
The Red Queen's Race: OpenAI, Anthropic, and the Frontier AI Treadmill They Must Escape
The market is trying to price the winner of a race that by design has none. The victor won't be the fastest runner, but the one that escapes. GLM-5.2 and Fuku are proof. The AI-lab IPOs are the test.


TLDR: Over the past 3 weeks, a Chinese lab (Zhipu) released a frontier model (GLM 5.2), a Japanese lab (Sakana AI) unveiled a potentially game-changing orchestration model (Fugu), Washington switched off America’s best one, SpaceX went public, and S-1s were filed by OpenAI and Anthropic for mega-IPOs planned in the fall. For two years, the closed labs survived two pressures by using one to escape the other: the price of inference from below and a copyable harness from the side. GLM-5.2 and Sakana’s Fugu have cut off both escape routes. As a result, the model layer has become a Red Queen’s race, the kind the biologist Leigh Van Valen named in 1973: you run flat out just to stay exactly where you are. No lead holds, because the lead is the thing that provokes the field to erase it. A race built this way has no winner. Which is what makes the three IPOs the most interesting test of the year. The market is being asked to price a finish line for a race that never ends. The money will not go to the fastest runner. It will go to whoever finds a way to escape from the race.
In Lewis Carroll‘s Through the Looking-Glass, an exasperated Alice complains to the Red Queen about having to run as fast as she can just to stay in one place. The Red Queen explained, “If you want to get somewhere else, you must run at least twice as fast as that!”
The concept of the Red Queen’s race was used by biologist Leigh Van Valen in 1973 to describe a strange finding in the fossil record: The odds that a species goes extinct hold roughly constant, however long it has already lasted. Surviving ten million years does not make the next ten any safer. What wears you down is not the weather, but the other runners. Every gain by a rival forces you to run harder just to maintain your current position.
A confluence of events in recent weeks has made it clear that the frontier model layer has become a Red Queen’s race.
Among the notable signals were the release of Fable by Anthropic, the subsequent shutdown by the U.S. government, confirmation that Anthropic and OpenAI have filed for IPOs, and the blockbuster SpaceX IPO.
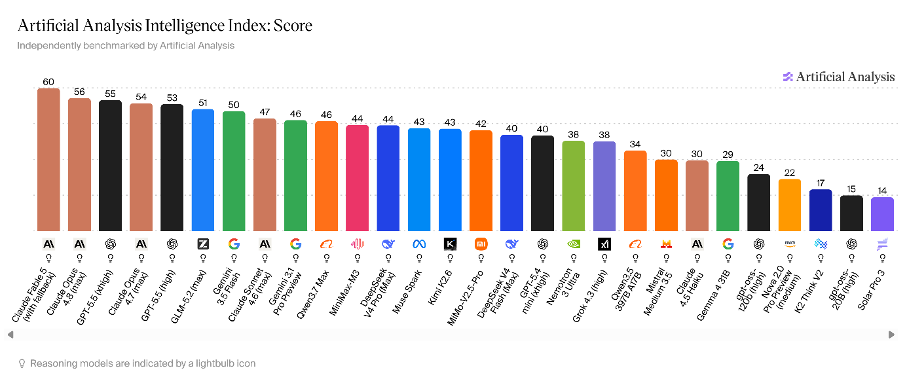
However, the true tipping point came with the release on June 13 of GLM-5.2 by the Beijing laboratory Zhipu, which, three days later, put the weights online under an MIT license, free to download, modify, and sell. On the Artificial Analysis index, GLM-5.2 is the first open model to break into the closed cluster of frontier models. And on the public coding arena, GLM-5.2 ranks second in the world behind only Fable, making it effectively the most powerful model publicly available.
This goes beyond the clean, open-source commoditization narrative because GLM compresses the race in two critical ways. Not only is it an MIT-licensed model from a Chinese lab that sits within striking distance of the frontier, but it has begun replicating the agentic harnesses that were supposed to extend the frontier labs’ advantage and has done all of this at a fraction of the cost in a short window of time.
