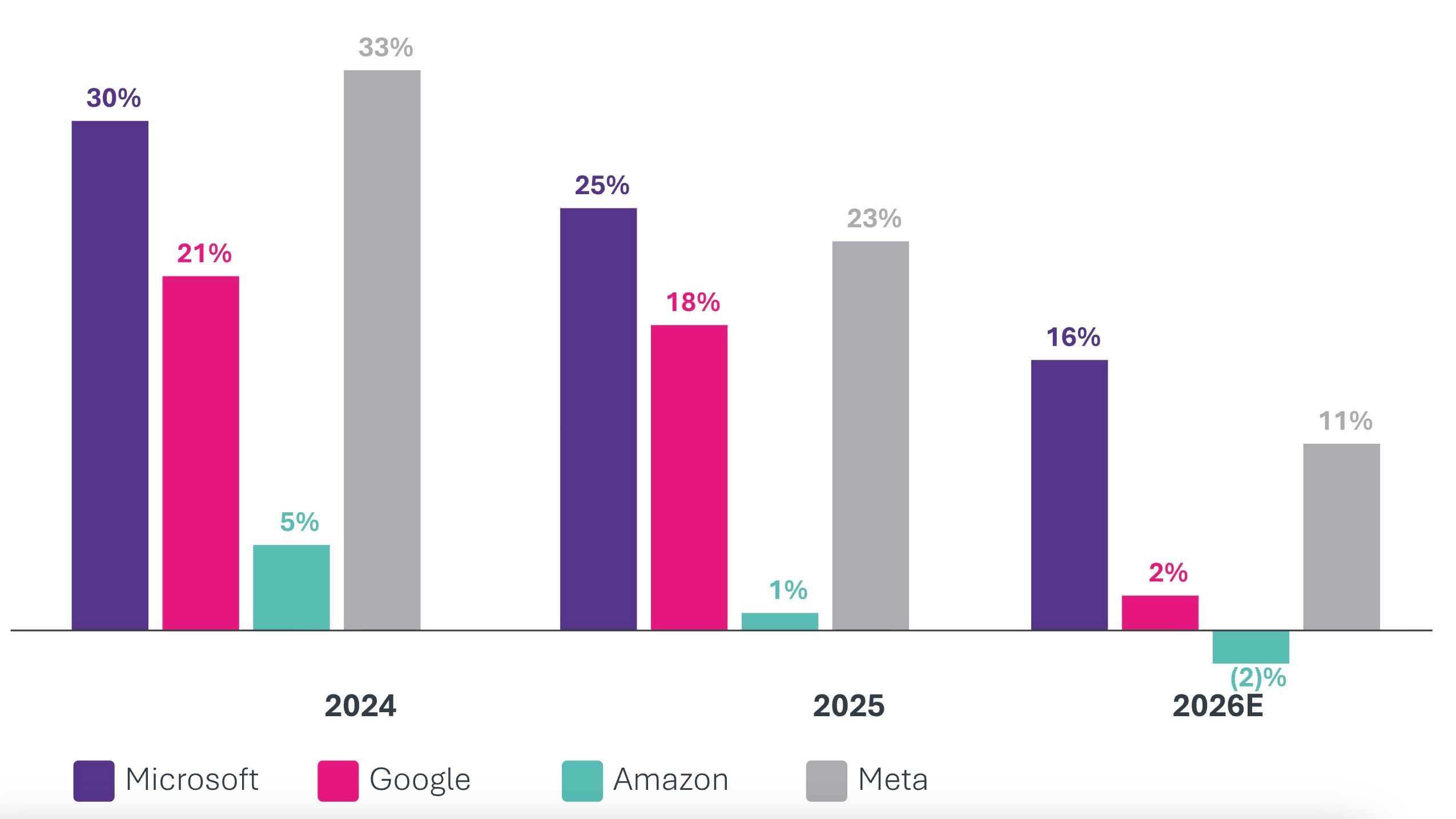
The free cash flow consequences are direct. Bank of America projected that Amazon’s free cash flow would turn negative at approximately $28 billion in 2026. Amazon filed with the SEC, indicating it may need to tap equity and debt markets. Such a statement would have been unthinkable for a company generating $638 billion in annual revenue in 2024 (and $717 billion in 2025). Pivotal Research projected that Alphabet’s FCF would plummet approximately 90% in 2026, from $73.3 billion to approximately $8.2 billion, as $175-185 billion in Capex overwhelms operating cash flow. Barclays projected Meta’s FCF to drop approximately 90% in 2026, then turn negative in 2027 and 2028.
Step back and absorb the aggregate picture. Bank of America estimates that AI Capex now accounts for 94% of hyperscaler operating cash flows after dividends and buybacks. That figure was 76% in 2024. In the span of a single year, Capex has gone from absorbing three-quarters to nearly all of the available post-distribution cash flow, substantially compressing the cushion and forcing record debt issuance. The margin for error has dramatically narrowed.
The weight of physical assets on these balance sheets means that even the most profitable technology companies in history are subject to the same economic physics that govern utilities, railroads, and industrial conglomerates. Returns on invested capital matter more than revenue growth. The companies that built their fortunes on capital-light software economics are becoming capital-intensive infrastructure operators.
The financial frameworks applied to them have not caught up.
The Debt Machine
The Big Five (Amazon, Alphabet, Meta, Microsoft, and Oracle) raised ~$121 billion in bonds in 2025 alone: Amazon $15 billion, Alphabet $25 billion, Meta $30 billion (the largest-ever individual non-M&A high-grade bond sale), and Oracle $18 billion. That’s more than three times the average of the prior nine years. Alphabet’s long-term debt quadrupled in 2025 to $46.5 billion.
Oracle, whose fiscal year 2026 ended in May, disclosed that it had raised $43 billion in debt financing and $5 billion in equity financing. The company said it plans to raise $40 billion in debt and equity financing in FY 2027.
Companies that spent decades accumulating fortress balance sheets are now leveraging them at a blistering pace.
Morgan Stanley had earlier estimated that hyperscalers will borrow ~$400 billion in 2026, double the $165 billion borrowed in 2025. On June 10, Morgan Stanley predicted that AI-related global debt issuance would double to about $570 billion in 2026. JPMorgan projects $1.5 trillion in AI-related bond issuance over the next five years.
The clearest expression of that thesis arrived in February 2026, when Alphabet issued a 100-year bond. This was the first century bond from a tech company since Motorola in 1997. The sterling-denominated tranche, part of a $31.5 billion multi-currency debt raise completed in under 24 hours, was oversubscribed by nearly 10 times. Pension funds and life insurers, institutions that match liabilities measured over generations, bought the paper at a 6.05% yield, treating Google's parent as sovereign-grade infrastructure. Alphabet sits on c.$127 billion in cash (cash, plus equivalents, plus marketable securities) and chose to borrow anyway because even that war chest looks modest against $175 – $185 billion in planned 2026 Capex.
