
The Substrate Goes Open
As orchestration collapses into open weights and deployment costs drop ~7x, the “Intelligence Moat” is challenged. From model performance to orchestration, the frontier is moving to another layer.


Six major model releases over ten days reordered the AI landscape: Anthropic’s Opus 4.7 and OpenAI’s GPT-5.5 traded blows with Kimi K2.6, DeepSeek V4 Pro/Flash, Qwen3.6-27B, and Xiaomi MiMo. The closed labs still hold the apex on reliability and frontier iteration. The substrate has decisively gone open.
The cost-quality ratio has inverted. DeepSeek V4 Pro is roughly one-seventh the blended cost of GPT-5.5 and one-sixth of Claude Opus 4.7, an order-of-magnitude shift in deployment economics.
Kimi K2.6 shipped swarm orchestration trained into the weights via Parallel-Agent Reinforcement Learning, not implemented in the runtime above them. Capabilities that lived in the proprietary Harness layer twelve months ago are now native to open-weight models.
The runtime harness still matters more than ever for production reliability, auditability, and compliance. But it matters now for operational rigor rather than capability scarcity. The engineering tax that protects it is collapsing.
The moat has moved. As intelligence converges and commoditizes, value migrates to the orchestrator: the entity that holds operational context, workflow ownership, and the relationship between humans and work. The AGNT Manifesto, to be published on Thursday, builds the investment framework for that migration.
A flurry of major new model releases over the past ten days has scrambled the AI landscape once again.
Anthropic opened the cycle on April 16 with Claude Opus 4.7. Moonshot answered on April 20 with Kimi K2.6, the first open-weight model to top the Artificial Analysis Intelligence Index. Two days later, Alibaba’s Qwen team released Qwen3.6-27B, and Xiaomi released MiMo-V2.5-Pro, the latter tying with K2.6 at the top of the open-weight tier, though it remains API-only for now. OpenAI shipped GPT-5.5 on April 23. DeepSeek closed the cycle on April 24 with V4 Pro and V4 Flash, both Mixture-of-Experts models under the MIT license, that bring the lab within striking distance of the frontier.
Fifteen months ago, when DeepSeek-R1 arrived at one-fiftieth the cost of OpenAI’s o1, I argued that what looked like a Chinese price cut was a punctuated-equilibrium event: long periods of stability interrupted by rapid, structural change. R1 commoditized intelligence. What just shipped does something more consequential: it commoditizes the layer above it. The cost of training a frontier model fell in 2025. The cost of deploying autonomous agents in production has fallen over the past 10 days.
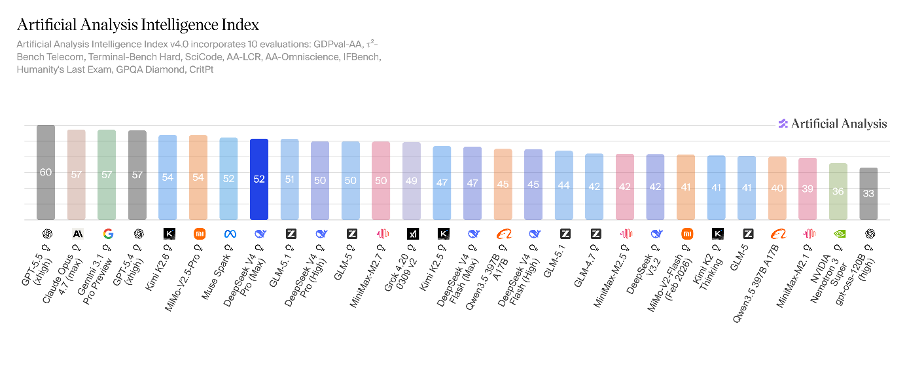
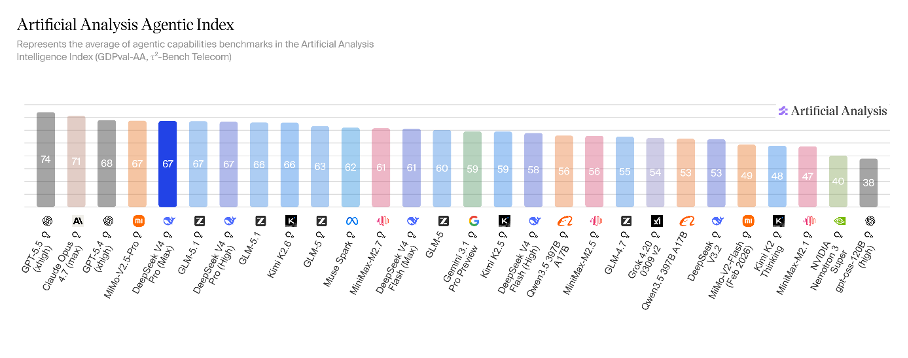
The standard reading of these releases is that “open-source caught up.” That is correct on the leaderboard and misleading on the substance. Open-weight models have not closed the gap on long-horizon agentic reliability, multimodal grounding depth, or instruction-following discipline under adversarial conditions. The Stanford AI Index 2026 reports that the closed-versus-open Chatbot Arena gap partially reopened to roughly three points by March 2026, after compressing from eight in early 2024 to under two a year later. The closed labs still hold the apex. But two things are now simultaneously true, and their interaction is the structural news of the cycle.