A second shock followed this week from Japanese lab Sakana AI, which unveiled Fugu, which it claimed matches the performance of Mythos and Fable by “dynamically coordinating and orchestrating a diverse pool of powerful models“. Essentially, one of the co-authors of the original Transformers paper, which laid the foundation for the LLM era, has helped build a model whose sole purpose during training is orchestration. This provides perhaps the most straightforward evidence of my core thesis: In the Agentic Era, value migrates away from the model layer and is captured by the orchestrator.
Last week, I explored the implications of these events for frontier models through the framework in which intelligence commoditizes itself through diffusion. Frontier models create new capabilities; open-source and enterprises absorb them; orchestration captures value. The key risk exposed by the Fable export ban was that governments can interrupt that diffusion process.
GLM-5.2 and Fugu (a closed model) demonstrate that diffusion is becoming so rapid and so effective that the window for frontier labs to capture any value from the capabilities they create is closing even faster than expected. As the Red Queen warned, they are going to have to run even faster to maintain what little advantage they have in a world where every advantage is rapidly copied and therefore cannot produce durable economic rents.
As this compression intensifies, trillions of dollars in value hinge on the following questions: Can any of these players escape the Red Queen race? And if so, what are the possible scenarios?
The question is no longer whether frontier labs can build a lead. It is whether they can convert that lead into a durable moat before diffusion erases it.
The model and the harness
GLM-5.2 is the best open model ever built. It is also a fast follower. Fugu is something else altogether, an orchestration model that takes a new approach to building the harness.
Let’s take a moment to understand each one.
GLM-5.2 is a mixture-of-experts model with 744 billion parameters and about forty billion firing per token and a million-token context. Zhipu has shipped a new flagship roughly every two months since February. On the Artificial Analysis index, it scores 51. It ranks first among open models, behind only the leading models from Anthropic and OpenAI, and, as I emphasized previously, it is the first open model to break into the closed cluster rather than trailing the pack. On GDPval-AA, one of the few independently measured real-world agentic benchmarks, it performs roughly at the same level as GPT-5.5. And on the public coding arena, it ranks second globally behind only Fable, a model so powerful that Washington has blocked it from the market.
The benchmarks should be treated cautiously. Epoch’s independent evaluation remains pending, and open models tend to perform better on public benchmarks than private ones. Still, the narrow claim is remarkable enough: an MIT-licensed model from a Chinese company on the U.S. Entity List now sits within the frontier cluster.
Fugu is not a foundation model in the conventional sense. Instead, it is a reinforcement-trained coordinator that routes tasks dynamically across multiple frontier models, assigning different systems to different stages of a workflow. The intelligence comes not from a single model but from orchestration itself.
Sakana AI’s Fugu is a multi-agent orchestration system built around a small reinforcement-trained coordinator that dynamically routes work across a pool of frontier models, assigning different models to different roles and subtasks. Drawing on Sakana’s ICLR 2026 Trinity and Conductor research, Fugu claims to learn coordination strategies automatically rather than relying on hard-coded workflows, allowing it to assemble temporary teams of AI agents, decompose problems, verify outputs, and recursively refine solutions.
Sakana argues that this learned orchestration produces state-of-the-art performance on demanding benchmarks such as SWE-Pro, GPQA-D, and LiveCodeBench, in some cases exceeding the performance of any individual frontier model while exposing the entire system through a single OpenAI-compatible API endpoint.
The model compression
GLM and Fugu matter not because they break the capability. More specifically, they break the economic relationship between capability and value capture.
For the past year, frontier labs have been squeezed by two pressures. The first came from below: the collapse in the cost of intelligence. The second came from the side: the growing realization that the harness surrounding a model may matter more than the model itself. The harness includes memory, orchestration, tools, monitoring, and workflow management.
Until recently, these pressures arrived separately, and that separation was the labs’ defense. When model capability diffused, the answer was the harness. The weights may be cheap, but the product was the agentic system wrapped around them. When competitors copied the harness, the answer was the model. The scaffolding may be reproducible, but the frontier remained scarce.