The century bond is a statement that buyers believe this buildout is not a cyclical phase but a permanent transformation of the economy’s substrate. The last tech companies to issue century bonds were IBM in 1996 and Motorola in 1997. They did so at the zenith of their market dominance. Both subsequently declined.
At the DealBook Summit in December 2025, Anthropic CEO Dario Amodei described the high-wire financial planning. Established scaling laws, he said, are here to stay. Models get better at every task as you put more data and compute into them. But the timing of economic value remains uncertain, creating an inherent risk of under-reacting or over-extension.
Spend too little, and a company like Anthropic or OpenAI risks being unable to serve customers in two or three years. Overspend, and companies face revenue shortfalls that in extreme cases could threaten bankruptcy or tempt them to adopt what Amodei called a “YOLO” mindset.
The Fragility Beneath the Conviction
The hyperscalers can service this debt. They have investment-grade ratings, massive revenue bases, and the operating cash flow, though diminished, to cover even aggressive borrowing. The fortress is leveraged, but it remains a fortress.
The risk lies elsewhere, in OpenAI deploys the chips at CoreWeave, which has grown so quickly and so intricately that its systemic properties deserve the same scrutiny applied to any previous era of financial innovation. At the center sits a pattern of circular vendor financing.
The architecture is straightforward to describe and difficult to contain. NVIDIA invests in OpenAI. OpenAI uses the capital to purchase NVIDIA chips. NVIDIA records the transaction as revenue (subject to LOI stage; not yet binding). OpenAI deploys the chips at CoreWeave. CoreWeave secured term-loan facilities collateralized by GPUs. Institutional investors purchase the securities as infrastructure debt, providing the capital that flows back to the beginning of the cycle. The same dollar is counted as demand by the chip maker, revenue by the neocloud, and collateral by the lender.
The pattern is not novel. Classic vendor financing catalyzed previous bubbles. The 2000s telecoms collapse followed this structure, with equipment makers extending credit to customers, inflating revenues while disguising demand weakness. When customers could not pay, receivables evaporated, and cascading failures followed.
What is novel is the concentration. Telecoms vendor financing funded “the internet” broadly across hundreds of carriers and thousands of build-outs. Today’s circular deals are largely concentrated around a single company. OpenAI sits at the nexus of NVIDIA’s investment, Microsoft’s partnership, Oracle’s data center contracts, AMD’s equity-for-chips arrangement, and CoreWeave’s largest customer relationship.
The greatest risk is not that AI fails. It is that the technology succeeds while the single company around which the financial architecture has been constructed fails to build a defensible moat, triggering contagion that strands capital and stalls the buildout before the transformation completes.
Because while this concentration of relationships presents a sizable risk, it is also far from the limit. The boundaries extend far beyond this inner circle and continue to grow. Data center-related securitization via CMBS and ABS products is expected to reach $30-40 billion annually in 2026 and 2027.
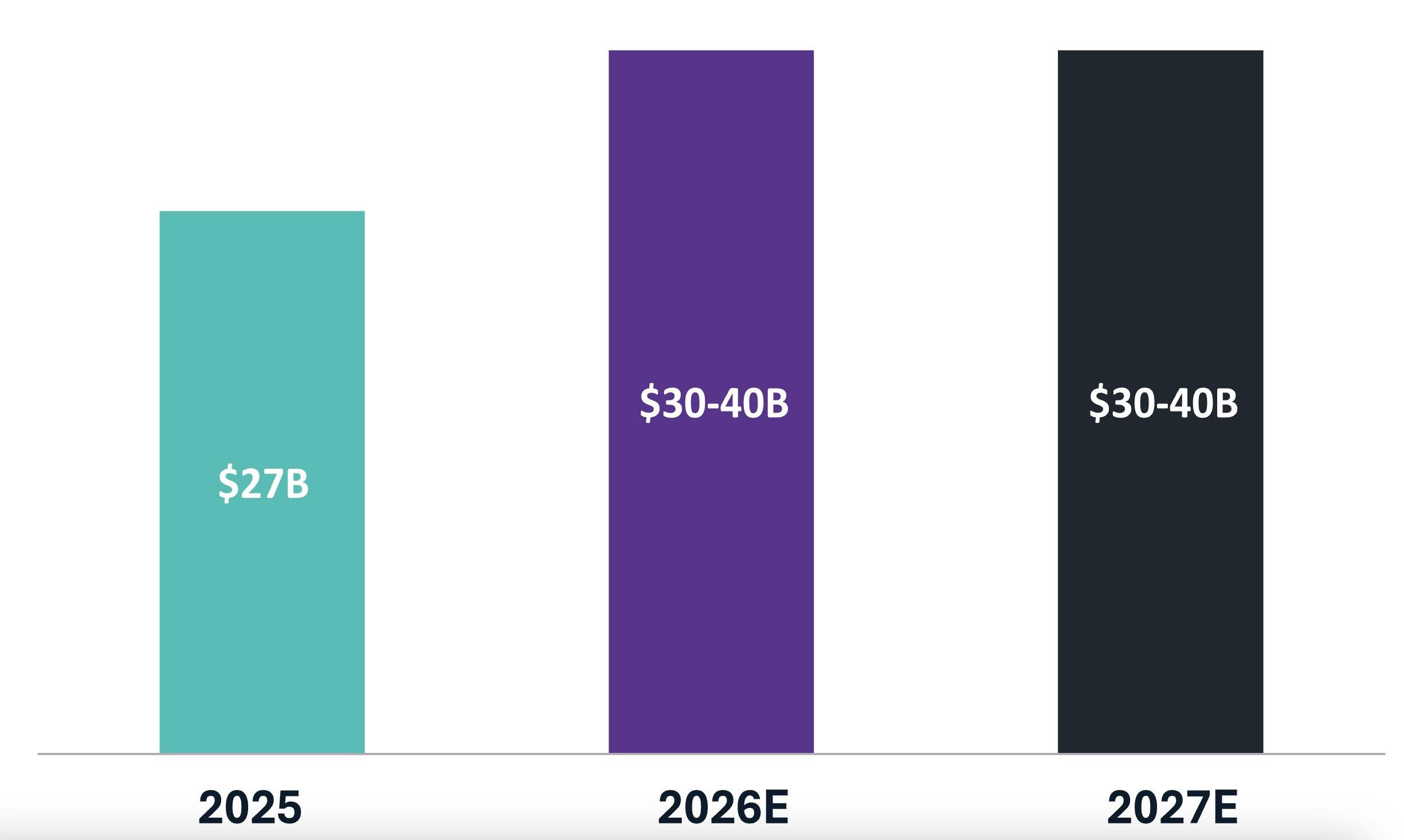
Private credit finances approximately $50 billion in AI infrastructure quarterly. The instruments are growing more complex. For GPU-backed instruments, collateral depreciation is outpacing debt amortization, even if the broader data center ABS/CMBS market is not similarly exposed (yet). And the whole structure is more concentrated around fewer counterparties than any comparable financing architecture in recent financial history.