The first is that open-weight models are absorbing the architectural innovations that defined the closed agentic stack twelve months ago: long-context inference at economically viable pricing, multi-agent coordination trained into the weights rather than implemented in the runtime above them. The Harness is the proprietary runtime layer that I argued last spring was the durable moat in the Agentic Era, and that I described more recently as Anthropic’s Metalayer. This is being absorbed, capability by capability, into the open-weight substrate.
The second is that the cost-quality ratio has inverted. DeepSeek V4 Pro is priced at $1.74 per million input tokens and $3.48 per million output. That’s roughly one-seventh the blended cost of GPT-5.5 ($5 input, $30 output) and about one-sixth that of Claude Opus 4.7 ($5 input, $25 output).
The frontier advantage still belongs to the closed labs. The economic advantage increasingly does not.
Together, these shifts undermine the labs’ defensibility in raw intelligence and compress the window in which they can convert it into platform durability. Anthropic and OpenAI are now forced to compete on harness quality and orchestration sophistication at exactly the moment those capabilities are being absorbed into the open-weight substrate.
What actually shipped
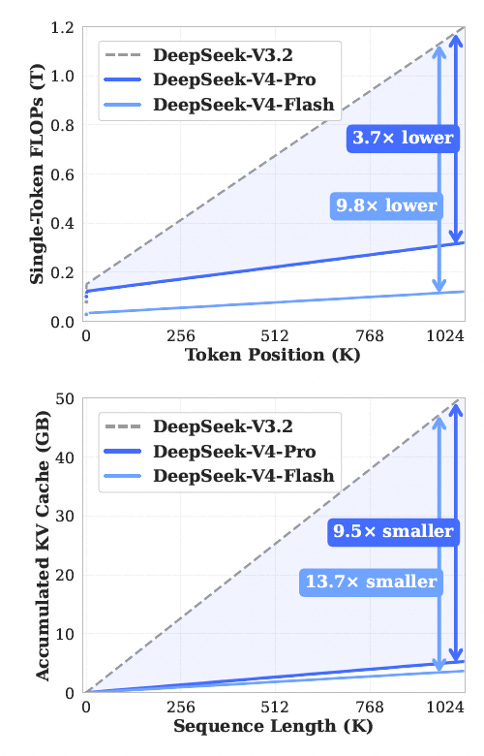
First, the long-awaited DeepSeek V4. V4 Pro is a 1.6-trillion-parameter Mixture-of-Experts with 49 billion active per token. Flash is the lighter sibling, with 284 billion total and 13 billion active. Both ship a one-million-token context window, a number already available in proprietary models. What is new is that DeepSeek makes it economically viable at open-weight pricing, by shipping two memory-side innovations: Compressed Sparse Attention and Heavily Compressed Attention. These build on V3.2’s DeepSeek Sparse Attention and solve the KV-cache memory wall that previously made long context prohibitive on commodity hardware. Both models are released under the MIT license with no field-of-use restrictions. Note that inference is slower than Western frontier models on a per-token basis, and the model remains text-only. DeepSeek’s research team has signaled multimodal is in flight, but it is not there yet.
Then, Kimi K2.6. This is the more important release for the agentic argument. One trillion total parameters, 32 billion active per token, with a 384-expert MoE topology of which eight are active, and one is shared per token. Native multimodal input - text, image, video - outputting text. A 256,000-token context window, smaller than DeepSeek V4 but more than enough for the median production agent workload. The architectural step that matters is what Moonshot continues to bake into the weights since K2.5 in January: Parallel-Agent Reinforcement Learning, a training regime that produces an orchestrator agent capable of decomposing tasks, instantiating frozen specialist sub-agents, and coordinating concurrent execution at scale: up to three hundred sub-agents and four thousand coordinated steps per session in K2.6.