GLM-5.2 and Fugu potentially challenge both defenses simultaneously.
In the case of GLM-5.2, it compresses the capability gap. Not because it surpasses the frontier, but because it narrows the distance to a handful of benchmark points while delivering inference at a fraction of the cost.
GLM-5.2 costs roughly $1.40 and $4.40 per million input and output tokens, against $5 and $30 for GPT-5.5. And it is free, open, and from a company on the United States Entity List since January 2025, and trained on Huawei chips instead of Nvidia's.
This means that GLM-5.2 is five to eight times cheaper on output than the closed frontier, and you can read the squeeze on the incumbents’ own sheets, where OpenAI cut its o3 line by some eighty percent and leans on discounts to keep its flagship competitive.
Within that average is an important split. For a fixed level of capability, the price of commodity inference falls about fifty times a year. The price of reaching the frontier may fall by five to ten. The two curves pull apart, and at the very tip, they cross.
The same week GLM-5.2 went out for free, Anthropic launched Fable at $10 and $50 per million tokens. That’s double the price of the model it replaced. The newest capability did not get cheaper. It remained a premium.
So, the fight has left the per-token price, which is going to zero, and moved to efficiency itself: the compute you burn per piece of useful work.
Here, GLM-5.2 is honest about the cost of its own intelligence. It spends 43k tokens to complete a task, whereas MiniMax, for example, spends 24k. It is the least token-efficient open model in its class, and it buys its capability with that spend. Efficiency is the new battleground, and it is not free. MiniMax learned that in public: its first model used linear attention to cheapen long context; its second reverted to full attention because the cheap trick broke multi-hop reasoning; its third found a sparser path that selects blocks instead of dropping them.
There is an inflection hiding in that hunt. A year ago, near-frontier capability could not be self-hosted at any consumer price. It lived in a data center, or it did not exist. Now it runs on a workstation: GLM-5.2, squeezed to 240 gigabytes at two bits, three to nine tokens per second, maintaining about 80% of its accuracy.
This is not the edge. Nobody is running it on a phone, and it is slow and degraded when they do. But the floor fell through a threshold in twelve months. Epoch titled its own finding “frontier AI performance becomes accessible on consumer hardware within a year.” A capability you can hold on your own machine cannot be switched off by a letter at 5:21 on a Friday.
That is the inflection. Not that intelligence moved to the edge. That it stopped needing anyone’s permission.
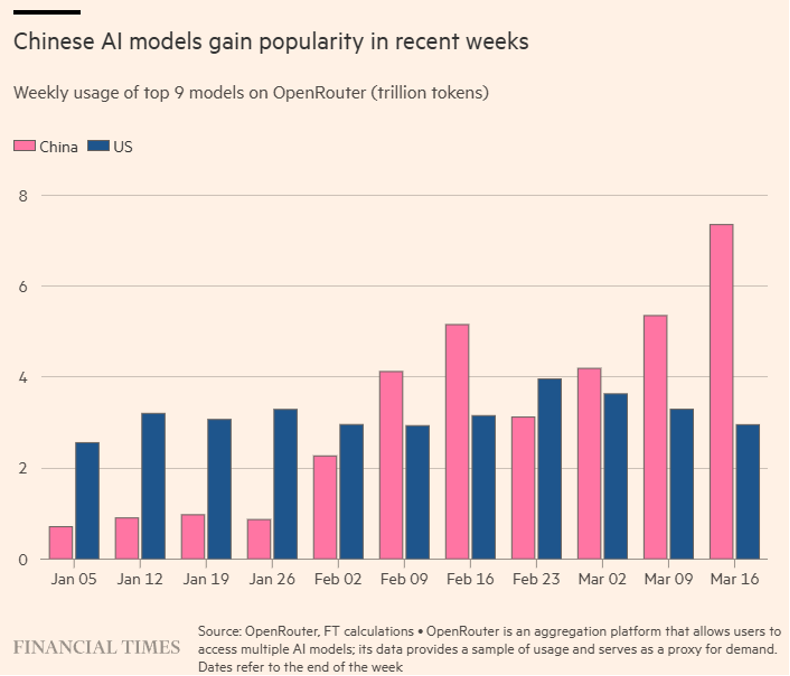
Which is why the price of inference has become geopolitical. The United States treats the frontier as a weapon: entity-listed, export-controlled, and switched off. China treats open weights as a way to drive the price of everything around its own chips and cloud toward zero; the analysts call it commoditizing the complement, and it is working, with Chinese open models reaching nearly a third of global usage in some weeks.