You can be bullish on AI and bearish on this financial architecture. They are separable propositions. The technology may well deliver everything this manifesto argues it will. The question is whether the financing structure survives long enough to support the transition, or becomes the mechanism by which a sound technological thesis precipitates a financial crisis before the economics have time to prove themselves.
The financing architecture will be tested by what comes next. Because the infrastructure it underwrites was designed for a workload that is already giving way to something fundamentally different.
Two Tales of Compute
The vast majority of the capital committed in 2025 and 2026 was allocated on the assumption that the primary demand for compute would come from training frontier models.
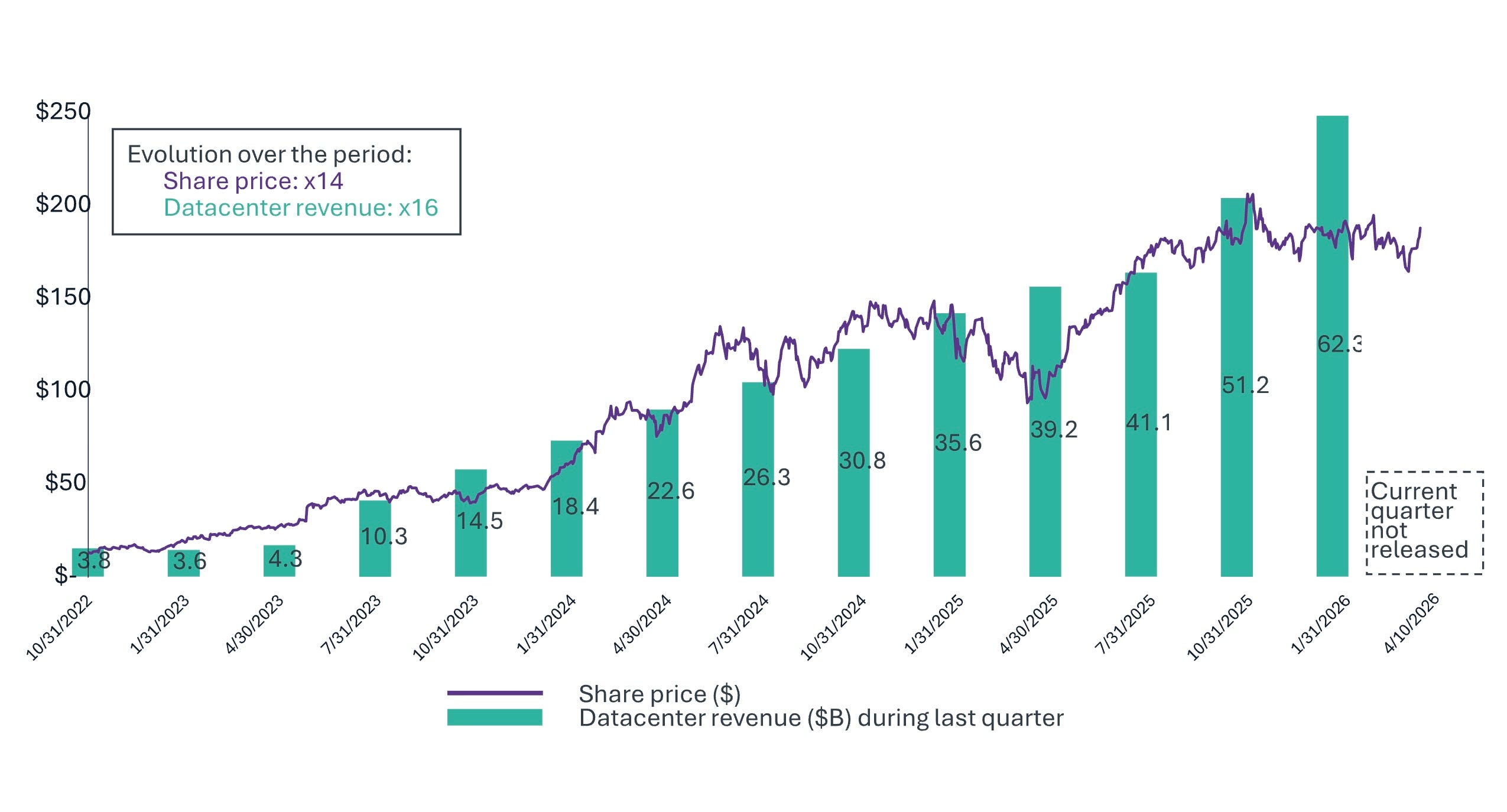
Training was the activity that the industry understood when the investment decisions were made. This means massive, centralized GPU clusters running synchronous workloads for weeks, requiring homogeneous hardware, high-bandwidth interconnects, and cutting-edge silicon. Each generation of models requires roughly ten times the compute of its predecessor. Frontier AI training costs escalated from over $100 million for GPT-4 (2023-2024) to approximately $490 million for xAI’s Grok 4 (mid-2025), with projections exceeding $1 billion by 2027.