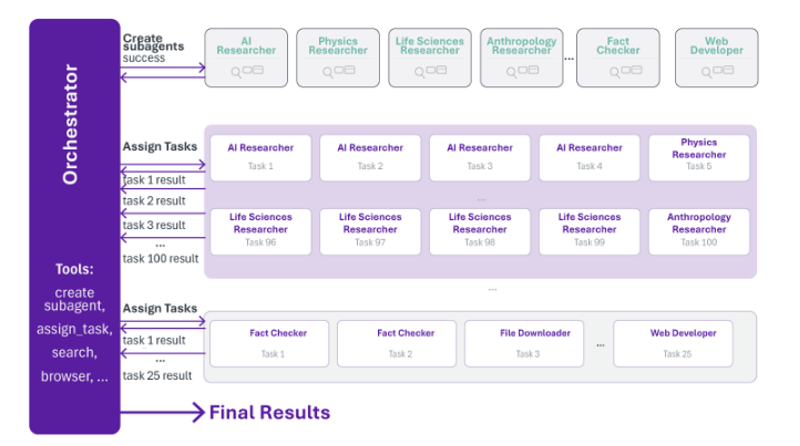
These are capabilities that, until recently, lived in the Harness layer above the model and are now increasingly trained into the model itself.
Last, Qwen3.6-27B and Xiaomi MiMo-V2.5-Pro. Qwen3.6-27B is a dense 27-billion-parameter model. Every token routes through every parameter under a clean Apache 2.0 license. It scores 46 on the Artificial Analysis Intelligence Index, far above where dense open models sat eighteen months ago, and it is sized to run on a high-end M-series MacBook Pro or a Mac Studio. That makes it the local development loop primitive of the moment. Xiaomi MiMo-V2.5-Pro currently ties with Kimi K2.6 at the top of the AAII open-weight composite at 54, but ships closed-weight via API only. Xiaomi has promised to release an open-source version eventually, but has not committed to a date.
The trajectory of these releases matters a lot here.
Benchmark convergence is not agentic parity. The cost-quality ratio is.
Benchmark convergence is real, but it is not agentic parity. On Chatbot Arena, the gap between proprietary frontier models and their open-weight alternatives compressed from roughly eight points in early 2024 to under two by early 2025, then partially reopened to about three points by March 2026 as the closed labs accelerated. That is the convergence. The frontier-closed labs have not stopped pulling away at the very edge of capability. They have stopped pulling away enough to defend their per-token pricing on the dimensions that matter for production agents.
Benchmarks like MMLU and AAII measure capability on bounded tasks. Agentic deployment is bounded by something different: long-horizon reliability under tool use, coherent state across a thousand calls, adherence to system prompts under adversarial inputs, and graceful recovery from tool failures rather than the unbounded looping that killed AutoGPT in 2023. On these axes, the closed frontier still leads by margins that matter. On Meta’s Gaia2 benchmark, GPT-5 leads Claude 4 Sonnet by eight points on adaptability under ambiguity. On τ-bench, even the strongest models succeed on fewer than 25 percent of retail agent tasks at pass-at-eight. As Princeton’s Narayanan and Kapoor noted in March: “AI agents are getting more capable, but reliability is not improving at the same pace”.
Multimodal grounding tells the same story. DeepSeek V4 is text-only; Kimi K2.6 has vision and video, but vision-grounded reasoning lags; and GPT-5.5 posted a jump on MRCR-v2 from 36.6 to 74 percent at 1 million tokens in a single generation.
Apex parity, then, is not here. UC Berkeley’s Measuring Agents in Production study, published in December, found production teams overwhelmingly default to the best-performing closed-source models regardless of inference cost.
What matters for the substrate question is narrower: sufficiency for the median agentic workload at an economic ratio that flips ROI. That ratio has inverted.
DeepSeek V4 Pro delivers near-frontier performance on long-horizon coding tasks at a fraction of GPT-5.5’s per-token output pricing. Kimi K2.6 ships orchestration in the weights at a similar discount. The cost asymmetry is 10 to nearly 100 times cheaper for inference, depending on the tier and routing. That means even a five-to-ten-per-cent quality gap flips the deployment math for most production workloads.
Domains where reliability tail risk matters more than unit economics will continue to default to the closed frontier. That includes sectors such as high-stakes legal, regulated medical, and autonomous engineering, which will continue to default to the closed frontier. But these have already absorbed the cost. The growth is in the median workload, where a model that is materially worse and fifty times cheaper would not have been built at all under closed-frontier economics.