And Microsoft, OpenAI’s largest shareholder, holding a stake reported near $135 billion, a founder of the very group set up to stop Chinese labs from copying Western ones, is weighing whether to route part of Copilot to DeepSeek to save money.
The significance is not that intelligence became better. It is that near-frontier intelligence became dramatically cheaper, openly available, and increasingly difficult to restrict. I have called this the substrate going open, and tracked it since DeepSeek first hit in early 2025. The proof is already here in miniature: the lead the labs spent a generation building was matched in days and barred in hours
The harness compression
GLM and Fugu also compress the harness gap. What an enterprise actually buys when it buys an agent is not the weights but the scaffolding around them: the loop that calls the tools, the memory that holds across sessions, the orchestration of sub-agents, the guardrails inside the loop, and the monitoring that lets a long job finish alone.
Claude Code became the archetype of the agentic era by transforming a model into a worker through orchestration, memory, tool use, and long-horizon task execution. And for two years, it was a real edge, because the best agentic work needed a frontier model and a private harness, and only the labs had both.
Yet Zhipu’s GLM Coding Plan reproduces much of the same functionality and sells it at a fraction of the cost in a market where Claude itself is unavailable. Fugu is a bit harder to evaluate, and there remains some debate about its costs as developers dig into its practical strengths and weaknesses.
Still, the significance is not that Fugu proves orchestration is commoditized. It does not. If anything, the launch demonstrates how valuable orchestration has become. The significance is that a capability many assumed would belong only to the frontier labs is now being offered by an independent company built around coordination rather than model ownership.
The pattern should feel familiar. First, the model diffuses. Now, even the coordination layer begins to diffuse. Whether Fugu succeeds commercially is almost beside the point. Its existence suggests that each time the industry discovers a new source of advantage, competitors quickly begin reproducing it at a higher level.
In this case, the harness was never impossible to copy. It was simply protected by the fact that only frontier labs possessed both the best models and the best scaffolding. Once open models, and now “orchestration models” move within striking distance of the frontier, that protection weakens.
This is why GLM and Fugu matter. In biology, a species survives one predator by trading against another. It cannot survive both at the same time, because the move that answers one costs it on the other.
That is the labs’ position.
The harness was the answer when the model got cheap: the weights are free, but our scaffolding is the product. The model was the answer when the price war closed in: they are cheaper, but we are smarter. Each escape was the door to the other room.
GLM-5.2 and Fugu shut both doors.
4 escape scenarios
The faster the frontier runs, the faster the chasers chase.
When Anthropic shipped Fable, it raised the bar. It also showed every rival exactly where to aim. The open frontier closes the gap by copying the closed one directly via distillation. Yes, there are anti-distillation rules and export controls in place to prevent this. It’s the reason Anthropic accused DeepSeek, Moonshot, and MiniMax this winter of siphoning millions of exchanges out of Claude through tens of thousands of fake accounts. (Which they deny, of course).
But the mechanism is real. It is why I have argued for a year that the frontier and the open substrate are two stages of one process, not two sides of one war.
All of that running, but no durable advantage at the model level. Add it up across the field, and it produces stasis, paid for at enormous cost.
So, where does the money go, if not to the fastest runner? It goes to the contestant who finds a way to escape the race, or at least redefine it. Think Google in search. NVIDIA in AI chips. ASML in lithography.