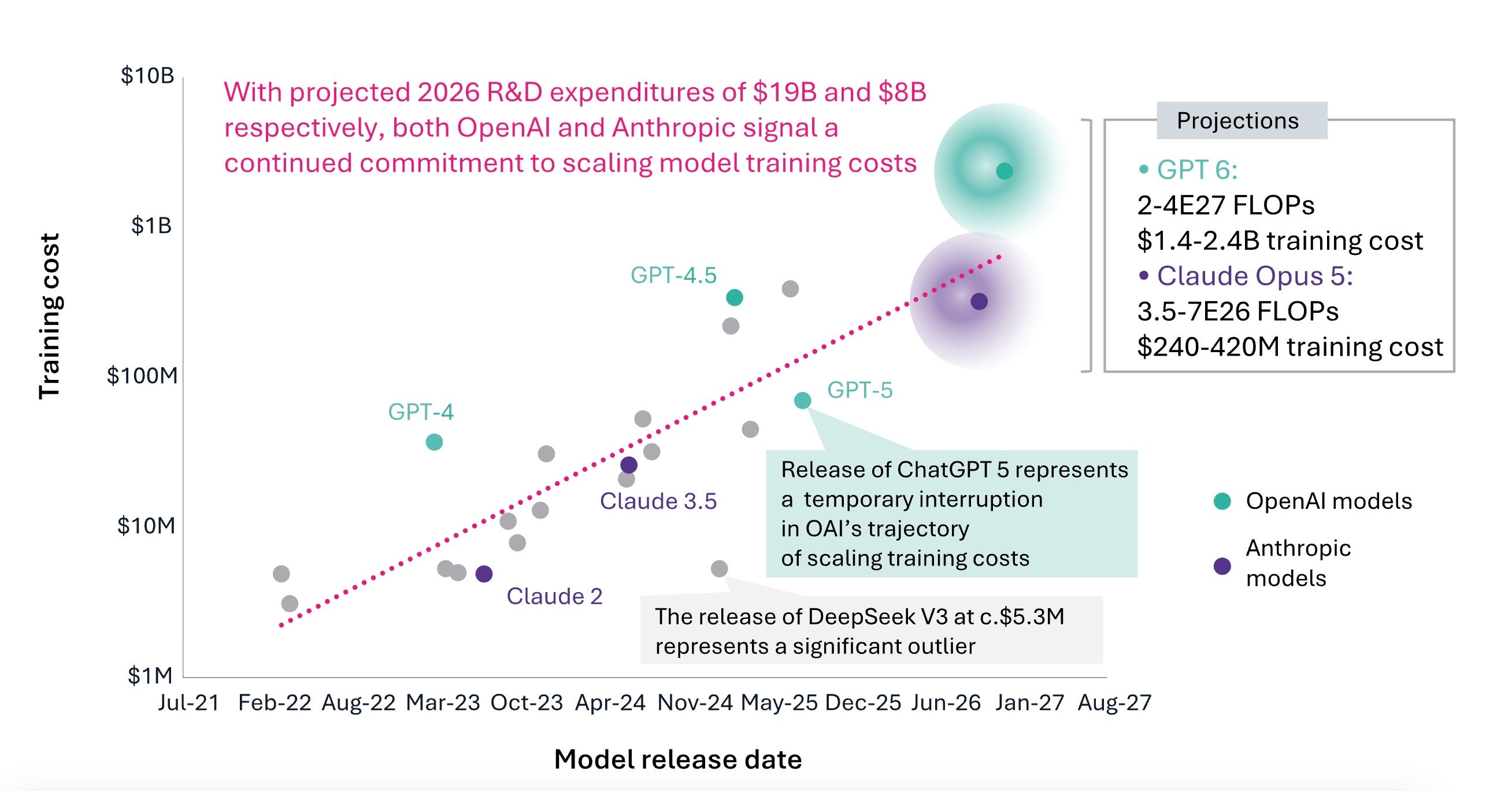
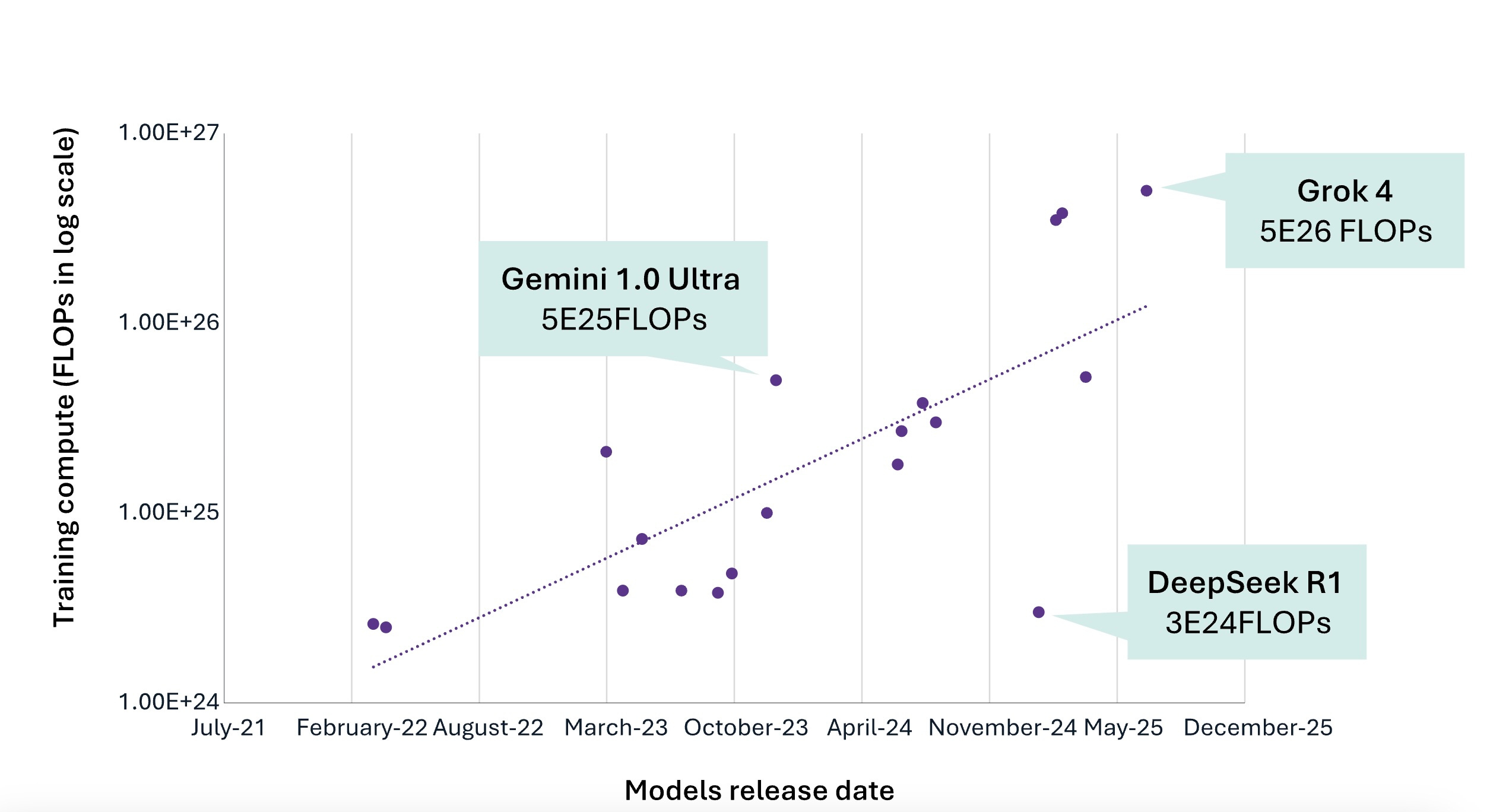
First, let us examine the tale of training compute. The hardware characteristics are distinctive. Training requires homogeneous clusters of cutting-edge GPUs with high-bandwidth interconnects, where a single GPU failure can corrupt an entire run that takes weeks of computation and costs millions of dollars. You cannot mix GPU generations or repurpose last-generation training infrastructure for new workloads without massive retrofitting.