The calibration follows. The labs hold the apex. The economy will increasingly run on the substrate. Both are simultaneously true. The substrate is what gets built on, not what gets paid for. As of this cycle, the substrate is open.
The architectural shift behind the cost ratio
The cost-quality ratio is the headline. The underlying architectural shift determines whether the ratio holds.
Two innovations matter most: long context at economically viable open-weight pricing, and the migration of orchestration capabilities from the runtime layer into the model itself.
Below the one-million-token threshold, agentic coding is assisted editing. The model helps modify files one window at a time. The human provides the architectural overview, and the work is stitched across context boundaries. Above the threshold, with reliable retrieval, the model holds an entire codebase in working memory, including every file, every dependency, every test, and every configuration. That is a different thing. The model no longer operates on fragments. It understands the system. It refactors across files without losing coherence. It traces failures end-to-end without decomposing them into disconnected steps.
That is autonomous engineering, and until this cycle, it was available only on Claude Opus 4.x and Gemini 3 Pro at frontier prices.
With DeepSeek V4 and CSA/HCA making a million-token context economically viable on commodity hardware, it becomes a primitive that any startup can deploy. The economic threshold for putting coding agents into production drops by an order of magnitude. Adoption stops flowing through enterprise sales cycles and starts flowing through developers from the bottom up.
There is a second-order effect: every long-context interaction becomes in-context learning. The agent that has processed a thousand pull requests for a specific repository develops institutional knowledge that no general-purpose model can synthesize from training data. The system becomes the training ground.
The second shift is more consequential for the labs. Kimi K2.5, released in late January, was the first open-weight foundation model with built-in swarm orchestration: a Parallel-Agent Reinforcement Learning architecture that decomposes complex tasks, dynamically instantiates specialist agents, and coordinates their concurrent execution. K2.6 extends it with native multimodality and the higher ceilings already mentioned.
The point is where the orchestration lives. In the closed-labs’ architecture, swarm orchestration is a runtime concern. The Harness layer above the model handles task decomposition, agent instantiation, and coordination. In Moonshot’s architecture, those capabilities are trained into the weights. The orchestration is not sitting on top of the model. It is fused with it.
That distinction matters for the labs’ durable moats. Twelve months ago, the runtime moat was defensible because building a production-grade Harness required months of backend engineering, frontier-grade reliability, and a primary intelligence layer no open model could match.
Each pillar is now compromised. Long context at open-weight pricing eliminates the reliability premium for context-heavy workflows. Swarm orchestration in the weights eliminates a meaningful share of the runtime engineering. The convergence of intelligence on a uniform capability frontier eliminates the third leg.
The architectural innovations are not auxiliary to the cost story. They are what make the cost story durable.
In-weights orchestration carries its own costs. The capability trained into the model is, by construction, less observable than the capability implemented at runtime above it. Debugging is harder. Domain-specific guardrails are harder to attach. The auditability requirement that every step of a regulated workflow be reconstructable for compliance review is harder to engineer.
The point is not that in-weights orchestration replaces the Harness. The engineering moat, in terms of the difficulty of building one well, is no longer load-bearing on capabilities that the open model itself cannot replicate. The Harness still matters. The reasons it matters have shifted from capability scarcity to operational rigor.
The labs under pressure, and the moat that keeps moving
Twelve months ago, I argued that orchestration is the durable moat in the Agentic Era. I defined this to include the runtime layer that coordinates tool use, manages state, and decomposes goals.
Two weeks ago, I described how Anthropic operationalized that thesis with Claude Managed Agents, launched on April 8: a managed runtime billed by the session-hour at $0.08 above standard token rates, with sandboxed execution, checkpointing, credential vaulting, and end-to-end tracing. I termed the product category the Metalayer.
Both arguments need to be sharpened in light of these announcements.
A year ago, the Harness was a moat because primary-grade reliability, frontier intelligence, and months of backend engineering were each scarce. This cycle compromises each one. Kimi K2.6 carries swarm orchestration in the weights. DeepSeek V4 delivers the long-context capability that was the load-bearing assumption of the closed Harness. Both ship under near-permissive licenses. The runtime advantages of Managed Agents include multi-agent coordination, persistent state, and tool orchestration. These are increasingly available as native model behaviors in customer-controlled environments at a fraction of the cost.
The Harness is still a moat. It is just no longer the moat. It is being squeezed from two sides.