In this case, I see four ways out.
Scenario 1: Use the model as a doorway to a consumer you then own. No company is feeling the spending compression more than MiniMax. Our review of it landed on the Queen’s own line: you run this fast just to stay in place. MiniMax is genuinely near-frontier - its M3 is a sparse-attention mixture of 230 billion parameters that claims a twentieth of the per-token compute at long context, scoring 44 on the same index where GLM scores 51 - and it has shipped three flagship models in twelve months to stay there. The market paid for the story. It doubled on its first day in January, then fell roughly half from its spring high, and still trades at a steep multiple on $79 million of revenue, growing 159 percent, against a quarter-billion-dollar loss. None of the capabilities is a moat.
MiniMax is a price-taker in a Chinese market already in a race to zero. Squeezed between free open peers above - DeepSeek, Qwen, GLM - and its own backers below, Alibaba and Tencent, who ship rival models and to whom MiniMax pays a rising rent for compute.
The one thing it owns that lasts is not the model: it is the consumer franchise - 236 million users on Talkie and Hailuo, where the video app earns roughly $56 a paying user against the companion app’s $5, and more than 70% of revenue comes from outside China. A lab with frontier-grade coding whose only durable asset is a chatbot people talk to for the company.
A narrow door, a crowded one, but a door.
Scenario 2: The second is sovereignty, and it has the same problem in a different shape. You cannot download a jurisdiction. Mistral is reportedly raising a new round toward a €20 billion valuation - nearly double its mark nine months earlier - on roughly $0.4B of recurring revenue. But a model is not sovereignty if it runs on someone else’s cloud — a point Arthur Mensch makes himself: you can build the most transparent model in the world, but if the infrastructure beneath it belongs to someone else, the claim is only half-true.
So, Mistral is moving up. It is building 200 megawatts of European compute, starting with 13,800 Nvidia chips outside Paris, backed by an $830 million loan and €2.1 billion of state money, and it bought the serverless platform Koyeb to own the stack down to the metal. Sovereignty as a model is a marketing line. Sovereignty as owned infrastructure is a door-narrow, open only where the law forces it, but real.
Scenario 3: The third is the one I have argued for most, and I still believe it: orchestration. But it is being challenged, and the challenge is precise, so let me be precise back. My thesis was never that the scaffolding is the moat. The harness is defensible but contestable; it was always the outer ring, the Orchestration Layer, that I called the moat - the place where intelligence meets the customer’s intent, where decades of operational context live, where the workflow itself learns. That ring still holds, and the question here is how the AI labs move beyond the harness to command workflows in the enterprise with concrete business outcomes: Cowork and its plugins as an early example, Claude Design as another. What open weights kill is the ring beneath it. Strip a harness to its parts - the loop, the tools, the memory plumbing - and it is software running on weights anyone can now download, and software copies. That is what “anyone can build it“ means, and GLM-5.2’s discount clone of Claude Code is what it looks like.
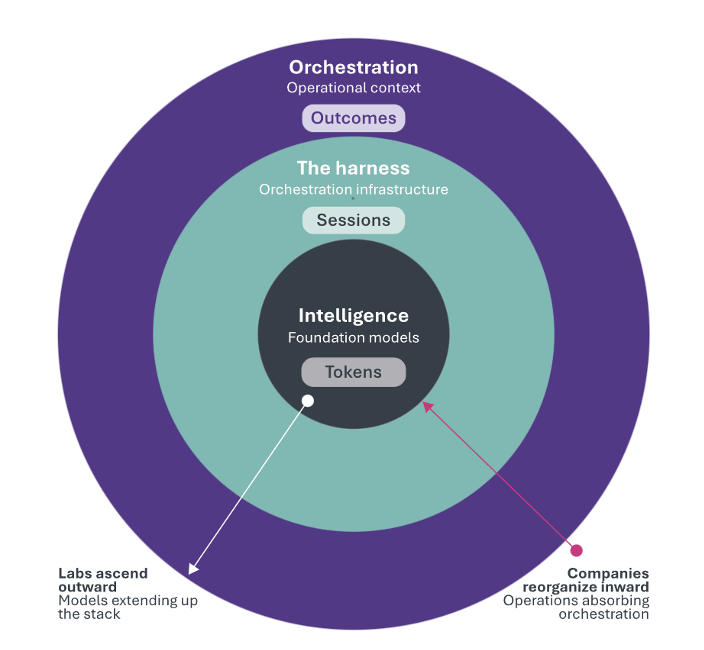
The race does not stay at the model layer. It climbs into the scaffolding.