Leading-edge racks consume 130-250 kilowatts (as of 2025), with projections reaching 900 kilowatts by 2027. Frontier training performance advantages degrade within 18-24 months, but the hardware itself retains economic utility for more than five years, typically migrating to inference or lower-tier workloads. This creates an oligopolistic market. The number of organizations training frontier models globally is perhaps fifteen to twenty:
Anthropic’s arrangement with AWS provides co-engineering of custom Trainium chips that reportedly reduce training costs by 40% compared to GPUs.
Google’s TPU advantage allows training at dramatically lower costs than GPU-based alternatives.
xAI built its Colossus cluster from site preparation to full operation in 122 days.
Access to massive, synchronized GPU clusters that require +250-megawatt data centers and billions in capital now determines who can compete at the frontier. Training compute is too strategic to outsource. Microsoft, Google, and Amazon have all reached the same conclusion.
Training is necessary. Without it, the models that power the Agentic Era do not exist. But training is not where this manifesto's thesis lives. Training is one-time Capex, concentrated among a handful of players, and depreciates in 18 months. It is the cost of building the engine.
Now, let us look at the tale of inference compute. Every query processed, every agent action executed, every token generated represents ongoing expenditure that compounds relentlessly. A single ChatGPT query costs approximately $0.003 in compute. That is seemingly negligible until multiplied by 800 million weekly users, each generating multiple queries.
At five queries per user weekly, that is four billion queries, $12 million in weekly compute, $624 million annually for inference alone. Over a model’s operational lifetime, inference costs routinely exceed training costs by factors of three to fifteen. At CES in January 2026, Lenovo’s chief executive officer predicted that 80% of AI compute will be inference and only 20% training. As of March 2026, inference already accounts for over 60% of AI workloads and is projected to reach 70-85% by 2028-2030.

The economic characteristics diverge at every level. Training hardware depreciates in eighteen months. Inference hardware maintains utility for four to five years. Training serves a concentrated customer base for frontier labs. Inference serves a broadening market of millions of enterprises and consumers. Training requires the latest GPU architecture. Inference benefits from specialized silicon optimized for throughput and cost per token rather than peak performance.
Training is the arms race. Inference is the economy.
Inference Efficiency
At GTC 2026, NVIDIA CEO Jensen Huang completed a pivot that had been in the making for 18 months. His keynote focused on inference, agents, and AI factories. Data centers are factories, Huang argued. Their product is the token. Their efficiency determines the unit economics of everything built above them. The governing metric has shifted from training FLOPS to tokens produced per watt.
This pivot culminated in the introduction of NVIDIA’s Vera Rubin platform, which promises to deliver 10x the inference performance per watt compared to its Blackwell architecture. The pivot was reinforced by NVIDIA’s December 2025 deal with chip startup Groq. The deal was reported to be a $20 billion non-exclusive licensing agreement for Groq’s LPU inference technology, paired with the hiring of CEO Jonathan Ross and the bulk of Groq’s engineering team.
Groq remains operationally independent. At GTC 2026, Huang showed how the two architectures would work together: Vera Rubin handling the prefill phase of inference, and the new Groq 3 LPX rack, housing 256 LPUs, handling the decode phase where tokens are generated. The Groq integration recalled NVIDIA’s “Mellanox moment” several years ago, when it acquired the company for its networking architecture (InfiniBand, Spectrum-X Ethernet), which became cornerstones of AI cluster design. Groq’s architecture is optimized for inference, adding deterministic low-latency decoding using massive on-chip SRAM at 80 TB/s internal bandwidth, achieving 500+ tokens per second on Llama 3 70B at up to 10x the energy efficiency of GPUs.
On the silicon side, the inference landscape has fragmented in ways training never did: AWS Inferentia claims significantly better price-performance, Google’s TPUv5e offers strong cost-effective efficiency gains, AMD and a generation of startups are all targeting the inference economics that determine AI’s unit costs.
The algorithmic gains compound on top of the silicon. Mixture-of-experts architectures activate only a fraction of total parameters per query. Qwen3-Next, for example, activates 3 billion of 80 billion through ultra-sparse expert routing, achieving 10x faster inference on long contexts. Dynamic batching pushes GPU utilization from 30% to over 80%. Speculative decoding doubles token-generation speed at a fixed cost. These represent order-of-magnitude gains that compound with one another and with the silicon improvements beneath them, producing a 5-10x annual price-performance trajectory.
Stanford and Together AI researchers quantified where this trajectory leads. Their Intelligence Per Watt metric improved by a factor of 5.3 between 2023 and 2025. Local models on consumer-grade hardware answered 88.7% of single-turn reasoning queries correctly. The share of queries that edge devices can handle rose from 23.2% to 71.3%. Inference is beginning to migrate from data centers to the edge, and this trend will accelerate as devices become more capable.
The Jevons paradox operates here with particular force. This refers to the principle that increased resource efficiency drives higher total consumption. In this case, efficiency gains in inference will expand the frontier of viable workflows, which expands total consumption even as per-unit costs fall. A workflow unprofitable at $50 in agent compute becomes routine at $5. A category of work inconceivable at one price point becomes obvious at a lower one. The efficiency gains feed the demand they were designed to serve.
This has direct implications for the AGNT thesis. The orchestrator’s primary variable cost is the cost of inference tokens. Every improvement in efficiency expands the addressable market. The orchestrator that routes tasks intelligently across capability tiers (commodity models for extraction, frontier models for complex reasoning, edge devices for latency-sensitive work) achieves structurally better margins.
Whether the agentic economy becomes the deflationary force described in Part V depends on whether this efficiency trajectory continues to compound. If it does, the surplus available to orchestrators grows with every cycle. If it stalls, the transition slows. Not for want of intelligence, but because the economics simply do not work.
The Energy Constraint
Beneath the capital, the debt, the silicon, and the algorithms lies a constraint more fundamental and less tractable than any of them: Power.
The scale of the demand is unprecedented. Huang’s $1 trillion demand outlook through 2027 implies not merely more chips and racks but more electricity consumed continuously at an industrial scale. A single Vera Rubin NVL72 rack draws power at levels that would have been classified as a small industrial facility a decade ago. Leading-edge AI racks consume 130-250 kilowatts today, with projections reaching 900 kilowatts by 2027. Each hyperscaler is pursuing a one-gigawatt data center campus, a scale that draws as much electricity as a mid-sized city.
The workload itself has changed shape. A chat query resolves in 500 milliseconds. An agentic task, such as a coding audit, a research synthesis, or a multi-system workflow, takes 10 minutes to 14+ hours and runs in parallel with thousands of siblings inside a single campus. The load profile of an AI data center has converged toward that of an aluminum smelter: continuous, high-wattage, near-100% utilization, 24/7. The bursty inference workload grid planners that were modeled against have been removed. The new profile is baseload.