From below, open-weight models are absorbing orchestration capabilities that the labs spent two years building as proprietary infrastructure. Every quarter, the gap between what the closed Harness can do and what an open model in a customer’s VPC can do narrows. The Metalayer’s pricing logic is that the runtime adds enough value to justify a tax above the token layer. However, that depends on the runtime’s defensibility. As that defensibility erodes, the tax becomes contestable.
From above, the entities such as insurers, banks, carriers, industrials, and software incumbents that hold operational context are under no obligation to route through a lab’s Harness when an open-weight equivalent ships every quarter. They can build their own runtime against an open model and own the orchestration outright.
Every operational context holder that opts for open weights becomes a Harness that the lab cannot tax.
This is why the labs cannot stand still. Anthropic moved at an extraordinary cadence across the first quarter: Cowork, multiple model upgrades, Managed Agents, the $30 billion raise at $380 billion, and the Amazon five-gigawatt compute deal. OpenAI shipped GPT-5.3-Codex, 5.4, and then a fully retrained 5.5. These are platform plays. They demonstrate how the labs are climbing further out of the model layer, deeper into the runtime, and reaching for the workflow itself. The alternative is to become a very expensive API in a market where APIs are converging towards free.
The two structural vulnerabilities we identified last summer during a private assessment of Anthropic and OpenAI were open-source compression and the compute trap. These are no longer future risks. They are present-tense pressures.
DeepSeek V4 and Kimi K2.6 just shortened the timer on the first. The flywheel runs faster, the rented ground gets thinner, and the urgency to convert the runtime moat into a workflow moat compounds. The platform multiples that justify $380-billion-class valuations (and up to $1 trillion per the latest data for Anthropic) now require winning the workflow layer against incumbents whose operational context the labs cannot replicate by shipping a better model.
The wave of open-weight releases from Chinese labs is not only a pricing problem for OpenAI and Anthropic. It is the visible expression of a strategic divergence. Hugging Face’s State of Open Source Spring 2026 report shows that Chinese-developed models accounted for 41 percent of platform downloads through February, ahead of US-developed models at 36.5 percent. Singapore’s AI Singapore initiative built its sovereign regional model on Qwen. African enterprises adopt DeepSeek at two to four times the rate of other regions. Permissive licensing via Apache 2.0 from Qwen, MIT from DeepSeek, and modified MIT from Moonshot is the policy lever, not just the pricing lever, reducing dependence on a small number of US providers for sovereign and regulated workloads.
xAI framed Grok-1 around the goal of maximum truth-seeking with broad access. In practice, the cadence of permissive releases now belongs to China, and OpenAI’s gpt-oss release in August 2025 was a response rather than a lead. The substrate going open is broadening the surface of who can build with frontier-class intelligence. That’s good for the field, even where it is uncomfortable for incumbents.
The labs are running uphill on ground that is moving faster than they are climbing. A year ago, orchestration was the moat. Today, orchestration is the contested terrain. Tomorrow, the moat sits one layer further out, where operational context lives, workflow ownership accrues, and intent originates.
The moat keeps moving. The framework has to move with it.
Where value migrates
DeepSeek V4 and Kimi K2.6 are not a story about open-source nationalism, MoE architectures, or the SaaS selloff. They are the visible expression of a structural shift. The substrate of the Agentic Era, already cheap and ubiquitous, has gone open. The architectural innovations that defined the closed stack twelve months ago are arriving in open weights faster than the labs can replace them.
As intelligence converges and commoditizes, value migrates to the orchestrator, to whoever coordinates the abundant resource and captures the surplus released by abundance. The pattern repeats across every major economic transition: electricity, compute, cloud.
Twelve months ago, the orchestrator looked like the Harness. This cycle proves the Harness itself is being absorbed into the substrate alongside the model. Value cannot stop there. It continues until it reaches the layer that cannot be commoditized: where intent originates, where context accumulates, and where work is directed. Operational context. Workflow ownership. The relationship between the human and the work itself, not any tool inside it.
The companies that win the Agentic Era will not be the ones that built the best model, nor the ones that built the best Harness. They will be the ones who reorganized with intelligence at the core of their workflows and applied irreplaceable operational context to the work agents now perform.
The Manifesto I am releasing this week builds the investment framework for that migration. Orchestration Economics identifies the structural position that captures the surplus when intelligence commoditizes: AGNT.
The substrate just went open. Thursday, we map who builds on it, who gets built around, and where the surplus actually accrues.