So, the moat survives, but it has to move up. The part that was code dies. The part that is context - the customer’s own data, the proximity to intent, the workflow the system has learned - lives, because no lab can reach it and no license can copy it.
Orchestration as scaffolding is a trap. Orchestration as context is still the prize. The only question is how much higher it has to climb before the labs, racing up from below, catch it.
Scenario 4: The fourth is the only one physics protects. You can fork a harness, clone an app, and route around a model. You cannot download a data center, copy a power grid, or open-source a leading-edge fab. Compute, energy, silicon - they are not software, so the race cannot touch them. The memory trade is perhaps the clearest example here of a chokepoint that benefits whoever wins the race. Compute is another perfect example. While proprietary compute is not at the core of SpaceX's AI valuation per the S-1, it clearly gives SpaceX a key advantage in the race. The landlord does not care who wins the race. He collects rent from everyone still running it. As the race climbs and eats the software exits one by one, the money drains through the single door; it cannot follow anyone through. The landlord’s.
No winner by design
The market is being asked to price a finish line in a race that may not have one.
The story embedded in today’s valuations is consolidation: that AI, like most software markets, ends as an oligopoly of two or three dominant labs with durable pricing power. That assumption lies beneath OpenAI’s trillion-dollar valuation and Anthropic’s comparable ambitions.
But the events of June suggest a different possibility. The frontier remains real. Fable proved that. Yet GLM-5.2 demonstrated how quickly frontier capability can diffuse, while Fugu hints that even parts of the orchestration layer may become reproducible. The question is no longer whether the leading labs can build a lead. It is whether they can convert that lead into a durable moat before diffusion erases it.
The IPO filings already read less like an escape from the race than evidence of it. OpenAI is growing rapidly, but costs and revenue continue to rise together. The Information recently reported that OpenAI has burned $3.7B in Q1. Anthropic faces the same pressure while confronting a new reality: the most valuable capabilities may also be the most vulnerable to regulation. Both companies are running faster than ever. Neither has yet shown it can stop running.
SpaceX stands apart for a simple reason. It is not selling a position on the leaderboard. It is selling infrastructure. Compute, power, launch capacity, satellites, and physical assets that software competition cannot replicate. Investors are not underwriting a model. They are underwriting ownership of the terrain on which the race is being run.
That distinction matters because the lesson of the past few weeks is not that the frontier has stopped mattering. It is that frontier capability alone may no longer be sufficient to capture enduring value.
The assets most likely to escape the Red Queen dynamic share a common characteristic: they are difficult to copy. Infrastructure. Energy. Distribution. Sovereignty. Customer relationships. Proprietary operational context. Everything else faces relentless competitive compression.
The Red Queen’s insight was never that running is futile. It was that running faster does not guarantee survival. Every advantage invites a response. Every lead creates the conditions for its own erosion.
The question raised by this year’s IPOs is therefore not who wins the race.
It is those who find a way to escape it.
The views and opinions expressed here are those of the author alone and are based on publicly available information. They do not constitute investment advice, a solicitation, or a recommendation to buy or sell any security or financial instrument. The author may hold positions in the securities of companies mentioned and maintains no current position in Anthropic, OpenAI, Mistral, or Sakana AI discussed. Past performance is not indicative of future results. Readers should conduct their own independent due diligence and consult a qualified financial advisor before making any investment decision.