In addition, agentic compute has a unique memory-power overhead. To maintain state over a 14-hour + task, agents must keep massive context windows active. In 2026, hyperscalers are offloading KV caches to SSD storage to manage the memory bottleneck, but the energy required for constant data shuffling remains a high hidden cost. Anthropic has published research on “context engineering”. This refers to compaction, structured note-taking, and multi-agent architectures designed to address “context rot” in long-horizon agents. These techniques reduce the memory-power overhead of maintaining state across extended tasks and indirectly ease the underlying power constraint.
The power infrastructure to support these facilities does not exist in most locations where they are being planned. Grid interconnection timelines run three to five years in the United States, longer in Europe. Permitting for new transmission lines routinely takes a decade.
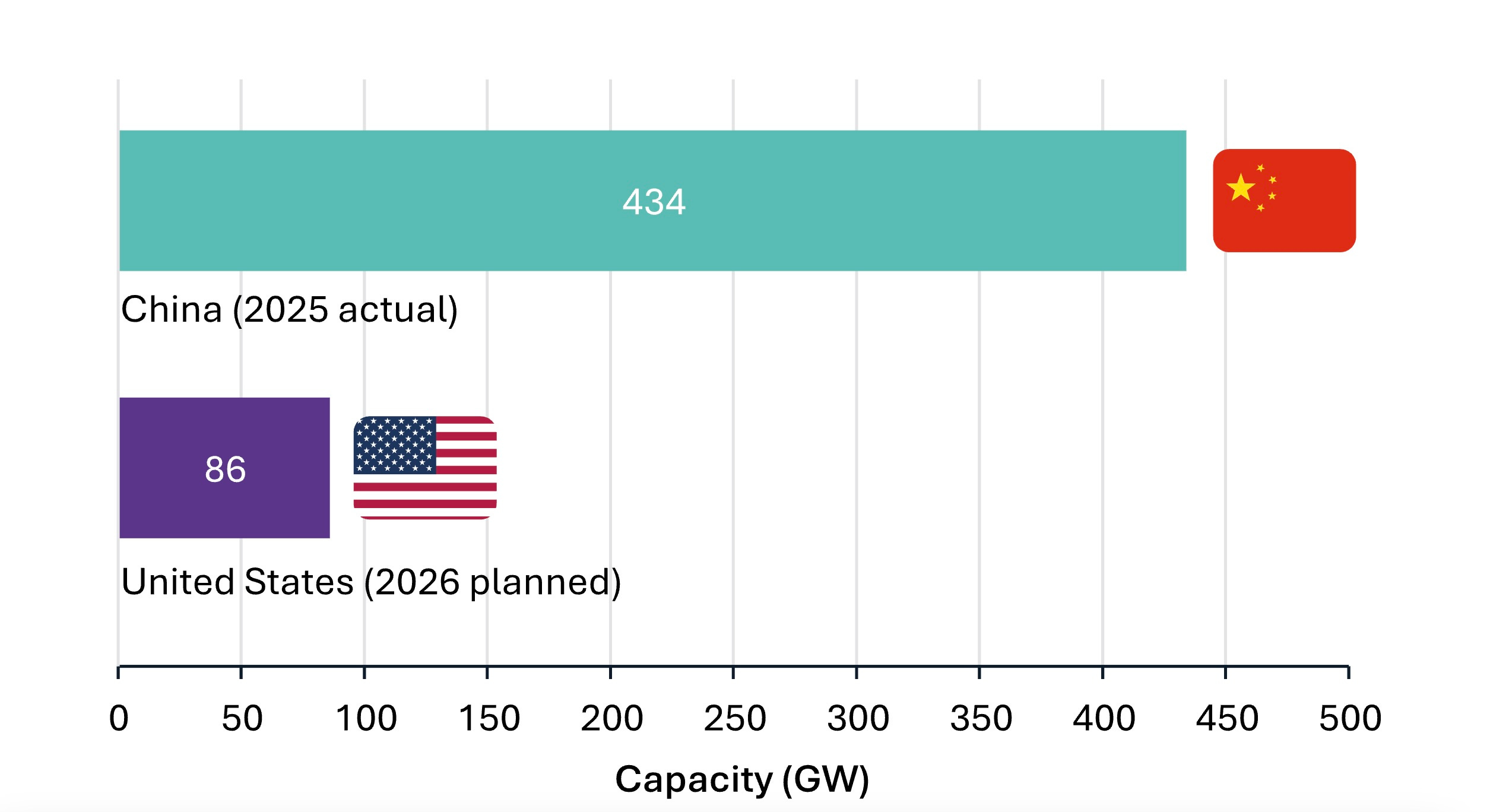
The US is on track to add a record 86 GW of utility-scale generation in 2026: 51% solar, 28% batteries, 14% wind. Useful firm power near data-center hubs is a fraction of the headline figure. In PJM, the single most important AI interconnection, utility large-load commitments now exceed accredited generation capacity by a factor of 3. China, in contrast, added 434 GW in 2025 alone and is co-locating compute with generation in the renewables-rich West. This is not a cyclical shortfall; the US closes with Capex. Rather, it is a profound infrastructure divergence, one that could constitute a Single Point of Failure of the Agentic Era, i.e., the specific vulnerability that, if left unresolved, constrains the entire transition regardless of how fast models improve or how much capital flows into AI. In the framework we introduced in 2025, an SPOF is the component of a system whose failure compromises the entire structure.
Nuclear is, as of 2026, the only carbon-free source with the density for AI-scale loads, and the scramble for it since 2024 is no longer directional. It is the infrastructure. Microsoft underwrote the restart of Three Mile Island via a 20-year PPA with Constellation (835 MW, 2027-2028). Amazon bought Talen’s Susquehanna campus and is developing SMRs with X-Energy and Dominion. Google signed with Kairos (500 MW SMR fleet), Fervo Geothermal, Oklo, and Vistra, making it the largest corporate purchaser of nuclear energy in US history. Sam Altman backed Oklo (2.6% stake, former chair, co-founder of the SPAC that took Oklo public). xAI stood up 200+ MW of on-site gas turbines in Memphis in under a year. Stargate Abilene is architected as a 1+ GW behind-the-meter campus. Together, these constitute a coordinated admission that the public grid cannot deliver what agentic compute needs within the required timeline. Hyperscalers are no longer interconnecting to the grid: they are becoming utilities.
The constraint sharpens as the workload shifts from training to inference. Training runs are episodic. A frontier model trains for weeks in a concentrated burst, then stops. Inference is continuous. Every agent action, every orchestrated workflow, every token consumes power indefinitely, at a load that scales with agent populations.
As the mix shifts, the demand profile moves from periodic spikes to sustained baseload: precisely the pattern that stresses grids most acutely, because it requires always-on generation rather than peak-shaving.
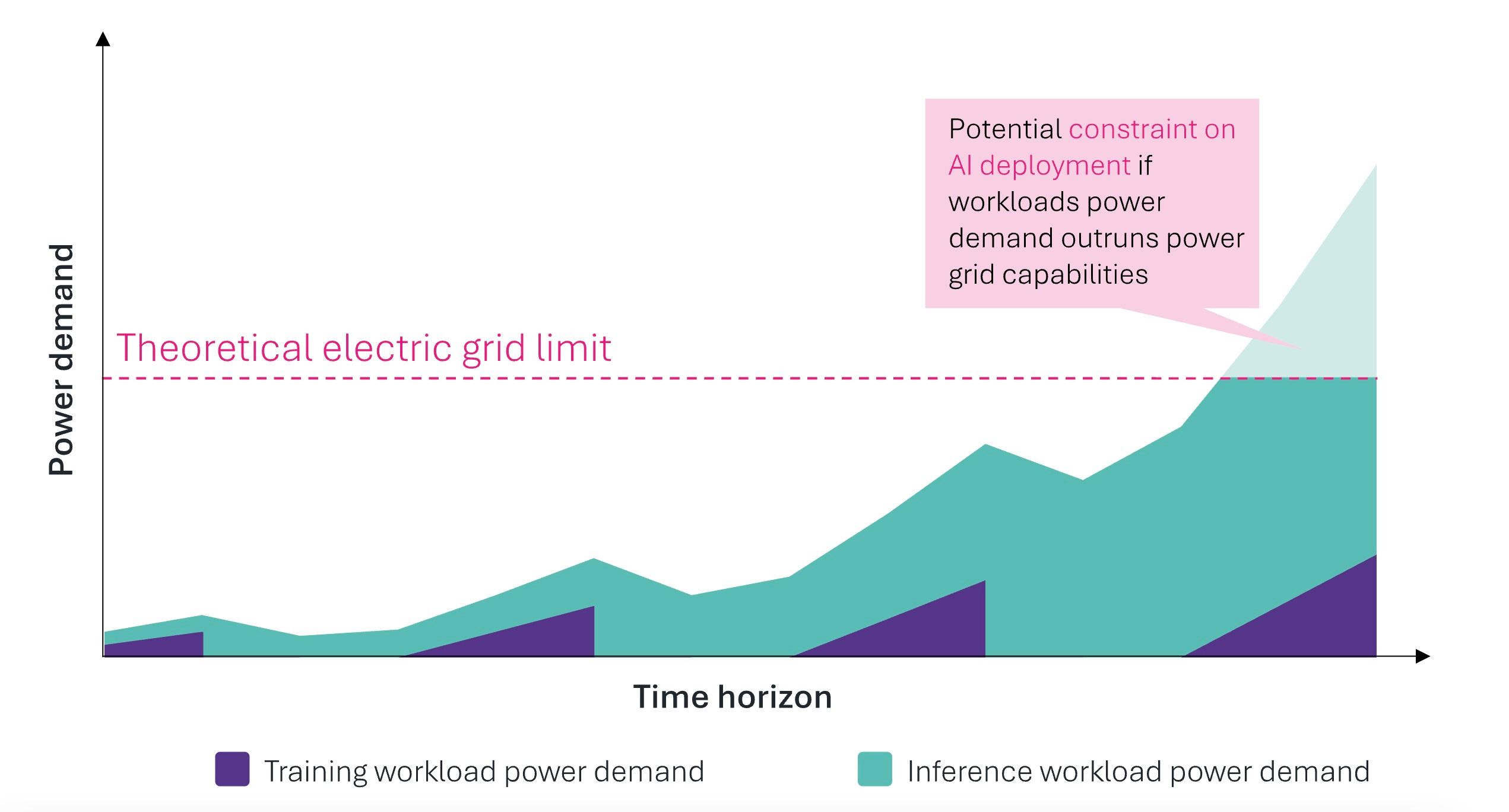
The efficiency gains partially offset this. As noted before, Jevons in this respect operates at an industrial scale: cheaper inference makes more workflows viable, expanding total demand even as per-unit consumption falls. Hyperscalers that secure power early through long-term agreements, on-site generation, or strategic locations near abundant clean energy gain compounding advantages. The value of a data center is increasingly determined not by the GPUs it houses, but by the megawatts it can draw.
For the AGNT thesis, energy introduces a temporal variable into every projection. The Inference Economy expands at a rate bounded by the availability of power, regardless of demand or capital. The orchestrators of Parts III to V will find their ability to scale agentic workflows ultimately limited by whether the infrastructure they depend on has the electricity to operate.
The direction is not in question. The speed is. Watts, not weights, now govern the pace of the transition. The pace, as the Two Scenarios in Chapter 18 will argue, is what separates deflationary growth from demand destruction.
The Agentic Cloud

There is a final condition that completes the picture. It is architectural rather than financial or physical. The cloud was built for a different era. The SaaS-era cloud was designed for stateless applications, ephemeral compute, hub-and-spoke networking, and consumption-based pricing. An enterprise spins up a virtual machine, runs a workload, and shuts it down. Two decades of perfecting that pattern. It is the wrong pattern for what comes next.
The agentic systems of Chapter 5 generate workloads that differ in every dimension. Every MCP connection, every A2A coordination, every persistent memory retrieval, every multi-step workflow is an inference operation. An agent booking a flight generates 50,000 tokens across research, comparison, booking, and confirmation. This compares to just 500 for a chat query. Agentic workloads multiply token consumption 10x to 100x.
But the difference is not merely volume. Agents are stateful. They maintain persistent memory and workflow state across sessions, requiring considerably more memory than traditional workloads. The three-tier memory architecture of Chapter 5 requires infrastructure that preserves state, not infrastructure designed to forget:
Agents coordinate laterally. They communicate peer-to-peer through MCP and A2A, requiring sub-100ms latency and dedicated bandwidth between coordinating agents. The topology must evolve from a centralized switchboard toward a mesh.
Agents generate explosive storage demands. Vector databases typically experience 10x data expansion, with total storage reaching 30x the original data after indexing and context persistence.
Agents require a different economic model. Pricing must be tied to task completion and outcomes rather than compute hours consumed, which demands infrastructure instrumented for metrics that traditional cloud monitoring was never designed to capture.
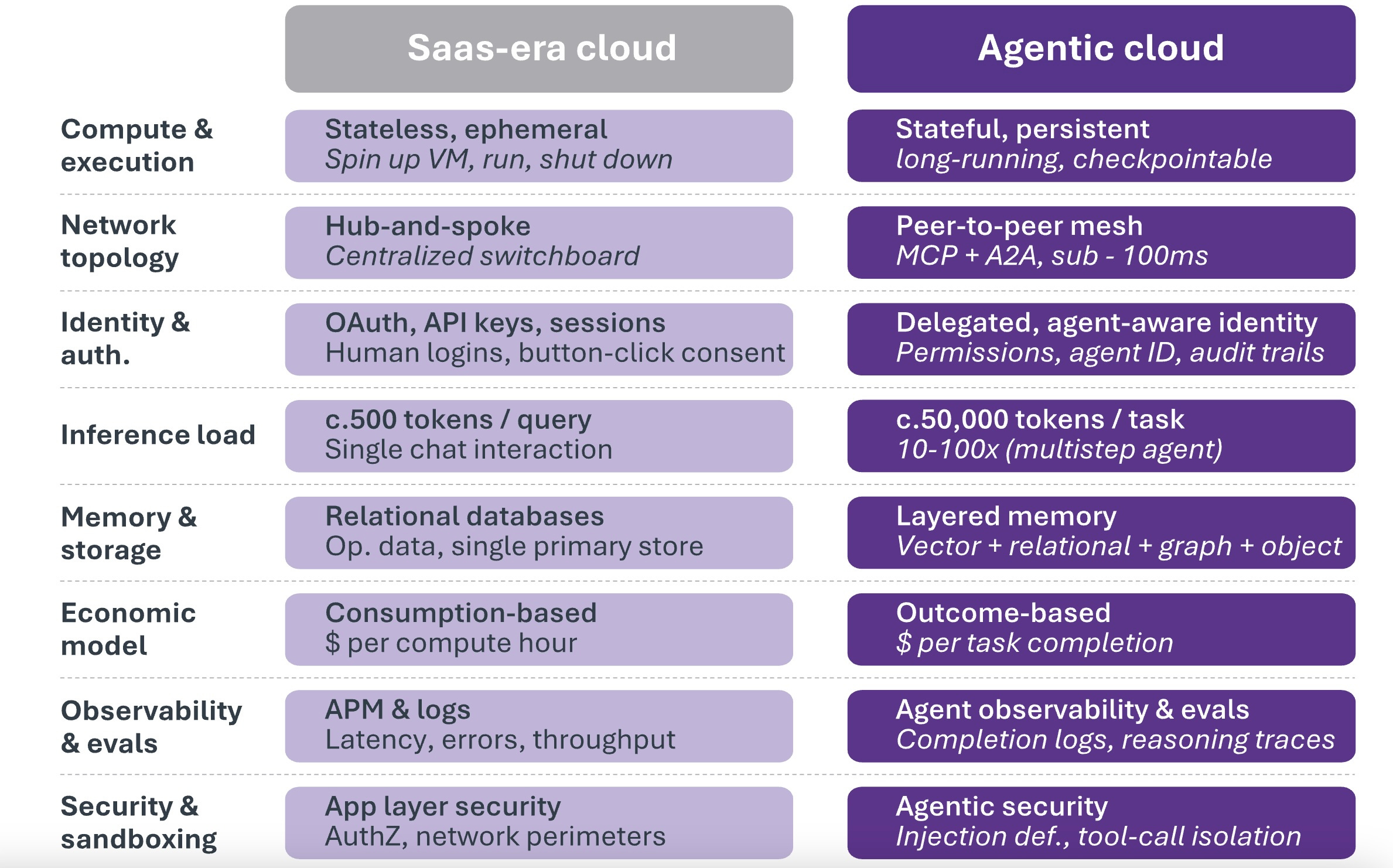
These requirements point toward a new infrastructure category: the agentic cloud. Three categories of providers are positioned to build it.
The hyperscalers hold the deepest structural advantages: custom silicon, enterprise relationships built over decades, and captive internal demand for inference. Google’s Search, YouTube, Gmail, and Maps are continuously consuming inference, providing a substantial utilization floor regardless of external demand. Their challenge is that hundreds of billions in existing infrastructure were designed for the SaaS era. The organizational complexity of serving legacy and agentic workloads simultaneously is real, and scale alone does not resolve it.
The neoclouds proved something important: that AI workloads demand fundamentally different compute from general-purpose clouds. CoreWeave and other AI-specialist clouds have demonstrated MFU improvements of 15-30% over hyperscaler baselines (e.g., CoreWeave’s 49.2% MFU on H100 training runs vs MosaicML’s 41.85% baseline, per CoreWeave’s published benchmarks). Industry training MFU typically sits in the 35-55% range, depending on hardware generation, software stack, and workload. But the neocloud window is narrowing. Their core design is stateless, single-tenant, and hub-and-spoke. This served training-centric workloads well. It is less suited to what agentic systems demand.
The emergent agentic clouds are purpose-built. Daytona Cloud achieves sub-90ms sandbox creation for stateful agent workflows. Others target observability for multi-agent systems, optimization for coordination-intensive workloads, and outcome-based resource allocation. They carry no architectural debt. They lack scale. They are building for the incoming workload.
The model providers see the same opening. Anthropic’s Claude Managed Agents, launched in April 2026, offers the full production stack for agentic workloads as a managed service: sandboxed execution, state persistence, tool orchestration, error recovery, and multi-agent coordination. It runs on existing cloud infrastructure, but the developer never touches it. Anthropic abstracts the cloud into a substrate and bills by the session-hour.
The orchestrator’s variable cost is the cost of inference tokens. Hardware efficiency sets the floor for the cost of producing a token. The agentic cloud determines the cost of serving that token within a coordinated, stateful, production-grade workflow. The companies that optimize for both will set the economic foundation for everything built on top of them.
The Substrate Must Evolve
The AI infrastructure being built in 2026 is the largest private capital deployment in history. It is transforming Big Tech’s balance sheets from capital-light to capital-intensive. It is financed through structures of increasing ambition, from conventional bonds to century paper to securitized GPU assets. And it was committed under assumptions about training workloads that the migration toward inference is already reshaping.
The metamorphosis is substantial but navigable. Inference efficiency is compounding at a pace that makes the unit economics of the agentic economy more favorable with each quarter. The energy constraint governs speed, not direction. And the cloud is beginning, unevenly, incompletely, but perceptibly, to evolve toward the stateful, coordination-grade architecture that agentic workloads demand.
The intelligence is sufficient. The agents are in production. The infrastructure is scaling and starting to change shape. What determines whether specific companies, sectors, and workflows successfully cross is the subject of Part III.
The views and opinions expressed in this publication are those of the author alone and are based on publicly available information. The expressed views and opinions do not constitute investment advice, a solicitation, or a recommendation to buy or sell any security or financial instrument. The author may hold positions in the securities of companies mentioned. Certain companies referenced may be current or former clients of, or counterparties to, the author or affiliated entities; such relationships will be disclosed where applicable. Past performance is not indicative of future results. To the fullest extent permitted by applicable law, the author does not accept any liability for any loss or damage arising from reliance on this content. Readers should conduct their own independent due diligence and consult a qualified financial advisor before making any investment decision.